Как работает поисковик Яндекс — схемы и описания алгоритмов работы
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Интернет — просто охренеть какая огромная штука. И в нем есть все. Общение с друзьями? Вот, пожалуйста — Facebook. Фотоальбом — в Instagram. Купить дачу? У меня уже есть «Веселый фермер». А энциклопедией давно пользовались? Зачем, ведь есть поисковики, которые знают все. И сегодня мне бы хотелось отдать должное этим чудо-сервисам. А точнее рассказать вам о том, как работает Яндекс поиск.
Помните Гермиону из саги о Гарри Поттере? Как вы думаете: почему она была такой сверхэрудированной всезнайкой? Правильно, потому что постоянно ходила где-то читала про всякие зелья, изучала разные заклинания, допытывалась до учителей по всем непонятным моментам. В общем, делала все, чтобы расширить свою базу знаний. Точно так же работает Яндекс поисковик. Еще до того, как вы задали ему вопрос, он уже кое-что узнал про вашу тему и сохранил себе в копилочку.
Как формируется поисковая база Яндекса
Пауки всемирной паутины
Поисковик Яндекс знает несколько триллионов урлов. И каждый день он изучает по паре миллиардов из них. Делают это специальные роботы-пауки, краулеры. Они заходят на страницу, анализируют содержимое, делают копию и отправляют на сервер. А затем уходят по ссылкам на другие страницы. Так происходит знакомство поисковика с сайтом. Далее следует этап индексикации.
Если произвести нехитрые математические расчеты, то можно выявить, что пауки Яндекса обойдут все известные страницы приблизительно за 2 года. Но это будет неверно, так как количество урлов постоянно увеличивается
=> работа по созданию поисковой базы бесконечна.
Индексикация
Определение индекса сайта — это процесс добавления всей важной информации о странице в базу поисковика. То есть определяется язык, формируются данные об отдельных словах и вытаскиваются все ссылки исходящие на другие страницы. Кроме того у Yandex есть специальный инструмент, который называется логи Яндекса. Он изучает, как пользователь ведет себя в выдаче: на что кликает, а на что не кликает. Опираясь на все полученные параметры и задается поисковый индекс сайта.
Логи Яндекса широко применяются не только при индексикации, но и при ранжировании.
Составление поисковой базы
Поисковые индексы, полученные в ходе предыдущего этапа, отправляются в поисковую базу. У Яндекс поиска она функционирует на программной платформе мапредьюс YT. Здесь данные превращаются файлы и «остаются жить».
Суммарный объем данных YT приблизительно 50 петабайт = 51 200ТБ.
У поисковой базы данных есть еженедельное обновление — апдейт. Это тот момент, когда поисковый робот Яндекса, накачав определенное количество файлов и рассчитав для них все необходимые характеристики, принимает решение, что можно добавить эту информацию в поиск.
Согласно статистическим данным Игоря Ашманова — специалиста по поисковым системам в интернете, полнота поисковой базы у Яндекса (красные на графике) в несколько раз выше, чем у их ближайшего конкурента Google (черные).
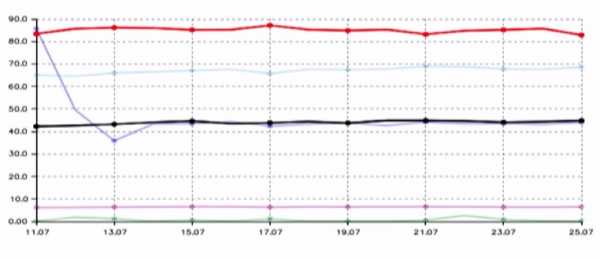
Пока индекс — времязатратный и протекает комплексно сразу для большого количества данных. Поэтому у Яндекса есть специальный быстрый контур, который может добавлять и доносить до пользователя отдельные, срочные файлы. Ну, например, новости в реальном времени.
Как работает сам Яндекс поиск
Любой запрос в поисковой системе Яндекс проходит по следующей схеме.
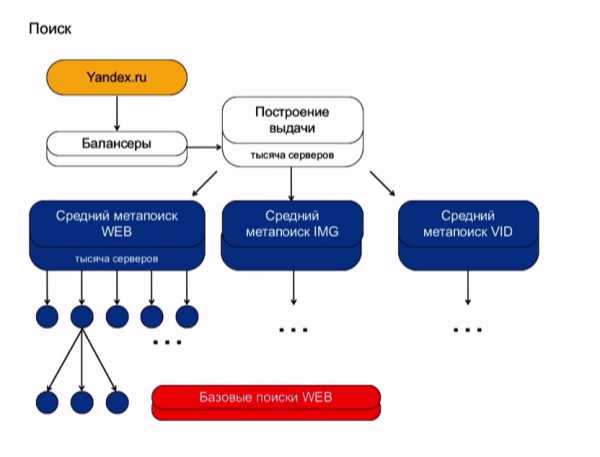
Балансеры — это машины, которые агрегируют выдачу.
Построение выдачи формируется из результатов трех средних метапоисков. Поясню, что это значит. В выдаче вы видите результаты запроса по страницам, картинкам и видео. Происходит это потому, что ваш запрос проходит по трем разным индексам. И по ним он спускается в самую-самую глубь поисковой базы, разделенную на несколько тысяч кусков. Этот процесс обозначается, как поисковая кластеризация.
Работа поискового кластера состоит из функционирования более миллиона экземпляров различных программ. Они выполняют всяческого рода задачи, у них разные системные требования и всем им нужно где-то «жить». Поэтому поисковая кластеризация занимает еще и огроменное количество компьютерного железного хостинга.
Для хранения и передачи всех программ и данных к ним Яндекс использует внутренний торрент-трекер. Число раздач на нем больше, чем на крупнейшем в мире пиратском трекере The Pirate Bay.
Вернемся к результатам выдачи.
В поисковую выдачу попадают наиболее релевантные, соответствующие поисковому запросу документы. Дальше происходит ранжирование — упорядочивание результатов поиска. Проходит оно с помощью специальной формулы. Чтобы порядок результатов каждый раз был качественным, актуальным и максимально релевантным разработчики Яндекса придумали одну очень крутую штуку.
Матрикснет — метод машинного обучения, с помощью которого строится формула ранжирования Яндекс. Он постоянно модернизирует эту схему: выстраивает комбинации, добавляет и убирает факторы, выставляет коэффициенты. Другая важная характеристика этого метода — возможность индивидуальной настройки формулы ранжирования для узкопрофильных категорий запросов. То есть для отдельных запросов, например, про кино или компьютерные игры, можно улучшить качество поиска. При этом ранжирование по остальным классам запросов не ухудшится.
Первая формула ранжирования Яндекса составляла примерно 10 байт. На сегодняшний момент — около 100 мегабайт.
Задача поисковика не просто находить иголки в сеновалах, но и определять самые острые из них. И самое удивительное то, как работает Яндекс поиск. Результат выдается за доли секунд. Десять первых наиболее релевантных запросов — как правило, это все, что нужно пользователю. Если в этих запросах мы не находим то, что искали, то мы пробуем или другой запрос, или меняем поисковик. Но рано или поздно: «Найдется все!»
Скриншоты взяты из лекции Петра Попова.
icon by Arthur Shlain
semantica.in
Как работает поисковая система Яндекс
 Добрый день, уважаемые читатели моего сео блога. Эта статья о том, как работает поисковая система Яндекс, какие она использует технологии и алгоритмы для ранжирования сайтов, что делает для подготовки ответа пользователям. Многие знают, что этот флагман русского поиска задает тон в Рунете, владеет самой большой базой данных в Евразии, оперирует контентом более чем миллиарда страниц, знает ответ на любой вопрос. По данным Liveinternet за август 2012 года, доля Яндекса в России составляет 60,5%. Месячная аудитория портала — 48,9 миллионов человек. Но самое главное, для нас, блоггеров в том, как поисковая система получает наши запросы, как их обрабатывает и какой результат получается на выходе. С одной стороны, зная и понимая эту информацию, нам проще пользоваться всеми ресурсами Яндекса, с другой стороны — легче продвигать наши блоги. Поэтому, предлагаю вместе со мной посмотреть самые важные технологии лучшей поисковой системы Рунета.
Добрый день, уважаемые читатели моего сео блога. Эта статья о том, как работает поисковая система Яндекс, какие она использует технологии и алгоритмы для ранжирования сайтов, что делает для подготовки ответа пользователям. Многие знают, что этот флагман русского поиска задает тон в Рунете, владеет самой большой базой данных в Евразии, оперирует контентом более чем миллиарда страниц, знает ответ на любой вопрос. По данным Liveinternet за август 2012 года, доля Яндекса в России составляет 60,5%. Месячная аудитория портала — 48,9 миллионов человек. Но самое главное, для нас, блоггеров в том, как поисковая система получает наши запросы, как их обрабатывает и какой результат получается на выходе. С одной стороны, зная и понимая эту информацию, нам проще пользоваться всеми ресурсами Яндекса, с другой стороны — легче продвигать наши блоги. Поэтому, предлагаю вместе со мной посмотреть самые важные технологии лучшей поисковой системы Рунета.
Когда пользователь Интернета впервые хочет обратиться за информацией к поисковой системе, у него может возникнуть один вопрос: «Как происходит поиск?» Но когда он ее получает, зачастую этот вопрос меняется на другой: «Почему так быстро?» И действительно, почему поиск какого-нибудь файла на компьютере занимает 20 секунд, а результат запроса со всей сети компьютеров по всему миру появляется через секунду? Самое интересное, что первых два вопроса (как происходит поиск и почему 1 секунда) могут быть в одном ответе — поисковая система заранее подготовилась к запросу пользователя.
Чтобы понять принцип работы Яндекса, как и другой поисковой системы, проведем аналогию с телефонным справочником. Чтобы найти любой номер телефона, необходимо знать фамилию абонента и любой поиск занимает в таком случае максимум минуту, потому что все страницы справочника — это сплошной алфавитный указатель. А вот представьте себе, если бы поиск шел по другому варианту, где номера телефонов были бы упорядочены по самим номерам. После таких поисков, которые уже затянутся на более продолжительное время, цифры перед глазами искавшего будут еще очень долго стоять. 🙂
Так и поисковая система раскладывает всю информацию из Интернета в удобном для нее виде. И самое главное, все эти данные заранее кладутся в ее справочник, до прихода посетителя со своими запросами. То есть, когда мы задаем Яндексу вопрос, он уже знает наш ответ. И выдает нам его через секунду. Но эта секунда включает в себя ряд важнейших процессов, которые мы сейчас подробно рассмотрим.
Индексирование Интернета
Яндекс ру собирает в сети Интернет всю информацию, до которой может дотянутся. С помощью специального оборудования, отсматривается весь контент, в том числе и изображения по визуальным параметрам. Занимается таким сбором поисковая машина, а сам процесс сбора и подготовки данных называется индексированием. В основу такой машины входит компьютерная система, которая по другому именуется поисковый робот. Он регулярно обходит проиндексированные сайты, проверяет их на наличие нового контента, а также сканирует Интернет в поисках удаленных страниц. Если он обнаруживает, что какая-то такая страница больше не существует или закрыта от индексирования, то удаляет ее из поиска.
Как поисковый робот находит новые сайты? Во-первых, благодаря ссылкам с других сайтов. Потому что если на новый веб-ресурс поставлена ссылка с уже проиндексированного сайта, то при следующем посещении второго, робот зайдет в гости и к первому. Во-вторых, в Вебмастере поисковика Яндекс есть чудесный сервис, в народе называемый «аддурилка» (от словосочетания на английском языке -addurl — добавить адрес). В нем можно внести адрес Вашего нового сайта, который через некоторое время посетит поисковый робот. В-третьих, с помощью специальной программы «Яндекс.Бар» отслеживается посещение пользователей, которые ею пользуются. Соответственно, если человек попал на новый веб-ресурс, в скором времени там появится и робот.
Все ли страницы попадают в поиск? Каждый день индексируются миллионы страниц. Среди них есть страницы различного качества, в которых может содержатся разная информация — от уникального контента до сплошного мусора. Причем, как говорит статистика, мусора в Интернете намного больше. Каждый документ поисковый робот анализирует с помощью специальных алгоритмов. Он определяет, есть ли у него какая-нибудь полезная информация, сможет ли он ответить на запрос пользователя. Если нет, то такие страницы не берут «в космонавты», если же да, то он включается в поиск.
После того, как робот посетил страницу и определил ее полезность, она появляется в хранилище поисковой машины. Здесь идет разбор любого документа до самых основ, как говорят мастера автоцентра — до винтиков. Страница очищается от html-разметки, чистый текст проходит полную инвентаризацию — подсчитывается местоположение каждого слова. В таком разобранном виде страница превращается в таблицу с цифрами и буквами, которую по другому называют индексом. Теперь, чтобы не случилось с веб-ресурсом, в котором содержится эта страница, ее последняя копия всегда есть в поиске. Даже если сайт уже не существует, слепки его документов еще некоторое время хранятся в Интернете.
Каждый индекс вместе с данными о типах документов, кодировке, языке вместе с копиями составляют поисковую базу. Она периодически обновляется, поэтому находится на специальных серверах, с помощью которых происходит обработка запросов пользователей поисковой системы.
Как часто происходит процесс индексации? В первую очередь это зависит от типов сайтов. Веб-ресурс первого типа очень часто меняет содержимое своих страниц. То есть, когда к этим страницам каждый раз приходит поисковый робот, они каждый раз содержат другой контент. По ним ничего в следующий раз уже не получится найти, поэтому такие сайты не включаются в индекс. Второй тип сайтов — хранилища данных, на страницах которых периодически добавляются ссылки на документы для скачивания. Контент такого сайта обычно не меняется, поэтому его робот посещает крайне редко. Другие сайты зависят от частоты обновления материала. Имеется в виду следующее — чем быстрее появляется новый контент на сайте, тем чаще приходит поисковый робот. И приоритет отдается в первую очередь наиболее важным веб-ресурсам (новостной сайт на порядок важнее, чем любой блог, к примеру).
Индексирование позволяет выполнить первую функцию поисковой системы — сбор информации на новых страницах в сети Интернет. Но у Яндекса есть и вторая функция — поиск ответа на запрос пользователя в уже подготовленной поисковой базе.
к меню ↑Яндекс готовит ответ
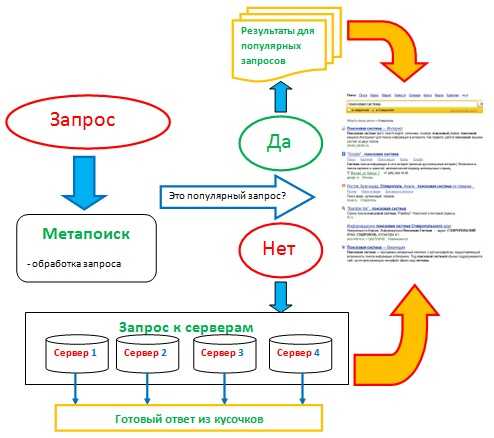
Процессом обработки запроса и выдачей релевантных ответов занимается компьютерная система «Метапоиск». Для своей работы сначала она собирает всю вводную информацию: из какого региона был осуществлен запрос, к какому классу относится, есть ли ошибки в запросе и т.д. После такой обработки метапоиск проверяет, есть ли в базе точно такие же запросы с такими же параметрами. Если ответ положительный, то система показывает пользователю заранее сохраненные результаты. Если же такого вопроса в базе не существует, метапоиск обращается поисковой базе, в которой содержатся данные индекса.
И вот здесь происходят удивительные вещи. Представьте себе, что существует один супермощный компьютер, который хранит в себе весь обработанный поисковыми роботами Интернет. Пользователь задает запрос и в ячейках памяти начинается поиск всех документов, причастных к запросу. Ответ найден и все довольны. Но возьмем другой случай, когда появляется очень много запросов, содержащих в своем теле одинаковые слова. Система должна каждый раз пройтись по одним и тем же ячейкам памяти, что может увеличить время на обработку данных в разы. Соответственно, увеличивается время, что может привести к потери пользователя — он обратится за помощью к другой поисковой системе.
Чтобы таких задержек не было, все копии в индексе сайтов распределены по разным компьютерам. После передачи запроса, метапоиск дает команду таким серверам искать свой кусочек с текстом. После чего, все данные от этих машин возвращаются в центральный компьютер, он объединяет все полученные результаты и выдает пользователю первую десятку самых лучших ответов. С такой технологией сразу убивается два зайца: в несколько раз уменьшается время поиска (ответ получается за доли секунды) и благодаря увеличению площадок дублируется информация (данные не теряются из-за внезапных поломок). Сами компьютеры с дублирующей информацией составляют дата-центр — это комната с серверами.
Когда пользователь поисковой системы задает свой запрос,в 20-ти случаях из 100 получаются неоднозначные цели в вопросе. Например, если он пишет в строке поиска слово «Наполеон», то еще не известно, какой ответ ожидает — рецепт торта или биография великого полководца. Или фраза «Братья Гримм» — сказки, фильмы, музыкальная группа. Чтобы такой возможный веер целей сузить до конкретных ответов в Яндексе существует специальная технология Спектр. Она учитывает потребности пользователей, используя статистику поисковых запросов. Из всех вопросов, заданных в Яндексе посетителями, Спектр выделяет в них различные объекты (имена людей, названия книг, модели машин и т.д.) Эти объекты распределены по некоторым категориям. На сегодняшний момент таких категорий насчитывается более 60-ти. С помощью них поисковая система имеет в своей базе разные значения слов в запросах пользователей. Интересно, что эти категории периодически проверяются (анализ происходит пару раз в неделю), что позволяет Яндексу более точно давать ответы на поставленные вопросы.
На базе технологии Спектр Яндекс организовал диалоговые подсказки. Они появляются под поисковой строкой, в которой пользователь набирает свой неоднозначный запрос. В этой строке отражены категории, к которым может относится объект вопроса. От выбора пользователем такой категории зависят дальнейшие результаты поиска.
От 15 до 30% всех пользователей поисковой системы Яндекс желают получить только местную информацию (данные того региона, в котором они живут). Например, о новых фильмах в кинотеатрах своего города. Поэтому ответ на такой запрос должен быть разным для каждого региона. В связи с этим, Яндекс использует свою технологию поиска с учетом регионов. Например, вот такие ответы могут получить жители, которые ищут репертуар фильмов в своем кинотеатре «Октябрь»:
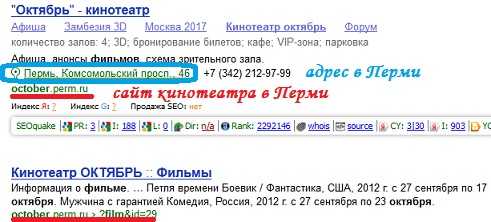
А вот такой результат получат жители города Ставрополь на тот же запрос:
Регион пользователя определяется в первую очередь по его ip-адресу. Иногда эти данные не точны, потому что ряд провайдеров могут сразу работать на несколько регионов, а значит и менять ip-адреса cвоим пользователям. В принципе, если такое случилось с Вами, Вы легко можете поменять в настройках в поисковой системе свой регион. Он указан в правом верхнем углу на странице выдачи результатов. Изменить его можно здесь.
к меню ↑Поисковая система Яндекс ру — результаты ответа
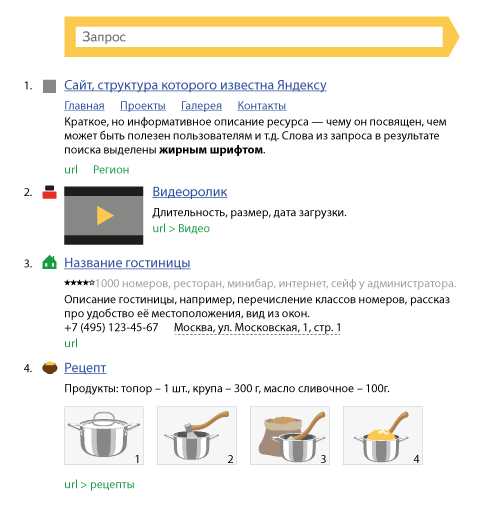
Когда Метапоиск подготовил ответ, поисковая система Яндекс должна выдать его на странице с результатами. Она представляет собой перечень ссылок на найденные документы с небольшой информацией по каждому. Задача технологии выдачи результатов — максимально информативно предоставить пользователю самые релевантные ответы. Шаблон одной такой ссылки выглядит следующим образом:
Рассмотрим эту форму результата поподробней. Для заголовка результата поиска Яндекс часто использует название заголовка страницы (то, что оптимизаторы прописывают в теге title). Если же его нет, то здесь появляются слова из названия статьи или поста. Если текст заголовка большой, поисковая система ставит в это поле его фрагмент, который больше всего релевантен к заданному запросу.
Очень редко, но бывает так, что заголовок не соответствует содержанию запроса. В таком случае Яндекс формирует свой заголовок результата поиска, используя текст в статье или посте. Он обязательно будет иметь слова запроса.
Для сниппета поисковая система использует весь текст на странице. Она выбирает все фрагменты, где присутствует ответ на запрос, а потом выбирает самый релевантный из них и вставляет в поле формы ссылки на документ. Благодаря такому подходу, грамотный оптимизатор может после увиденного сниппета его переделать, тем самым улучшив привлекательность ссылки.
Для лучшего восприятия результата на запрос пользователя, заголовки оформляются как ссылки в тексте (выделение синим цветом с подчеркиванием). Для привлекательности веб-ресурса и его узнаваемости добавляется фавикон — маленький фирменный значок сайта. Он появляется слева от текста в первой строке перед заголовком. Все слова, которые входили в запрос в ответе тоже выделены жирным шрифтом для удобства восприятия.
В последнее время в сниппет поисковая система Яндекса добавляет различную информацию, которая поможет пользователю еще быстрее и точнее найти свой ответ. К примеру, если пользователь в своем запросе пишет название какой-либо организации, то в сниппете Яндекс добавит адрес ее, контактные телефоны и ссылку на месторасположение в географических картах. Если поисковой системе знакома структура сайта, в котором есть документ с ответом для пользователя, он ее обязательно покажет. Плюс к этому Яндекс тут же может добавить в сниппет наиболее посещаемые страницы такого веб-ресурса, чтобы при желании посетитель смог сразу перейти в нужный ему раздел, экономя свое время.
Есть сниппеты, которые содержат в себе цену какого-либо товара для интернет-магазина, рейтинг отеля или ресторана в виде звездочек, другая интересная информация с различными цифрами о объектах в документах поиска. Задача такой информации — дать полный перечень данных о тех предметах или объектах, которые интересны пользователю.
В целом уже с различными примерами страница с ответами будет выглядеть так:
Ранжирование и асессоры
В задачу Яндекса входит не только поиск всех возможных вариантов ответа, но и подбор самых лучших (релевантных). Ведь пользователь не будет рыться во всех ссылках, которые ему предоставит в качестве результата поисков Яндекс. Процесс упорядочивания результатов поиска называется ранжированием. То есть именно ранжирование определяет качество предлагаемых ответов.
Есть правила, по которым Яндекс определяет релевантные страницы:
- понижение в позициях на странице с результатами ждут сайты, которые ухудшают качество поиска. Обычно это такие веб-ресурсы, владельцы которых пытаются обмануть поисковую систему. К примеру, это сайты со страницами, на которых находится бессмысленный или невидимый текст. Конечно, он видим и понятен поисковому роботу, но не посетителю, читающему этот документ. Или сайты, которые при переходе на ссылке в зоне выдачи сразу переводят пользователя совсем на другой сайт.
- не попадают в выдачу результатов или сильно понижаются в ранжировании сайты, содержащие в себе эротический контент. Это связано с тем, что часто такие веб-ресурсы используют агрессивные методы продвижения.
- зараженные вирусами сайты не понижаются в выдаче и не исключаются с результатов поиска — в этом случае пользователь информируется об опасности с помощью специального значка. Это связано с тем, что Яндекс предполагает, что на таких веб-ресурсах могут находиться важные документы по запросу посетителя поисковой системы.
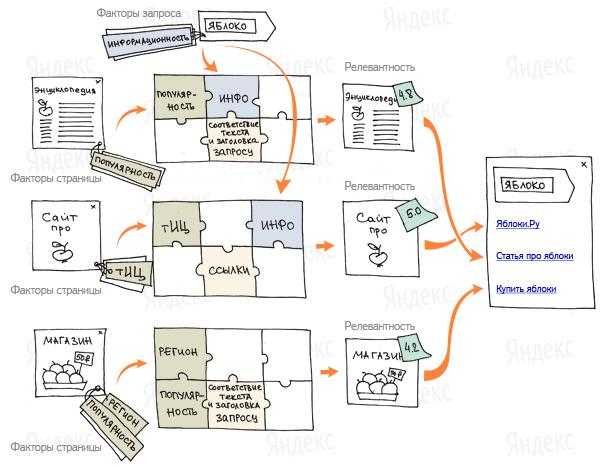
К примеру, так будет ранжировать Яндекс сайты по запросу «яблоко»:
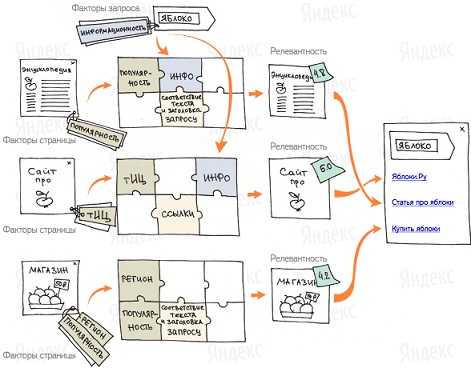
Кроме факторов ранжирования Яндекс использует специальные образцы с запросами и ответами на них, которые пользователи поисковой системы считают самыми подходящими. Такие образцы ни одна машина не сможет сделать на данный момент — это прерогатива человека. В Яндексе такие специалисты называются асессорами. В их задачу входит полный анализ всех документов поиска и оценка ответов на заданные запросы. Они выбирают лучшие ответы и составляют специальную обучающую выборку. В ней поисковая машина видит зависимость между релевантными страницами и их свойствами. Имея такую информацию Яндекс может подобрать для каждого запроса оптимальную формулу ранжирования. Метод построения такой формулы называется Матрикснет. Плюс этой системы в том, что она устойчива к переобучению, что позволяет учитывать большое количество факторов ранжирования, не увеличивая количество ненужных оценок и закономерностей.
к меню ↑Интересная статистика Яндекса
В завершении моего поста хочу показать вам интересную статистику, собранную поисковой системой Яндекса в процессе своей работы.
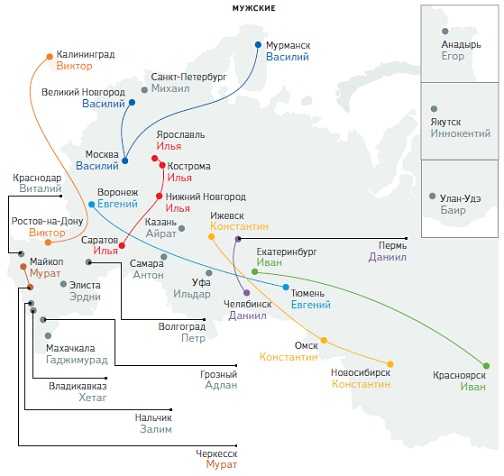
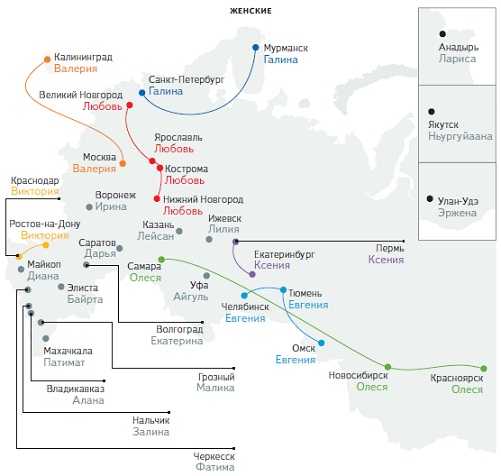
1. Популярность личных имён в России и российских городах (данные взяты из учетных записей блоггеров и пользователей социальных сетей в марте 2012 года).

2. Статистика с различными типами интересов.
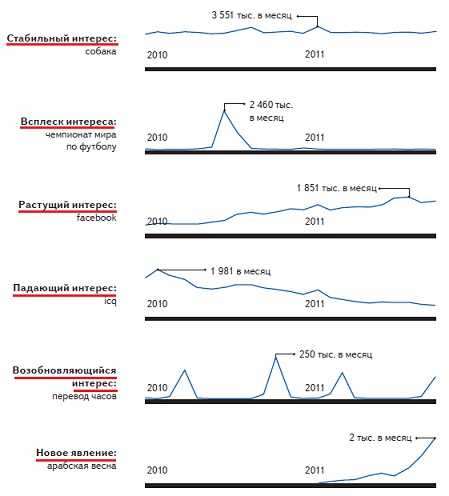
Мой пост о том, как работает поисковая система Яндекс завершен.
Великий провидецВ 1863 году великий писатель Жюль Верн создал очередную свою книгу «Париж в ХХ веке». В ней он подробно описал метро, автомобиль, электрический стул, компьютер и даже сеть Интернет. Однако издатель отказался печатать книгу и она пролежала более 120 лет, пока ее не нашел правнук Жюля Верна в 1989 году. Издана была книга в 1994году.www.workformation.ru
Алгоритмы и технологии Яндекса. Как работает поиск?
В прошлой статье мы рассмотрели наиболее интересные технологии Яндекса, применяемые для обеспечения качественного поиска в интернете. Теперь разберем более подробно, как устроена поисковая машина Яндекса. Что же происходит после того, как пользователь вводит запрос в строку поиска?
MatrixNet
Технология поиска Яндекс устроена сложно. Поисковая выдача формируется на основе формулы ранжирования, построенной на нескольких сотнях факторов, каждый из которых может включаться с индивидуальным коэффициентом, а также в различных комбинациях с прочими факторами.
Формула ранжирования — это функция, построенная на множестве факторов, при помощи которых определяется релевантность сайта поисковому запросу и его очередность в выдаче
Для обеспечения качественного поиска факторы и коэффициенты в формуле ранжирования должны регулярно обновляться. Построением такой формулы в Яндексе занимается MatrixNet (Матрикснет) — метод машинного обучения, введенный Яндексом в 2009 году с целью сделать поиск более точным.
«Матрикснет» — метод машинного обучения, с помощью которого подбирается формула ранжирования Яндекса. Входными данными являются факторы и обучающие данные, подготовленные асессорами (экспертными сотрудниками Яндекса).
Основная его особенность заключается в том, что он устойчив к переобучению и позволяет построить сложную формулу ранжирования с десятками тысяч коэффициентов, которая учитывает множество различных факторов и их комбинаций без увеличения количества асессорских оценок и опасности найти несуществующие закономерности.
Архитектура поиска
Ежедневно пользователи посылают Яндексу десятки миллионов запросов. Для формирования ответа под какой-нибудь один запрос поисковой машине необходимо проверить миллионы документов, определить их релевантность и упорядочить при помощи формулы ранжирования так, чтобы наиболее подходящие страницы сайтов оказались вверху выдачи. Для ускорения этого процесса Яндекс использует заранее подготовленные данные — индекс.
Индекс — база поисковой системы, содержащая сведения о запросах и их позициях на страницах сайтов в сети. Индекс формируется поисковым роботом, который обходит сайты и собирает информацию с заданной периодичностью.
Размер индекса в поиске огромен, чтобы быстро обработать такой объем данных используются тысячи серверов, объединенные в кластеры.
После того, как пользователь вводит запрос в строку поиска, он анализируется компьютерной системой «Метапоиск» на предмет региональной привязки, класса запроса и т.д. Там же запрос проходит лингвистическую обработку. Далее «Метапоиск» проверяет кэш на наличие поискового ответа по данному запросу. По часто задаваемым запросам результаты поиска хранятся в памяти поисковика в течение какого-то времени, а не формируются каждый раз заново.
«Метапоиск» — это программа, которая принимает и разбирает поисковые запросы, передает их соответствующим «Базовым поискам», обеспечивает агрегацию и ранжирование найденных документов, а также производит кеширование части ответов, которые впоследствии возвращаются пользователям без обращения к «Базовому поиску».
Если же ответ не найден, «Метапоиск» передает запрос другой компьютерной системе – «Базовому поиску». Там же хранится поисковая база Яндекса (индекс). Так как это огромный объем данных, индекс разбивается на части, которые хранятся на разных серверах. Такой подход позволяет производить поиск одновременно по нескольким частям базы данных, что заметно ускоряет процесс. Каждый сервер имеет несколько копий, это дает возможность распределять нагрузку и не терять данные. При передаче запроса «Метапоиск» выбирает наименее загруженные сервера «Базового поиска».
«Базовый поиск» обеспечивает поиск по всей части индекса (базе поисковой системы), содержащей сведения о запросах и их позициях на страницах сайтов в сети.
Каждый сервер базового поиска отдает список документов, содержащих поисковый запрос, обратно в «Метапоиск», где они ранжируются по сформированной «Матрикснетом» формуле. Результаты такой работы мы видим на странице выдачи.
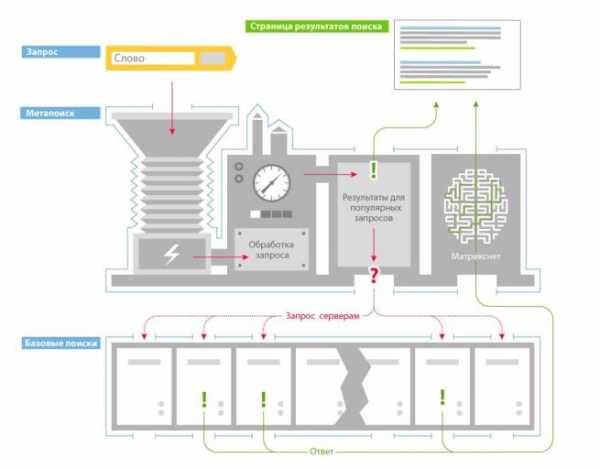
Использование индекса в качестве источника данных, многостадийный подход к формированию ответа и дублирование данных позволяют Яндексу обеспечивать поиск за доли секунды.
Оценка качества поиска
Помимо скорости поиска не менее важно и его качество. Для этого у Яндекса существует система оценки качества поиска, которая также помогает улучшить это качество.
Релевантность – свойство документа, определяющее степень его соответствия поисковому запросу. Вычисляется на основе формулы ранжирования.
Релевантность документа поисковому запросу вычисляется на основе формулы ранжирования – функции от множества факторов. Сейчас в Яндексе более 800 различных факторов, таких как возраст сайта, региональная привязка, взаимодействие пользователей с сайтом (поведенческий фактор), уникальность контента и т.д. В случае с персонализированным поиском релевантность документа зависит непосредственно от предпочтений пользователя, отправившего запрос.
Формула ранжирования постоянно обновляется, так как меняются потребности пользователей и индекс поисковика. Для ее обновления применяется методы машинного обучения. На основе экспертных данных выявляются зависимости между характеристиками документов и порядком их включения в выдачу, которые вносятся в формулу для ее корректировки.
Оценка качества поиска — удовлетворенность пользователей результатами поиска и порядком их следования.
Экспертными данными для машинного обучения являются оценки асессоров, которые также применяются для оценки качества поиска.
Асессоры — специалисты, оценивающие по ряду критериев релевантность представленного в выдаче документа поисковому запросу.
Асессоры оценивают поисковые результаты в выдаче по ряду критериев, которые позволяют определить, присутствует ли на сайте полный ответ на запрос, является ли сайт брендовым, не переспамлен ли текстовый контент и т.д. В основном асессоры работают с наиболее популярными поисковыми запросами (порядка 150 тыс.), при этом оцениваются первые 30 позиций выдачи. Это наиболее авторитетная оценка, так как ее проводит человек, а не машина, т.е. сайт получает оценку с точки зрения пользователя.
Актуализация и улучшение правил ранжирования в комплексе с оценкой качества поиска помогают Яндексу формировать выдачу, соответствующую ожиданиям пользователей.
www.iseo.ru
Как работают поисковые системы Яндекс и Google?
Продвижение сайта своими руками является одновременно простой и сложной задачей. Для человека опытного в этой теме раскрутка представляет собой набор простых и четких шагов, сводящихся, в большей степени, к механических действиям. Но для новичка, который только вчера узнал слово SEO и еще не разобрался в его значении, «победить» поисковые системы и конкурентов практически нереально.

Прежде чем приступить к продвижению, необходимо понять, как работают поисковые системы Яндекс и Google. Можете считать эту статью вводной для моего курса по продвижению сайтов «Бесплатный трафик с Поисковиков», поэтому рекомендую дочитать ее до конца, прежде чем начнете его изучать.
Задача поисковых систем
Интернет непрерывно растет и развивается, вместе с ним эволюционируют и поисковики интернета, но их главная задача остается неизменной – они должны помочь пользователю найти самый лучший ответ на запрос, который он ввел в поле для поиска. Чем более качественные результаты в выдаче показывает поисковик, тем больше ему доверяют люди. Чем больше людей ему доверяют, тем больше денег он может заработать на контекстной рекламе, но это я уже пошел в сторону…
Поисковые системы постоянно анализируют терабайты информации, размещенной на миллионах web страниц, стараясь при этом определить какие сайты заслуживают попадания в ТОП выдачи, а какие являются лучшими кандидатами для попадания в бан.
Как действует поисковая система?
Поисковик – это набор сложных программ и баз данных, которые действуют по определенному алгоритму. Упрощенно, этот алгоритм можно разбить на 3 этапа.
Этап 1. Поиск новых страниц
Вопреки заблуждению многих чайников, поисковые системы выдают информацию не о страницах, находящихся в интернете, а о страницах, находящихся в базе данных поисковой машины. То есть, если сайт неизвестен Яндексу или Goоgle, то и в выдаче он не появится.
Задача поисковика на этом этапе заключается в поиске всех возможных адресов страниц в интернете. Выполняет эту работу так называемый робот «паук». Интернет это ссылки, ссылки и еще раз ссылки и этот «паук» просто переходит по всевозможным ссылкам, записывая в свою базу адреса всех найденных страниц.
Попал на главную страницу сайта, на ней нашел ссылки на страницы рубрик, на страницах рубрик нашел ссылки на страницы со статьями, карточками товаров, ссылки на файлы или другой информацией. На каких-то из посещенных страниц одного сайта, он нашел ссылки на другие сайты – поисковая система переходит по ним и сканирует все, что нашла там.
Прекрасно помогают роботам для ориентирования файлы Robots.txt и карты сайта Sitemap.xml, их надо обязательно сделать, особенно, если сайт имеет много страниц. Тут смотрите, как правильно сделать Robots для WordPress, а про настройку Sitemap расскажу чуть позже.
Задача робота создать адресный справочник по типу — Город, Улица, Дом, Квартира.
Если ваш сайт долгое время не появляется в поисковиках, возможно, его не может найти робот, в этом случае вам поможет моя статья о том, как ускорить индексацию страниц сайта.
Этап 2. Индексация
Как я уже написал выше – в поисковую выдачу попадает информация не с сайтов, находящихся в интернете, а информация из базы данных поисковой системы. И следующая программка поисковика как раз занимается добавлением информации в базу. Она путешествует по всем известным адресам сайтов и страниц, копируя их содержимое на склады поисковой системы.
Называется этот процесс индексация – попадание информации в индекс поисковой системы.
Первый и второй процессы протекают непрерывно и, зачастую, одновременно. Постоянно пополняется база адресов страниц и база информации с этих страниц.
Кстати, в процессе индексации поисковые системы оценивают качество страниц, и информация некоторых из них не попадает в индекс. Как бы поисковик знает об их существовании, но по каким-то причинам считает их бесполезными для пользователя, поэтому не добавляет в выдачу — зачастую это не уникальный контент или служебные страницы. Как проверить тексты на уникальность онлайн смотрите тут.
Этап 3. Определение релевантности и ранжирование
Если то, что мы обсудили в предыдущих пунктах, работает непрерывно и независимо от внешних факторов (действий человека), то третий этап в алгоритме работы поисковых систем начинает действовать только под воздействием человека.
Когда в поисковике задается запрос, система начинает искать на него ответ в наполненной базе знаний по критериям, заданным человеком в этом запросе (как узнать самые популярные запросы в Яндексе).
Сначала, система делает выборку, определяя все релевантные запросу страницы из известных (Релевантные – значит соответствующие, подходящие. Как проверить релевантность страниц сайта я писал тут). Например, для запроса «купить холодильник Норд» релевантными будут страницы содержащие слова «купить», «холодильник», «Норд». Все страницы, содержащие одно или несколько из этих слов, попадут в выдачу поисковой системы.
Следующая задача поисковика, определить в какой последовательности пользователь увидит все эти страницы – их необходимо ранжировать. Факторов, которые будут влиять на порядок выдачи много, но если по-простому, то сначала пользователь увидит страницы содержащие «купить холодильник Норд», если таких нет, то ему будет предложено «купить холодильник» или «холодильник Норд» и в самом конце будут страницы со словами «купить», «холодильник», «Норд».
Факторы, влияющие на ранжирование
Как я уже сказал выше, факторов, влияющие на порядок расстановки страниц сайтов в выдаче поисковой системы много, по словам руководителей Яндекс, их более 700. Цифра внушительная и раскрыть их все не представляется возможным. Более того, все эти факторы неизвестны ни одному сеошнику, так как поисковики держат их в тайне. Но в общих чертах эти факторы можно разделить на три группы.
1. Внутренние факторы
К этой группе относятся факторы, на которые способен повлиять сам вебмастер. В их число входит сам текст, размещенный на странице, его оформление (абзацы, заголовки и другая разметка) — читайте как правильно писать и оформлять статьи. К ним же относятся картинки внутри текста и оформление самого сайта. Ссылки, которые размещаются внутри сайта на различные страницы (внутренняя перелинковка) также относятся к внутренним факторам.
2. Внешние факторы
В целом, эта группа факторов определяет популярность конкретного сайта по мнению других ресурсов интернета. Определяется эта популярность количеством и качеством сайтов, на которых проставлены ссылки на различные страницы вашего сайта, а также упоминания о нем в тексте. Поисковые системы оценивают эту авторитетность по сложной схеме, учитывающей очень большое количество факторов.
Кроме того, ко внутренним факторам поисковые системы причисляют различные социальные сигналы, типа ретвиты, лайки, репосты в ВК, Фейсбук или Одноклассники (Про то, как бесплатно накрутить лайки в ВК я писал тут).
3. Поведенческие факторы
Поведение пользователей в интернете поисковые системы умели отслеживать не всегда. Популярность эта группа факторов начала набирать сравнительно недавно. Различные счетчики статистики и специальные бары в браузерах собирают массу информации о поведении людей на сайтах. По этим данным Яндекс и Google определяют степень значимости сайтов для живых людей. Если на страницах вашего сайта низкий показатель отказов — надолго задерживаются посетители, внимательно читают качественные статьи, переходят по внутренним ссылкам и делают разные другие вещи, значит он людям нравится и достоин размещения на более высоких позициях поисковой выдачи.
Почему Яндекс долго индексирует сайты
Многие из вас обращали внимание на то, что индексация новых страниц Яндексом, как правило, занимает больше времени, чем у Google. Связано это с тем, что новые страницы, найденные поисковыми роботами попадают сначала в общую базу страниц и только после обработки и фильтрации она оказывается в пользовательской выдаче.
Гугл старается проводить процесс переноса новых документов в выдачу непрерывно. В свою очередь Яндекс накапливает новый страницы, обрабатывает их и потом одной общей пачкой отправляет в пользовательскую выдачу. Происходит это один раз в несколько дней (в среднем неделя) и называется эта процедура апдейт (АП). Почти всегда, апдейты проходят ночью, когда нагрузка на сервера поисковой системы минимальна.
По такому алгоритму новая страница попадает в базу данных поисковика (на это может уйти несколько дней), дальше эта страница ждет своей очереди пока информация на ней будет обработана и пройдет ранжирование по релевантным запросам (проходит еще один апдейт) и только на следующий апдейт выдачи новый документ появляется в основном индексе.
Таким образом, некоторые страницы могут ждать своей очереди довольно долго.
Теперь вы знаете, как функционируют поисковые системы и можете приступать к работе над вашими сайтами. Создайте релевантную нужному запросу страницу, дайте поисковику ее проиндексировать и помогите ранжировать ваши страницы выше конкурентов.
- 5
- 4
- 3
- 2
- 1
biznessystem.ru
Как работает поисковая система Яндекс
О данной поисковой системе можно рассуждать достаточно долго, но все же хочется понять, как работает поисковая система Яндекс.
Во времена становления интернета его активными пользователями являлась лишь горстка почитателей и поклонников, информация тоже предоставлялась в минимальном объеме. Доступ к интернету имелся у определенных привилегированных сотрудников научных лабораторий, исследовательских университетов, а применение Сети происходило в строго научных целях. Однако, такой поиск информации до поры до времени не был востребован. Созданные каталоги сайтов строго по темам группировались по ссылкам, тем самым, явившись одним из методов организации легкого доступа к информационным источникам.
Отличительные характеристики поисковой системы Яндекс, история создания.
Поисковая система Яндекс является российским мультипорталом, который специализируется на поиске различной информации. На сегодняшний день поисковая система Яндекс занимает седьмое место в мировом рейтинге поисковых систем, чего только стоит его ежемесячный цикл запросов превышающий 2 миллиарда.
Как работает поисковая система Яндекс?
В настоящее время он является одним из крупнейших порталов, где имеется не только стандартный набор функций, а также принцип работы Яндекса заключается в бесперебойно работающих многочисленных бесплатных веб-сервисах: хостинг, электронная почта, блоги, фотогалереи, платежная система, сервис поиска товаров и служб, социальная сеть, информация о пробках, погоде, телепередачах и многое другое.
Запушен Яндекс был 23 сентября 1997 года, но не сразу занял нишу одного из лидеров поисковых систем Рунета, правда выигрышно отличавшись уже тогда на общем фоне остальных поисковиков. Название поисковика Яндекс произошло от английского Yet another indexer, что в буквальном переводе означает как «очередной индексатор». Кто-то предполагает, что термин Yandex стал производным от наименования первой поисковой системы, носящей название Wandex, но бытуют и другие версии.
Как работала поисковая система Яндекс изначально:
- проверяла уникальность контента, отвергая дублированные тексты,
- из поиска исключала клоны, или ранжировал их весьма низко,
- вел морфологический учет,
- учитывая удаленность ключевых фраз от начала текста, предложила на основе этого осуществлять поиск,
- оценивала релевантность страниц,
- рассматривала, помимо количества запросов определенных слов, частоту их употребления, расстояние между словами, а так же их расположение в тексте,
- реализовала функцию вопрос-ответ.
Возможности со временем Яндекса возрастали. Возник поиск аналогичных документов, поиск по дате, построение списков, сортировка по последним изменениям. Астрономическими темпами увеличивался объем информации и число пользователей, а поисковик Яндекс развивался в ногу со временем, соответствуя требованиям. Стал возможным поиск по частям текста, языковые особенности поиска. Где-то в 1999 году возникло понятие индексации, и появился тематический индекс цитирования (ТИЦ).
Для рекламной компании Яндекс в 2000-м году был придуман слоган «Найдется все». До этого времени визитной карточкой являлся другой слоган «Все вопросы к Яндексу».
Был реализован в 2009 году известный алгоритм «Снежинск», который дал вероятность вести по локальным результатам поиск из 1250 городов России, тем самым наделив Яндекс званием и навыками подлинного маркетолога. В следующем году создав англоязычную версию, Яндекс вышел на мировую арену.
Как работает поисковая система Яндекс сейчас
Работает поисковик на трёх модулях, которые входят в структуру поисковика: робот или краулер, crawler — иными словами спайдер (spyder), клиентская часть, база данных.
Что собой представляет робот? Робот — эта специальная программа функцией, которой является обход сети по расписанию интернет-ресурсов, индексируя интересные загрузки и страницы, содержащиеся в базе данных поисковой системы, которая хранится на специальных серверах. Клиентская часть ответственна за бесперебойное обрабатывание запросов, которые поступают в свою очередь от пользователей и за выдачу необходимой информации. Чтобы выдать эту информацию, Яндекс использует собственную базу данных, определяя и выдавая особенно подходящие под запрос страницы.
Алгоритмы Яндекса
Алгоритмы Яндекса постоянно прогрессируют и меняются, тем самым, изменяя поисковые выдачи веб-страниц. Поисковик Яндекс использует алгоритм ранжирования, тем самым, позволяя пользователю осуществлять корректный поиск необходимых страниц, в максимальной степени соответствующих запросу.
Алгоритм ранжирования можно считать системой математических формул, где с их помощью происходит оценка факторов пользы страницы и ее рейтинга.
Принцип работы Яндекса — обращать огромное внимание на качество информации, представленной на сайте и уникальности контента. Используя инструменты как синонимайзинг для создания контента, обладатели сайтов рискуют быть забаненными Яндексом.
 Многих интересует вопрос, как работает поисковая система Яндекс, почему не производится индексация, правильно сконструированных и заполненных необходимой информацией сайтов? Ответов достаточно много. На это могут оказывать влияние различные факторы, но о них можно узнать в других статьях.
Многих интересует вопрос, как работает поисковая система Яндекс, почему не производится индексация, правильно сконструированных и заполненных необходимой информацией сайтов? Ответов достаточно много. На это могут оказывать влияние различные факторы, но о них можно узнать в других статьях.
Поисковая система Яндекс давно вышла на первые позиции в Рунете. По этой причине специалисты, которые занимаются оптимизацией сайтов, ориентируются на алгоритмы ранжирования Яндекс.
Отличным помощником в написании интересных и познавательных статей является интернет радио. Слушать различные радиостанции можно прямо на нашем сайте.
Поделиться в соц.сетях:
polza24.ru
Работа в Яндексе
1
Как на него попасть
Почти у каждой вакансии Яндекса есть тестовое задание — с него-то всё и начинается. Ответьте на вопросы на странице вакансии и отправляйте заявку. Если вы успешно справились с тестом и заинтересовали службу найма, то получите приглашение на встречу — обычно в течение недели. Дополнительные звонки, письма или повторные заявки процесс не ускоряют.
Резюме
Подойдёт в любой форме, а для дизайнеров и разработчиков его заменит портфолио или ссылка на репозиторий. Хорошо сопроводить резюме вольным рассказом о том, почему вас стоит взять на работу. Будьте готовы вкратце пересказать ключевые факты на собеседовании — умение представить себя интересует не меньше биографии.
Сколько будет встреч
Чаще всего проводятся два собеседования, на особо ответственные должности — до пяти. Первый разговор может быть по телефону или скайпу, но за ним обычно следует личная встреча.
2
Как оно проходит
Обычно встреча длится час или два. Вам предложат чай-кофе, воду и печеньки. Собеседование с претендентами на вакансию разработчика состоит из серии коротких встреч с разными экспертами. Рекрутер обязательно расскажет вам все подробности.Подробности для технических вакансий
Кто будет на собеседовании
Сотрудник отдела найма и ваш потенциальный руководитель. Если вы подходите на несколько ролей или претендуете на важную должность, к встрече могут присоединиться и другие эксперты.
Чего ожидать
Некоторые вопросы или задачки могут не касаться вакансии напрямую — так проверяется способность рассуждать в неизвестной ситуации. Также будьте готовы начертить схему маркером на стене или написать код на бумаге, без компьютера.
3
Что будет после
Между встречами и особенно после финального собеседования иногда наступает длинная пауза. Пожалуйста, наберитесь терпения. Если рекрутер не ответил на звонок или письмо — это не значит, что вы не справились. В это время служба найма может общаться с другими кандидатами, а итоговое тестовое задание часто проверяют много людей.
В случае успеха
Рекрутер сразу свяжется с вами и озвучит предложение Яндекса. В первый день в офисе вас встретят, помогут оформить документы в отделе кадров, получить оборудование и освоиться на рабочем месте.
Если отказали
Поищите другие вакансии — если вы не прошли тестовое задание или собеседование, ничто не мешает попробовать себя в другой роли. Или повторить заявку через какое-то время, когда наберётесь знаний и опыта.
yandex.ru
Компания Яндекс — Технологии — Как работает Яндекс.Метрика
В интернете всё можно измерить. Если у вас есть сайт, несложно посмотреть, сколько посетителей на него приходит, на каких страницах они бывают, как долго там задерживаются и что делают. Можно составить портрет своей аудитории: узнать возраст и интересы разных категорий посетителей. Эти данные помогают развивать сайт и делать его понятнее и удобнее для разных людей.
Системы веб-аналитики
Следить за посещаемостью сайта и оценивать качество его работы помогают системы веб-аналитики. Они различаются набором возможностей, скоростью обработки данных и, конечно, интерфейсами, но в целом устроены похожим образом. Обычно аналитические сервисы состоят из трёх частей. Первая — счётчик. На сайте размещается специальный код, и каждый раз, когда страница загружается или пользователь совершает на ней какие-то действия, счётчик отправляет сообщение в базу данных системы. Это вторая часть сервиса, там информация систематизируется и обрабатывается. Третья часть — интерфейс, в котором представлены обработанные данные по тому или иному сайту и отчёты на основе этих данных — в виде таблиц и графиков.
У Яндекса есть своя аналитическая система, которой ежедневно пользуются миллионы владельцев сайтов, — Метрика. Она умеет быстро обрабатывать огромные объёмы данных и строить произвольные отчёты в реальном времени.
Метрика, как и все системы веб-аналитики, оперирует несколькими базовыми понятиями. «Посетитель» — пользователь, зашедший на сайт. Когда он приходит впервые, в его браузер записывается уникальный идентификатор, по которому счётчик Метрики узнаёт его в следующий раз. «Просмотр» — каждое обращение посетителя к сайту, включая простое обновление страницы. «Визит» — один сеанс работы пользователя с сайтом. Визит начинается, когда посетитель попадает на сайт, и заканчивается, если он не предпринимает там никаких действий в течение определённого времени — по умолчанию это 30 минут. Визит может включать в себя множество просмотров разных страниц. В базе Метрики хранятся данные как об отдельных просмотрах, так и о визитах.
Сбор данных
Когда посетитель переходит на сайт со счётчиком Метрики — из поисковой системы, социальной сети, с рекламного баннера или просто введя адрес в адресной строке, — его браузер загружает код страницы. В этот момент счётчик отправляет в Метрику данные: сам факт загрузки страницы, уникальный идентификатор посетителя, адрес страницы, с которой он пришёл, название и версию браузера и операционной системы и так далее. Метрика не знает ничего о конкретном человеке с именем и фамилией, который совершает в интернете конкретные действия. Идентификатор посетителя и все остальные его параметры становятся частью обезличенной статистики — цифрами, которые помогают пользователю Метрики развивать свой сайт.
Пока посетитель находится на сайте, счётчик продолжает собирать статистику и отправлять её Метрике. Каждый раз, когда человек открывает какую-нибудь страницу, счётчик регистрирует просмотр. Если он длится дольше 15 секунд, система снова получает сообщение — о том, что просмотр продолжается. Если же человек зашёл только на одну страницу сайта и пробыл там меньше 15 секунд, счётчик отправляет сообщение об отказе. Процент отказов помогает владельцу сайта узнать, сколько посетителей не заинтересовались страницей или попали туда случайно.
Счётчик фиксирует прокручивание страницы, движения мыши и клики по кнопкам и ссылкам (отчёт об этих действиях владелец сайта может посмотреть в отдельном разделе Метрики — Вебвизоре). Также он сообщает, совершил ли посетитель важные для владельца сайта действия — например, зарегистрировался на форуме, кликнул по рекламному баннеру или оформил заказ в интернет-магазине.
Для системы статистики один человек может стать несколькими посетителями. Например, если он зайдёт на сайт с двух разных устройств, из разных браузеров или из одного браузера, но после его переустановки. Бывает и наоборот: Метрика может считать одним посетителем семью из пяти человек, если все её члены пользуются одним браузером.
Отчёты
В базе данных Метрики хранятся самые разнообразные данные о посещаемости сайта. Владелец составляет на их основе отчёты и смотрит результаты его работы в разных срезах — временных, географических, возрастных или даже сразу нескольких.
Например, чтобы понять, хорошо ли в целом сработала ваша рекламная кампания, можно посмотреть в Метрике общую информацию — увеличилось ли количество посещений, из каких источников приходили люди и как изменилась глубина просмотра. А можно углубиться в детали и попытаться ответить на более конкретный вопрос. Допустим, у вас есть сервис для молодых жителей Санкт-Петербурга и вы хотите проверить, удобен ли его новый мобильный интерфейс. Метрика позволяет узнать, много ли владельцев смартфонов в возрасте от 18 до 34 лет просмотрело больше двух страниц вашего сайта и много ли было отказов, а вам останется только сделать выводы.
Все отчёты составляются сразу: владелец сайта указывает, что хочет посмотреть, и система сразу же извлекает данные из базы и показывает результат — учитывая даже тех посетителей, которые были на сайте только что.
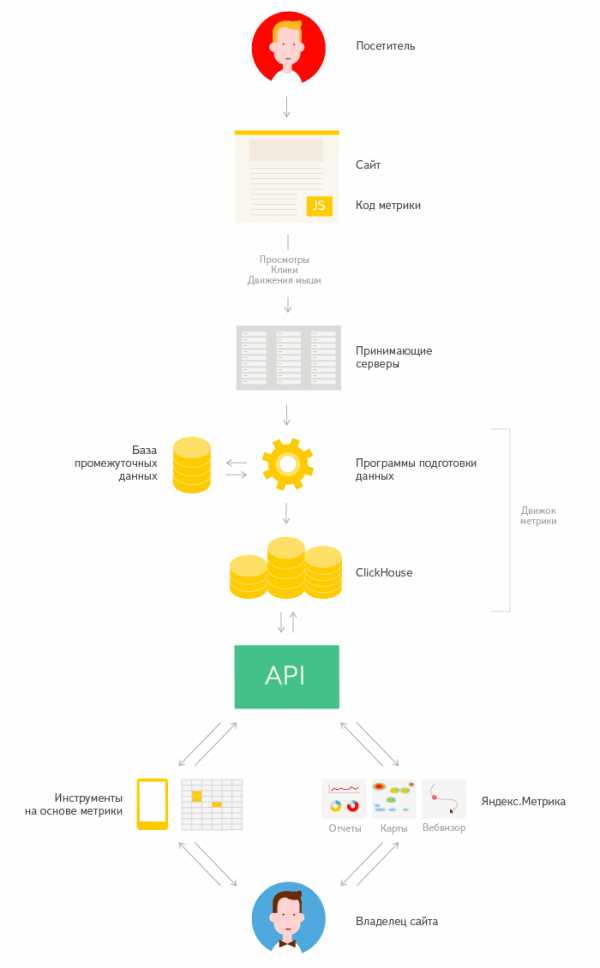
Хранение и обработка данных
Поскольку отчёты создаются в реальном времени, их структура становится известна только в тот момент, когда владелец сайта делает через интерфейс Метрики запрос для получения отчёта. Структура отчёта может быть практически любой, а составляется он за долю секунды. Чтобы владелец сайта получал актуальную и полную информацию, нужно постоянно собирать данные о посещаемости и уметь тут же их обрабатывать. Для этого в 2012 году Яндекс разработал свою систему управления базами данных (СУБД) — ClickHouse.Есть два варианта подготовки данных для аналитических отчётов. В первом, с которым раньше работала Метрика, данные агрегируются предварительно, и на их основе составляется фиксированный набор отчётов. Это позволяет загружать отчёты достаточно быстро, но ограничивает гибкость аналитики: пользователь может получить только один из набора предусмотренных отчётов. Другой вариант — хранить поступающие в систему события без предварительной агрегации, а вычисления выполнять в онлайне — в тот момент, когда пользователь загружает отчёт. Это сильно расширяет аналитические возможности, но накладывает очень серьёзные требования на скорость обработки данных.
Существует два основных типа СУБД — строковые и столбцовые. Они отличаются организацией хранения данных на физическом уровне. Большинство известных СУБД строковые — в них данные, которые в таблице находятся в разных ячейках одной строки, хранятся рядом, друг за другом. Такие СУБД хорошо подходят, например, для обработки транзакций, так как позволяют быстро обновлять отдельные строки в базе данных. Для аналитических запросов, когда необходимы только данные из нескольких столбцов в большом массиве строк, строковые СУБД подходят хуже. При обработке таких запросов необходимо прочитать и отбросить значения всех остальных столбцов — в том числе в данном случае ненужных. На это уходит время.
В столбцовых СУБД, к которым как раз и относится ClickHouse, данные хранятся в порядке столбцов: значения, относящиеся к одному столбцу, расположены рядом. В Яндекс.Метрике мы храним события (визиты, просмотры и т. п.) в нескольких таблицах, где строки — это всё те же события, а столбцы — их параметры. Такая структура СУБД позволяет увеличивать количество параметров событий без потери производительности. Например, если нам нужно получить отчёт по количеству уникальных посетителей в разрезе регионов, достаточно прочитать с диска только два столбца.
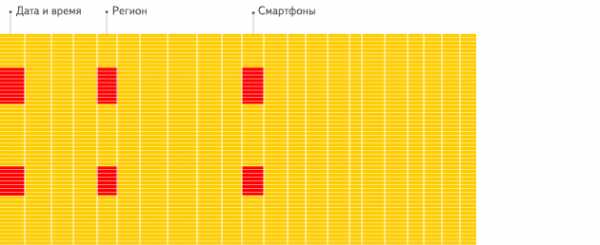
В октябре 2015 года объём данных Метрики только для веб-сайтов составил 10,65 триллиона строк. В наиболее крупной таблице содержится 349 столбцов. Каждый раз, когда владелец сайта открывает страницу в Метрике, в ClickHouse отправляется несколько запросов. Всего база данных получает примерно 2000 запросов в секунду; пиковая скорость обработки данных превышает два терабайта в секунду.
ClickHouse легко масштабируется: добавление новых серверов происходит без перестройки кластера. Один запрос может обрабатываться с использованием вычислительной мощности всех доступных серверов, поэтому данные обрабатываются очень быстро. Другая полезная особенность ClickHouse — отказоустойчивость: даже если какие-то серверы выходят из строя, система продолжает работать. Для этого данные реплицируются в географически распределённых дата-центрах.
ClickHouse позволяет серьёзно уменьшить затраты на хранение и обработку данных. Данные хранятся в нём по столбцам, и за счёт этого их можно эффективно сжимать. В ClickHouse реализован векторный движок выполнения запросов: данные не только хранятся, но и обрабатываются по столбцам, что позволяет оптимальным образом использовать процессор и память. Данные на диске переупорядочиваются (например, по сайту и дате), чтобы для составления отчёта достаточно было прочитать с диска лишь небольшой диапазон строк. Одновременно с этим ClickHouse позволяет добавлять в таблицу новые данные в реальном времени.
Система ClickHouse, разработанная в команде Метрики и для её нужд, оказалась полезна и для других задач Яндекса. В том числе СУБД используется в Маркете, рекламных технологиях, системе мониторинга серверов и внутренней бизнес-аналитике. ClickHouse сравнительно прост для изучения, так как для запросов используется язык SQL.
yandex.ru