Знакомство с хранилищем Ceph в картинках / Habr
Облачные файловые хранилища продолжают набирать популярность, и требования к ним продолжают расти. Современные системы уже не в состоянии полностью удовлетворить все эти требования без значительных затрат ресурсов на поддержку и масштабирование этих систем. Под системой я подразумеваю кластер с тем или иным уровнем доступа к данным. Для пользователя важна надежность хранения и высокая доступность, чтобы файлы можно было всегда легко и быстро получить, а риск потери данных стремился к нулю. В свою очередь для поставщиков и администраторов таких хранилищ важна простота поддержки, масштабируемость и низкая стоимость аппаратных и программных компонентов.Ceph — это программно определяемая распределенная файловая система с открытым исходным кодом, лишенная узких мест и единых точек отказа, которая представляет из себя легко масштабируемый до петабайтных размеров кластер узлов, выполняющих различные функции, обеспечивая хранение и репликацию данных, а также распределение нагрузки, что гарантирует высокую доступность и надежность. Система бесплатная, хотя разработчики могут предоставить платную поддержку. Никакого специального оборудования не требуется.
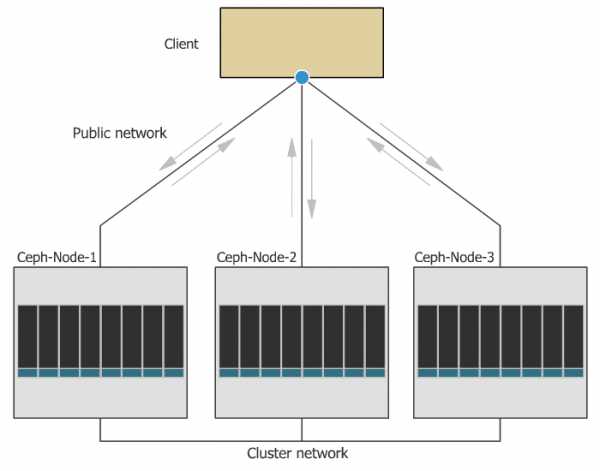
При выходе любого диска, узла или группы узлов из строя Ceph не только обеспечит сохранность данных, но и сам восстановит утраченные копии на других узлах до тех пор, пока вышедшие из строя узлы или диски не заменят на рабочие. При этом ребилд происходит без секунды простоя и прозрачно для клиентов. 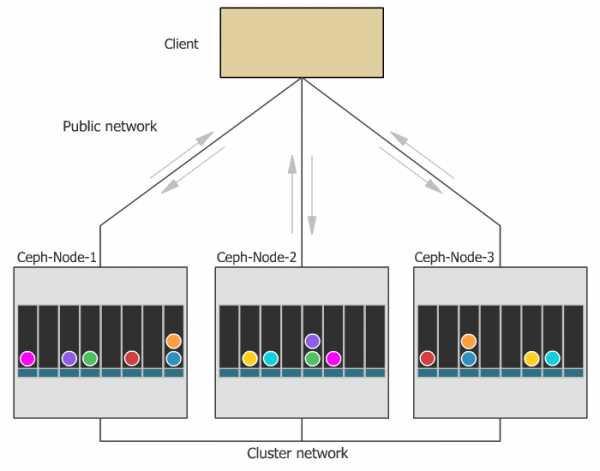
Поскольку система программно определяемая и работает поверх стандартных файловых систем и сетевых уровней, можно взять пачку разных серверов, набить их разными дисками разного размера, соединить всё это счастье какой-нибудь сетью (лучше быстрой) и поднять кластер. Можно воткнуть в эти серверы по второй сетевой карте, и соединить их второй сетью для ускорения межсерверного обмена данными. А эксперименты с настройками и схемами можно легко проводить даже в виртуальной среде. Мой опыт экспериментов показывает, что самое долгое в этом процессе — это установка ОС. Если у нас есть три сервера с дисками и настроенной сетью, то поднятие работоспособного кластера с дефолтными настройками займет 5-10 минут (если все делать правильно).
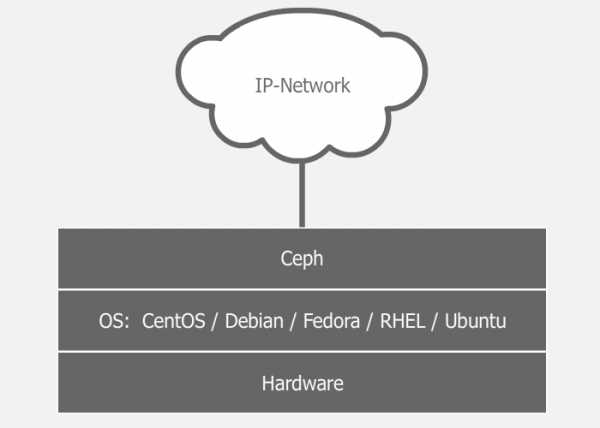
Поверх операционной системы работают демоны Ceph, выполняющие различные роли кластера. Таким образом один сервер может выступать, например, и в роли монитора (MON), и в роли хранилища данных (OSD). А другой сервер тем временем может выступать в роли хранилища данных и в роли сервера метаданных (MDS). В больших кластерах демоны запускаются на отдельных машинах, но в малых кластерах, где количество серверов сильно ограничено, некоторые сервера могут выполнять сразу две или три роли. Зависит от мощности сервера и самих ролей. Разумеется, все будет работать шустрее на отдельных серверах, но не всегда это возможно реализовать. Кластер можно собрать даже из одной машины и всего одного диска, и он будет работать. Другой разговор, что это не будет иметь смысла. Следует отметить и то, что благодаря программной определяемости, хранилище можно поднять даже поверх RAID или iSCSI-устройства, однако в большинстве случаев это тоже не будет иметь смысла.
В документации перечислено 3 вида демонов:
- Mon — демон монитора
- OSD — демон хранилища
- MDS — сервер метаданных (необходим только в случае использования CephFS)
Первоначальный кластер можно создать из нескольких машин, совмещая на них роли кластера. Затем, с ростом кластера и добавлением новых серверов, какие-то роли можно дублировать на других машинах или полностью выносить на отдельные серверы.
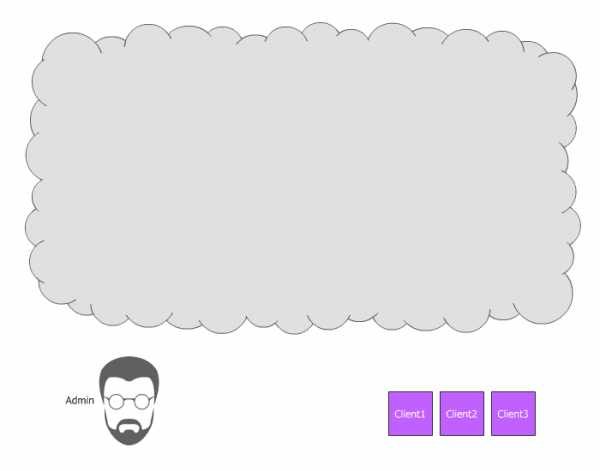
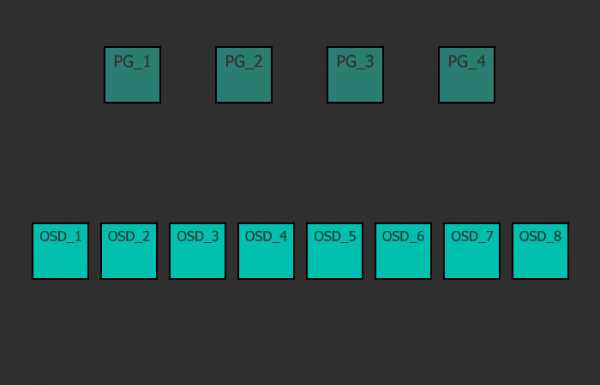
Для начала коротко и непонятно. Кластер может иметь один или много пулов данных разного назначения и с разными настройками. Пулы делятся на плейсмент-группы. В плейсмент-группах хранятся объекты, к которым обращаются клиенты. На этом логический уровень заканчивается, и начинается физический, потому как за каждой плейсмент-группой закреплен один главный диск и несколько дисков-реплик (сколько именно зависит от фактора репликации пула). Другими словами, на логическом уровне объект хранится в конкретной плейсмент-группе, а на физическом — на дисках, которые за ней закреплены. При этом диски физически могут находиться на разных узлах или даже в разных датацентрах.

Далее подробно & понятно.
Фактор репликации — это уровень избыточности данных. Количество копий данных, которое будет храниться на разных дисках. За этот параметр отвечает переменная size. Фактор репликации может быть разным для каждого пула, и его можно менять на лету. Вообще, в Ceph практически все параметры можно менять на лету, мгновенно получая реакцию кластера. Сначала у нас может быть size=2, и в этом случае, пул будет хранить по две копии одного куска данных на разных дисках. Этот параметр пула можно поменять на size=3, и в этот же момент кластер начнет перераспределять данные, раскладывая еще одну копию уже имеющихся данных по дискам, не останавливая работу клиентов.
Пул — это логический абстрактный контейнер для организации хранения данных пользователя. Любые данные хранятся в пуле в виде объектов. Несколько пулов могут быть размазаны по одним и тем же дискам (а может и по разным, как настроить) с помощью разных наборов плейсмент-групп. Каждый пул имеет ряд настраиваемых параметров: фактор репликации, количество плейсмент-групп, минимальное количество живых реплик объекта, необходимое для работы и т. д. Каждому пулу можно настроить свою политику репликации (по городам, датацентрам, стойкам или даже дискам). Например, пул под хостинг может иметь фактор репликации size=3, а зоной отказа будут датацентры. И тогда Ceph будет гарантировать, что каждый кусочек данных имеет по одной копии в трех датацентрах. Тем временем, пул для виртуальных машин может иметь фактор репликации size=2, а уровнем отказа уже будет серверная стойка. И в этом случае, кластер будет хранить только две копии. При этом, если у нас две стойки с хранилищем виртуальных образов в одном датацентре, и две стойки в другом, система не будет обращать внимание на датацентры, и обе копии данных могут улететь в один датацентр, однако гарантированно в разные стойки, как мы и хотели.
Каждый объект на логическом уровне хранится в конкретной плейсмент-группе. На физическом же уровне, он лежит в нужном количестве копий на разных физических дисках, которые в эту плейсмент-группу включены (на самом деле не диски, а OSD, но обычно один OSD это и есть один диск, и для простоты я буду называть это диском, хотя напомню, за ним может быть и RAID-массив или iSCSI-устройство). При факторе репликации size=3, каждая плейсмент группа включает в себя три диска. Но при этом каждый диск находится во множестве плейсмент-групп, и для каких то групп он будет первичным, для других — репликой. Если OSD входит, например, в состав трех плейсмент-групп, то при падении такого OSD, плейсмент-группы исключат его из работы, и на его место каждая плейсмент-группа выберет рабочий OSD и размажет по нему данные. С помощью данного механизма и достигается достаточно равномерное распределение данных и нагрузки. Это весьма простое и одновременно гибкое решение.
Монитор — это демон, выполняющий роль координатора, с которого начинается кластер. Как только у нас появляется хотя бы один рабочий монитор, у нас появляется Ceph-кластер. Монитор хранит информацию о здоровье и состоянии кластера, обмениваясь различными картами с другими мониторами. Клиенты обращаются к мониторам, чтобы узнать, на какие OSD писать/читать данные. При разворачивании нового хранилища, первым делом создается монитор (или несколько). Кластер может прожить на одном мониторе, но рекомендуется делать 3 или 5 мониторов, во избежание падения всей системы по причине падения единственного монитора. Главное, чтобы количество оных было нечетным, дабы избежать ситуаций раздвоения сознания (split-brain). Мониторы работают в кворуме, поэтому если упадет больше половины мониторов, кластер заблокируется для предотвращения рассогласованности данных.
Если size=3 и min_size=2: все будет хорошо, пока 2 из 3 OSD плейсмент-группы живы. Когда останется всего лишь 1 живой OSD, кластер заморозит операции данной плейсмент-группы, пока не оживет хотя бы еще один OSD.
Если size=min_size, то плейсмент-группа будет блокироваться при падении любого OSD, входящего в ее состав. А из-за высокого уровня размазанности данных, большинство падений хотя бы одного OSD будет заканчиваться заморозкой всего или почти всего кластера. Поэтому параметр size всегда должен быть хотя бы на один пункт больше параметра min_size.
Если size=1, кластер будет работать, но смерть любой OSD будет означать безвозвратную потерю данных. Ceph дозволяет выставить этот параметр в единицу, но даже если администратор делает это с определенной целью на короткое время, он риск берет на себя.
Диск OSD состоит из двух частей: журнал и сами данные. Соответственно, данные сначала пишутся в журнал, затем уже в раздел данных. С одной стороны это дает дополнительную надежность и некоторую оптимизацию, а с другой стороны — дополнительную операцию, которая сказывается на производительности. Вопрос производительности журналов рассмотрим ниже.
В основе механизма децентрализации и распределения лежит так называемый CRUSH-алгоритм (Controlled Replicated Under Scalable Hashing), играющий важную роль в архитектуре системы. Этот алгоритм позволяет однозначно определить местоположение объекта на основе хеша имени объекта и определенной карты, которая формируется исходя из физической и логической структур кластера (датацентры, залы, ряды, стойки, узлы, диски). Карта не включает в себя информацию о местонахождении данных. Путь к данным каждый клиент определяет сам, с помощью CRUSH-алгоритма и актуальной карты, которую он предварительно спрашивает у монитора. При добавлении диска или падении сервера, карта обновляется.
Благодаря детерминированности, два разных клиента найдут один и тот же однозначный путь до одного объекта самостоятельно, избавляя систему от необходимости держать все эти пути на каких-то серверах, синхронизируя их между собой, давая огромную избыточную нагрузку на хранилище в целом.
Пример:

Клиент хочет записать некий объект object1 в пул Pool1. Для этого он смотрит в карту плейсмент-групп, которую ему ранее любезно предоставил монитор, и видит, что Pool1 разделен на 10 плейсмент-групп. Далее с помощью CRUSH-алгоритма, который на вход принимает имя объекта и общее количество плейсмент-групп в пуле Pool1, вычисляется ID плейсмент-группы. Следуя карте, клиент понимает, что за этой плейсмент-группой закреплено три OSD (допустим, их номера: 17, 9 и 22), первый из которых является первичным, а значит клиент будет производить запись именно на него. Кстати, их три, потому что в этом пуле установлен фактор репликации size=3. После успешной записи объекта на OSD_17, работа клиента закончена (это если параметр пула min_size=1), а OSD_17 реплицирует этот объект на OSD_9 и OSD_22, закрепленные за этой плейсмент-группой. Важно понимать, что это упрощенное объяснение работы алгоритма.
По умолчанию наша CRUSH-карта плоская, все ноды находятся в одном пространстве. Однако, можно эту плоскость легко превратить в дерево, распределив серверы по стойкам, стойки по рядам, ряды по залам, залы по датацентрам, а датацентры по разным городам и планетам, указав какой уровень считать зоной отказа. Оперируя такой новой картой, Ceph будет грамотнее распределять данные, учитывая индивидуальные особенности организации, предотвращая печальные последствия пожара в датацентре или падения метеорита на целый город. Более того, благодаря этому гибкому механизму, можно создавать дополнительные слои, как на верхних уровнях (датацентры и города), так и на нижних (например, дополнительное разделение на группы дисков в рамках одного сервера).
Ceph предусматривает несколько способов увеличения производительности кластера методами кеширования.
Primary-Affinity
У каждого OSD есть несколько весов, и один из них отвечает за то, какой OSD в плейсмент-группе будет первичным. А, как мы выяснили ранее, клиент пишет данные именно на первичный OSD. Так вот, можно добавить в кластер пачку SSD дисков, сделав их всегда первичными, снизив вес primary-affinity HDD дисков до нуля. И тогда запись будет осуществляться всегда сначала на быстрый диск, а затем уже не спеша реплицироваться на медленные. Этот метод самый неправильный, однако самый простой в реализации. Главный недостаток в том, что одна копия данных всегда будет лежать на SSD и потребуется очень много таких дисков, чтобы полностью покрыть репликацию. Хотя этот способ кто-то и применял на практике, но его я скорее упомянул для того, чтобы рассказать о возможности управления приоритетом записи.
Вынос журналов на SSD
Вообще, львиная доля производительности зависит от журналов OSD. Осуществляя запись, демон сначала пишет данные в журнал, а затем в само хранилище. Это верно всегда, кроме случаев использования BTRFS в качестве файловой системы на OSD, которая может делать это параллельно благодаря технике copy-on-write, но я так и не понял, насколько она готова к промышленному применению. На каждый OSD идет собственный журнал, и по умолчанию он находится на том же диске, что и сами данные. Однако, журналы с четырёх или пяти дисков можно вынести на один SSD, неплохо ускорив операции записи. Метод не очень гибкий и удобный, но достаточно простой. Недостаток метода в том, что при вылете SSD с журналом, мы потеряем сразу несколько OSD, что не очень приятно и вносит дополнительные трудности во всю дальнейшую поддержку, которая скалируется с ростом кластера.
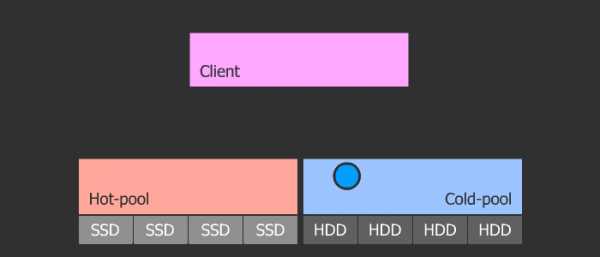
Кеш-тиринг
Ортодоксальность данного метода в его гибкости и масштабируемости. Схема такова, что у нас есть пул с холодными данными и пул с горячими. При частом обращении к объекту, тот как бы нагревается и попадает в горячий пул, который состоит из быстрых SSD. Затем, если объект остывает, он попадает в холодный пул с медленными HDD. Данная схема позволяет легко менять SSD в горячем пуле, который в свою очередь может быть любого размера, ибо параметры нагрева и охлаждения регулируются.
Ceph предоставляет для клиента различные варианты доступа к данным: блочное устройство, файловая система или объектное хранилище.
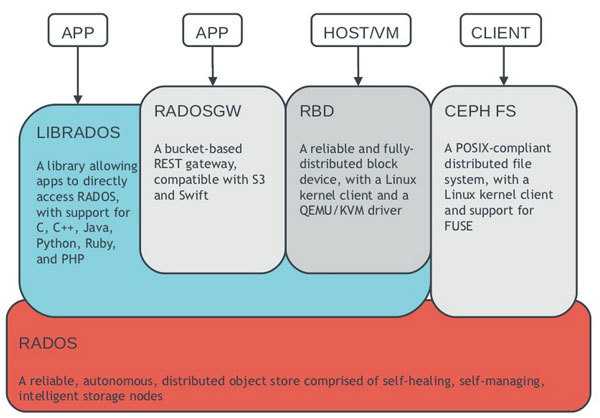
Блочное устройство (RBD, Rados Block Device)
Ceph позволяет в пуле данных создать блочное устройство RBD, и в дальнейшем смонтировать его на операционных системах, которые это поддерживают (на момент написания статьи были только различные дистрибутивы linux, однако FreeBSD и VMWare тоже работают в эту сторону). Если клиент не поддерживает RBD (например Windows), то можно использовать промежуточный iSCSI-target с поддержкой RBD (например, tgt-rbd). Кроме того, такое блочное устройство поддерживает снапшоты.
Файловая система CephFS
Клиент может смонтировать файловую систему CephFS, если у него linux с версией ядра 2.6.34 или новее. Если версия ядра старше, то можно смонтировать ее через FUSE (Filesystem in User Space). Для того, чтобы клиенты могли подключать Ceph как файловую систему, необходимо в кластере поднять хотя бы один сервер метаданных (MDS)
Шлюз объектов
С помощью шлюза RGW (RADOS Gateway) можно клиентам дать возможность пользоваться хранилищем через RESTful Amazon S3 или OpenStack Swift совместимое API.
И другие…
Все эти уровни доступа к данным работают поверх уровня RADOS. Список можно дополнить, разработав свой слой доступа к данным с помощью librados API (через который и работают перечисленные выше слои доступа). На данный момент есть биндинги C, Python, Ruby, Java и PHP
RADOS (Reliable Autonomic Distributed Object Store), если в двух словах, то это слой взаимодействия клиентов и кластера.
Википедия гласит, что сам Ceph написан на C++ и Python, а в разработке принимают участие компании Canonical, CERN, Cisco, Fujitsu, Intel, Red Hat, SanDisk, and SUSE.
Зачем я все это написал и нарисовал картинков? Затем что не смотря на все эти достоинства, Ceph либо не очень популярен, либо люди кушают его втихомолку, судя по количеству информации о нем в интернете.
То, что Ceph гибкий, простой и удобный, мы выяснили. Кластер можно поднять на любом железе в обычной сети, потратив минимум времени и сил, при этом Ceph сам будет заботиться о сохранности данных, предпринимая необходимые меры в случае сбоев железа. В том, что Ceph гибкий, простой и масштабируемый сходится множество точек зрения. Однако отзывы о производительности встречаются весьма разнообразные. Возможно кто-то не справился с журналами, кого-то подвела сеть и задержки в операциях ввода/вывода. То есть, заставить кластер работать — легко, но заставить его работать быстро — возможно, сложнее. Посему, я взываю к ИТ-специалистам, которые имеют опыт использования Ceph в продакшене. Поделитесь в комментариях о своих отрицательных впечатлениях.
Ссылки
Сайт Ceph
Википедия
Документация
GitHub
Книга рецептов Ceph
Книга Learning Ceph
Ceph на VMWare за 10 минут
Интенсив по Ceph на русском языке
habr.com
обзор для новичков / 1cloud.ru corporate blog / Habr
Международный рынок гипермасштабируемых дата-центров растет с ежегодными темпами в 11%. Основные «драйверы» — предприятия, подключенные устройства и пользователи — они обеспечивают постоянное появление новых данных. Вместе с объемом рынка растут и требования к надежности хранения и уровню доступности данных.Ключевой фактор, влияющий на оба критерия — системы хранения. Их классификация не ограничивается типами оборудования или брендами. В этой статье мы рассмотрим разновидности хранилищ — блочное, файловое и объектное — и определим, для каких целей подходит каждое из них.

/ Flickr / Jason Baker / CC
Типы хранилищ и их различия
Хранение на уровне блоков лежит в основе работы традиционного жесткого диска или магнитной ленты. Файлы разбиваются на «кусочки» одинакового размера, каждый с собственным адресом, но без метаданных. Пример — ситуация, когда драйвер HDD пишет и считывает блоки по адресам на отформатированном диске. Такие СХД используются многими приложениями, например, большинством реляционных СУБД, в списке которых Oracle, DB2 и др. В сетях доступ к блочным хостам организуется за счет SAN с помощью протоколов Fibre Channel, iSCSI или AoE.
Файловая система — это промежуточное звено между блочной системой хранения и вводом-выводом приложений. Наиболее распространенным примером хранилища файлового типа является NAS. Здесь, данные хранятся как файлы и папки, собранные в иерархическую структуру, и доступны через клиентские интерфейсы по имени, названию каталога и др.

/ Wikimedia / Mennis / CC
При этом следует отметить, что разделение «SAN — это только сетевые диски, а NAS — сетевая файловая система» искусственно. Когда появился протокол iSCSI, граница между ними начала размываться. Например, в начале нулевых компания NetApp стала предоставлять iSCSI на своих NAS, а EMC — «ставить» NAS-шлюзы на SAN-массивы. Это делалось для повышения удобства использования систем.
Что касается объектных хранилищ, то они отличаются от файловых и блочных отсутствием файловой системы. Древовидную структуру файлового хранилища здесь заменяет плоское адресное пространство. Никакой иерархии — просто объекты с уникальными идентификаторами, позволяющими пользователю или клиенту извлекать данные.
Марк Горос (Mark Goros), генеральный директор и соучредитель Carnigo, сравнивает такой способ организации со службой парковки, предполагающей выдачу автомобиля. Вы просто оставляете свою машину парковщику, который увозит её на стояночное место. Когда вы приходите забирать транспорт, то просто показываете талон — вам возвращают автомобиль. Вы не знаете, на каком парковочном месте он стоял.
Большинство объектных хранилищ позволяют прикреплять метаданные к объектам и агрегировать их в контейнеры. Таким образом, каждый объект в системе состоит из трех элементов: данных, метаданных и уникального идентификатора — присвоенного адреса. При этом объектное хранилище, в отличие от блочного, не ограничивает метаданные атрибутами файлов — здесь их можно настраивать.
/ 1cloud
Применимость систем хранения разных типов
Блочные хранилища
Блочные хранилища обладают набором инструментов, которые обеспечивают повышенную производительность: хост-адаптер шины разгружает процессор и освобождает его ресурсы для выполнения других задач. Поэтому блочные системы хранения часто используются для виртуализации. Также хорошо подходят для работы с базами данных.
Недостатками блочного хранилища являются высокая стоимость и сложность в управлении. Еще один минус блочных хранилищ (который относится и к файловым, о которых далее) — ограниченный объем метаданных. Любую дополнительную информацию приходится обрабатывать на уровне приложений и баз данных.
Файловые хранилища
Среди плюсов файловых хранилищ выделяют простоту. Файлу присваивается имя, он получает метаданные, а затем «находит» себе место в каталогах и подкаталогах. Файловые хранилища обычно дешевле по сравнению с блочными системами, а иерархическая топология удобна при обработке небольших объемов данных. Поэтому с их помощью организуются системы совместного использования файлов и системы локального архивирования.
Пожалуй, основной недостаток файлового хранилища — его «ограниченность». Трудности возникают по мере накопления большого количества данных — находить нужную информацию в куче папок и вложений становится трудно. По этой причине файловые системы не используются в дата-центрах, где важна скорость.
Объектные хранилища
Что касается объектных хранилищ, то они хорошо масштабируются, поэтому способны работать с петабайтами информации. По статистике, объем неструктурированных данных во всем мире достигнет 44 зеттабайт к 2020 году — это в 10 раз больше, чем было в 2013. Объектные хранилища, благодаря своей возможности работать с растущими объемами данных, стали стандартом для большинства из самых популярных сервисов в облаке: от Facebook до DropBox.
Такие хранилища, как Haystack Facebook, ежедневно пополняются 350 млн фотографий и хранят 240 млрд медиафайлов. Общий объем этих данных оценивается в 357 петабайт.
Хранение копий данных — это другая функция, с которой хорошо справляются объектные хранилища. По данным исследований, 70% информации лежит в архиве и редко изменяется. Например, такой информацией могут выступать резервные копии системы, необходимые для аварийного восстановления.
Но недостаточно просто хранить неструктурированные данные, иногда их нужно интерпретировать и организовывать. Файловые системы имеют ограничения в этом плане: управление метаданными, иерархией, резервным копированием — все это становится препятствием. Объектные хранилища оснащены внутренними механизмами для проверки корректности файлов и другими функциями, обеспечивающими доступность данных.
Плоское адресное пространство также выступает преимуществом объектных хранилищ — данные, расположенные на локальном или облачном сервере, извлекаются одинаково просто. Поэтому такие хранилища часто применяются для работы с Big Data и медиа. Например, их используют Netflix и Spotify. Кстати, возможности объектного хранилища сейчас доступны и в сервисе 1cloud.
Благодаря встроенным инструментам защиты данных с помощью объектного хранилища можно создать надежный географически распределенный резервный центр. Его API основан на HTTP, поэтому к нему можно получить доступ, например, через браузер или cURL. Чтобы отправить файл в хранилище объектов из браузера, можно прописать следующее:
<form action = "[url_storage/account/container/object]"
method = "post"
enctype = "multipart/form-data">
<input type="hidden" name="redirect" value="[url_result]">
<input type="hidden" name="signature" value="[hmac]">
<input type="file" name="file_name">
<input type="submit">
</form>
После отправки к файлу добавляются необходимые метаданные. Для этого есть такой запрос:
curl -i [url_storage/account/container/object] -X POST
-H "X-Auth-Token: [token]" -H "X-Object-Meta-ValueA: [value-a]"
Богатая метаинформация объектов позволит оптимизировать процесс хранения и минимизировать затраты на него. Эти достоинства — масштабируемость, расширяемость метаданных, высокая скорость доступа к информации — делают объектные системы хранения оптимальным выбором для облачных приложений.
Однако важно помнить, что для некоторых операций, например, работы с транзакционными рабочими нагрузками, эффективность решения уступает блочным хранилищам. А его интеграция может потребовать изменения логики приложения и рабочих процессов.
P.S. Еще несколько материалов о хранении данных из блога 1cloud:
habr.com
Создание высокодоступных приложений службы хранилища Azure в хранилище, избыточное между зонами (ZRS)
- Время чтения: 11 мин
-
Соавторы
В этой статье
Хранилище, избыточное в пределах зоны (ZRS), позволяет синхронно реплицировать данные в трех кластерах хранилища одного региона.Zone-redundant storage (ZRS) replicates your data synchronously across three storage clusters in a single region. Каждый кластер хранилища физически отделен от других и находится в собственной зоне доступности.Each storage cluster is physically separated from the others and is located in its own availability zone (AZ). Каждая зона доступности со входящим в нее кластером ZRS является автономной и содержит отдельные программы и сетевые возможности.Each availability zone—and the ZRS cluster within it—is autonomous and includes separate utilities and networking features.
При хранении данных в учетной записи хранения с применением репликации ZRS вы можете получать доступ к данным и управлять ими, даже если зона доступности становится недоступной.When you store your data in a storage account using ZRS replication, you can continue to access and manage your data if an availability zone becomes unavailable. ZRS обеспечивает превосходную производительность и минимальную задержку.ZRS provides excellent performance and low latency. ZRS предлагает те же целевые показатели масштабируемости, что и локально избыточное хранилище (LRS).ZRS offers the same scalability targets as locally redundant storage (LRS).
Рекомендуется использовать ZRS для сценариев, требующих согласованности, устойчивости и высокого уровня доступности.Consider ZRS for scenarios that require consistency, durability, and high availability. Даже если в случае сбоя или стихийного бедствия зона доступности становится недоступной, ZRS обеспечивает устойчивость объектов хранилища, на уровне не менее 99,9999999999 % (12 девяток) в течение указанного года.Even if an outage or natural disaster renders an availability zone unavailable, ZRS offers durability for storage objects of at least 99.9999999999% (12 9’s) over a given year.
Дополнительные сведения о зонах доступности см. здесь.For more information about availability zones, see Availability Zones overview.
Доступность в регионах и действие поддержкиSupport coverage and regional availability
ZRS в настоящее время поддерживает типы учетных записей общего назначения версии 2.ZRS currently supports standard general-purpose v2 account types. Дополнительные сведения о типах учетных записей хранения см. в статье Общие сведения об учетной записи хранения.For more information about storage account types, see Azure storage account overview.
ZRS доступно для блочных BLOB-объектов, бездисковых страничных BLOB-объектов, файлов, таблиц и очередей.ZRS is available for block blobs, non-disk page blobs, files, tables, and queues.
ZRS общедоступно в следующих регионах:ZRS is generally available in the following regions:
- Юго-восточная АзияAsia Southeast
- Западная ЕвропаEurope West
- Северная ЕвропаEurope North
- Центральная ФранцияFrance Central
- Восточная часть ЯпонииJapan East
- Восточная часть СШАUS East
- Восточная часть США 2US East 2
- Западная часть США 2US West 2
- Центральная часть СШАUS Central
Корпорация Майкрософт продолжает запускать ZRS в других регионах Azure.Microsoft continues to enable ZRS in additional Azure regions. Регулярно проверяйте страницу обновлений служб Azure для получения информации о новых регионах.Check the Azure Service Updates page regularly for information about new regions.
Ваши данные будут по-прежнему доступны для чтения и записи, даже если зона становится недоступной.Your data is still accessible for both read and write operations even if a zone becomes unavailable. Корпорация Майкрософт рекомендует и дальше следовать рекомендациям по устранению временных сбоев.Microsoft recommends that you continue to follow practices for transient fault handling. Эти рекомендации включают в себя внедрение политик повтора с экспоненциальной задержкой.These practices include implementing retry policies with exponential back-off.
Если зона отключена, Azure выполняет обновления сети, например перенаправление DNS.When a zone is unavailable, Azure undertakes networking updates, such as DNS repointing. Такие обновления могут повлиять на приложение, если вы получаете доступ к своим данным до завершения обновлений.These updates may affect your application if you are accessing your data before the updates have completed.
ZRS не может защитить данные от региональной аварии, где постоянно затрагиваются несколько зон.ZRS may not protect your data against a regional disaster where multiple zones are permanently affected. Вместо этого хранилище ZRS обеспечивает устойчивость для данных, если оно становится временно недоступным.Instead, ZRS offers resiliency for your data if it becomes temporarily unavailable. Для защиты от региональных аварий мы советуем использовать геоизбыточное хранилище (GRS).For protection against regional disasters, Microsoft recommends using geo-redundant storage (GRS). Дополнительные сведения о GRS см. в статье Геоизбыточное хранилище (GRS). Межрегиональная репликация для службы хранилища Azure.For more information about GRS, see Geo-redundant storage (GRS): Cross-regional replication for Azure Storage.
Преобразование в репликацию ZRSConverting to ZRS replication
Выполнить миграцию в LRS, GRS и RA-GRS и из них достаточно просто.Migrating to or from LRS, GRS, and RA-GRS is straightforward. Чтобы изменить тип избыточности учетной записи, воспользуйтесь порталом Azure или API поставщика ресурсов хранилища.Use the Azure portal or the Storage Resource Provider API to change your account’s redundancy type. Azure реплицирует ваши данные соответствующим образом.Azure will then replicate your data accordingly.
Миграция данных в хранилище, избыточное между зонами (ZRS), или из него требует другой стратегии.Migrating data to or from ZRS requires a different strategy. Миграция ZRS включает физическое перемещение данных из одной метки хранилища в несколько меток в пределах региона.ZRS migration involves the physical movement of data from a single storage stamp to multiple stamps within a region.
Имеется два основных варианта перемещения данных в хранилище ZRS или из него:There are two primary options for migration to or from ZRS:
- Ручное копирование или перемещение данных в новую учетную запись ZRS из имеющейся.Manually copy or move data to a new ZRS account from an existing account.
- Запрос на динамическую миграцию.Request a live migration.
Корпорация Майкрософт настоятельно рекомендует выполнять миграцию вручную.Microsoft strongly recommends that you perform a manual migration. Она обеспечивает большую гибкость, чем динамическая.A manual migration provides more flexibility than a live migration. При миграции вручную можно контролировать время миграции.With a manual migration, you’re in control of the timing.
Существует несколько вариантов выполнения миграции вручную:To perform a manual migration, you have options:
- Используйте имеющийся инструментарий, такой как AzCopy, одну из клиентских библиотек службы хранилища Azure или надежные сторонние инструменты.Use existing tooling like AzCopy, one of the Azure Storage client libraries, or reliable third-party tools.
- Если вы знакомы с HDInsight или Hadoop, подключите исходную и конечную (ZRS) учетную запись к своему кластеру.If you’re familiar with Hadoop or HDInsight, attach both source and destination (ZRS) account to your cluster. Затем выполните процесс копирования данных параллельно, используя такой инструмент, как DistCp.Then, parallelize the data copy process with a tool like DistCp.
- Разработайте собственный инструмент с помощью одной из клиентских библиотек службы хранилища Azure.Build your own tooling using one of the Azure Storage client libraries.
Миграция вручную может вызвать простой приложения.A manual migration can result in application downtime. Если приложению требуется высокий уровень доступности, корпорация Майкрософт также предоставляет возможность динамической миграции.If your application requires high availability, Microsoft also provides a live migration option. Динамическая миграция — это миграция «на месте».A live migration is an in-place migration.
Во время динамической миграции можно использовать свою учетную запись хранения, пока ваши данные переносятся между метками исходного и целевого хранилищ.During a live migration, you can use your storage account while your data is migrated between source and destination storage stamps. Во время миграции у вас по-прежнему будет тот же уровень устойчивости и заявленная в Соглашении об уровне обслуживания доступность, что и обычно.During the migration process, you have the same level of durability and availability SLA as you do normally.
Учитывайте следующие ограничения на динамическую миграцию:Keep in mind the following restrictions on live migration:
- Хотя корпорация Майкрософт незамедлительно отреагирует на запрос динамической миграции, нет никакой гарантии относительно времени ее завершения.While Microsoft handles your request for live migration promptly, there’s no guarantee as to when a live migration will complete. Если вам нужны данные, перенесенные в ZRS, на определенную дату, корпорация Майкрософт вместо этого рекомендует выполнить миграцию вручную.If you need your data migrated to ZRS by a certain date, then Microsoft recommends that you perform a manual migration instead. Как правило, чем больше данных в вашей учетной записи, тем дольше будет выполняться их перенос.Generally, the more data you have in your account, the longer it takes to migrate that data.
- Динамическая миграция поддерживается только для учетных записей хранения, использующих репликацию LRS или GRS.Live migration is supported only for storage accounts that use LRS or GRS replication. Если учетная запись использует RA-GRS, прежде чем продолжить, необходимо изменить тип репликации учетной записи на LRS или GRS.If your account uses RA-GRS, then you need to first change your account’s replication type to either LRS or GRS before proceeding. Этот промежуточный шаг удаляет вторичную конечную точку только для чтения, предоставляемую RA-GRS перед миграцией.This intermediary step removes the secondary read-only endpoint provided by RA-GRS before migration.
- Учетная запись должна содержать данные.Your account must contain data.
- Данные можно переносить только в рамках одного региона.You can only migrate data within the same region. Если вы хотите перенести данные в учетную запись ZRS, которая находится в регионе, отличном от учетной записи источника, тогда нужно выполнить миграцию вручную.If you want to migrate your data into a ZRS account located in a region different than the source account, then you must perform a manual migration.
- Только учетные записи хранения цен. категории «Стандартный» поддерживают динамическую миграцию.Only standard storage account types support live migration. Учетные записи хранения цен. категории «Премиум» необходимо переносить вручную.Premium storage accounts must be migrated manually.
Вы можете запросить динамическую миграцию через портал поддержки Azure.You can request live migration through the Azure Support portal. Выберите на портале учетную запись хранения, которую вы хотите преобразовать в ZRS.From the portal, select the storage account you want to convert to ZRS.
- Выберите Новый запрос в службу поддержкиSelect New Support Request
- Заполните раздел Основные сведения, основываясь на информации об учетной записи.Complete the Basics based on your account information. В разделе Служба выберите Storage Account Management (Управление учетными записями хранения) и ресурс, который необходимо преобразовать в ZRS.In the Service section, select Storage Account Management and the resource you want to convert to ZRS.
- Щелкните Далее.Select Next.
- Укажите следующие значения в разделе Проблема:Specify the following values the Problem section:
- Уровень серьезности. Оставьте значение по умолчанию.Severity: Leave the default value as-is.
- Тип проблемы. Выберите Перенос данных.Problem Type: Select Data Migration.
- Категория. Выберите Миграция в ZRS в пределах региона.Category: Select Migrate to ZRS within a region.
- Заголовок. Введите описательный заголовок, например Миграция учетной записи ZRS.Title: Type a descriptive title, for example, ZRS account migration.
- Сведения. Введите дополнительные сведения в поле Сведения, например «нужна миграция из [LRS, GRS] в ZRS в регионе __».Details: Type additional details in the Details box, for example, I would like to migrate to ZRS from [LRS, GRS] in the __ region.
- Щелкните Далее.Select Next.
- Проверьте правильность контактных данных в колонке Контактные данные.Verify that the contact information is correct on the Contact information blade.
- Нажмите кнопку Создать.Select Create.
Специалист службы поддержки свяжется с вами и предоставит любую необходимую помощь.A support person will contact you and provide any assistance you need.
Классическое хранилище ZRS. Устаревший вариант для обеспечения избыточности блочных BLOB-объектов.ZRS Classic: A legacy option for block blobs redundancy
Примечание
Корпорация Майкрософт объявит нерекомендуемыми и перенесет классические учетные записи ZRS 31 марта 2021.Microsoft will deprecate and migrate ZRS Classic accounts on March 31, 2021. Перед прекращением поддержки клиентам классического хранилища ZRS будут предоставлены дополнительные сведения.More details will be provided to ZRS Classic customers before deprecation.
Когда хранилище ZRS станет общедоступным в регионе, клиенты больше не смогут создавать классическую учетную запись ZRS на портале в этом же регионе.Once ZRS becomes generally available in a region, customers won’t be able to create ZRS Classic accounts from the portal in that region. Использование Microsoft PowerShell и Azure CLI для создания классических учетных записей ZRS является возможным, пока классическое хранилище ZRS не будет объявлено нерекомендуемым.Using Microsoft PowerShell and Azure CLI to create ZRS Classic accounts is an option until ZRS Classic is deprecated.
В классическом хранилище ZRS данные асинхронно реплицируются в центрах обработки данных в пределах одного или двух регионов.ZRS Classic asynchronously replicates data across data centers within one to two regions. Реплицируемые данные недоступны, если корпорация Майкрософт не инициирует отработку отказа в дополнительном регионе.Replicated data may not be available unless Microsoft initiates failover to the secondary. Классическую учетную запись ZRS невозможно преобразовать в учетную запись хранилища LRS, GRS или RA-GRS и наоборот.A ZRS Classic account can’t be converted to or from LRS, GRS, or RA-GRS. Кроме того, она не поддерживает использование метрик или ведение журналов.ZRS Classic accounts also don’t support metrics or logging.
Классическое хранилище ZRS доступно только для блочных BLOB-объектов в учетных записях хранения общего назначения версии 1 (GPv1).ZRS Classic is available only for block blobs in general-purpose V1 (GPv1) storage accounts. Дополнительные сведения об учетных записях хранения см. в статье Общие сведения об учетной записи хранения.For more information about storage accounts, see Azure storage account overview.
Чтобы вручную перенести данные учетной записи ZRS в учетную запись LRS, классическое хранилище ZRS, GRS или RA-GRS и обратно, используйте один из следующих инструментов: AzCopy, Обозреватель службы хранилища Azure, Azure PowerShell или Azure CLI.To manually migrate ZRS account data to or from an LRS, ZRS Classic, GRS, or RA-GRS account, use one of the following tools: AzCopy, Azure Storage Explorer, Azure PowerShell, or Azure CLI. Можно также создавать собственные решения для миграции с использованием одной из клиентских библиотек службы хранилища Azure.You can also build your own migration solution with one of the Azure Storage client libraries.
См. такжеSee also
docs.microsoft.com
s3ql — файловая система на базе облачного хранилища / Selectel corporate blog / Habr

Описание
При помощи S3QL вы можете создать файловую систему на базе облачного хранилища Selectel Storage, которую можно смонтировать в любой современной версии OS Linux, FreeBSD или Mac OS X.
Возможности
Прозрачность
S3QL практически не отличима от локальной файловой системы. Она поддерживает hardlinks, symlinks, стандартные системные права доступа, расширенные атрибуты, а также файлы размером до 2TB.
Динамический размер
Размер файловой системы не ограничен, он увеличивается при сохранении данных и уменьшается после их удаления. На локальном диске хранятся кэшированные данные.
Компрессия
Перед сохранением в облачное хранилище данные могут быть сжаты (поддерживается lzma, bzip2, zlib).
Шифрование
После компрессии (но до загрузки в хранилище) данные могут быть зашифрованы AES алгоритмом шифрования с 256 битным ключем. Также используется дополнительный SHA256 HMAC checksum для защиты данных от внешних манипуляций.
Дедупликация данных
Если несколько файлов имеют одинаковое содержимое, то повторяющиеся данные будут записаны только один раз, что позволяет эффективно хранить большое количество схожих данных, при минимально занятом объеме. Данный функционал работает как на целых файлах, так и на блоках данных, которые повторяются в разных файлах.
Copy-on-Write/Snapshotting
S3QL может быстро копировать целые директории без использования дополнительного диского пространства. Только при внесении изменений в одну из копий, измененные данные будут занимать дополнительное место.
Защита данных от изменения
Вы можете запретить изменение данных для каталогов, например, для хранения бэкапов, которые будут защищены от случайного удаления.
Высокая производительность независимо от сетевых задержек
Операции, связанные с изменением структуры (создание директорий, перемещение файлов и изменение прав) выполняются очень быстро, так как они не требуют сетевого взаимодействия.
Поддержка медленных каналов связи
S3QL разбивает содержимое файлов на маленькие блоки и локально кеширует их, что уменьшает количество сетевых обращений для чтения и записи данных, а также снижает объем передаваемых данных, так как только измененные блоки данных передаются по сети.
Установка
Пакет s3ql доступен в репозиториях Debian (sid) и Ubuntu, установка из которых сводится к обычному запуску apt-get install s3ql.
Если у вас в репозитории нет данного пакета или вас не устраивает его версия, то всегда можно установить вручную, воспользовавшись инструкцией.
Создание файловой системы
mkfs.s3ql swift://auth.selcdn.ru/containerПо умолчанию, все иноды разбиваются на блоки в 10МБ, этот параметр можно задавать при создании файловой системы —max-obj-size. После создания файловой системы этот параметр изменить нельзя.
Также по умолчанию, при создании файловой системы вам потребуется ввести пароль для шифрования данных, но, если вам не требуется шифрование, то можно указать опцию —plain и тогда данные не будут шифроваться, что может увеличить производительность файловой системы.
Монтирование
Подключить облачное хранилище очень просто:
mount.s3ql swift://auth.selcdn.ru/container /mnt/containerКомпрессия
При монтировании файловой системы можно указать необходимый алгоритм сжатия данных, но надо понимать, что чем сильнее компрессия, тем больше нагрузка на процессор и меньше скорость при сохранении данных. Алгоритмы сжатия соотносятся друг с другом следующим образом: lzma медленый, но имеет лучшую компрессию относительно bzip2, а bzip2, в свою очередь, имеет лучшую компрессию относительно zlib, но медленнее его. Для максимальной производительности файловой системы лучше выбирать алгоритм сжатия исходя из пропускной способности сети
Кеширование
S3QL поддерживает локальный кеш данных файловой системы для ускорения доступа. Кеш основан на блоках данных, так что возможно, что только части файлов находятся в кеше.
Дополнительные команды
s3qladm — используется для изменения пароля для шифрования, обновления файловой системы, удаление всех данных и загрузки метаданных из хранилища;fsck.s3ql — иногда после потери сетевого соединения с хранилищем или после падения самого s3ql необходимо делать проверку файловой системы, без которой нет возможности дальнейшего монтирования;s3qlcp — позволяет реплицировать каталоги в рамках одной s3ql файловой системы;s3qlctrl — для управления текущими настройками смонтированой файловой системы, например, размер кеша и уровень логирования, а также позволяет принудительное выполнение flushcache и загрузку мета-данных в хранилище;s3qllock — делает папки неизменяемыми;s3qlrm — рекурсивно удаляет файлы и директории на файловой системе s3ql, также может удалить каталоги, которые отмечены как неизменяемые;s3qlstat — отображает статистику для смонтированой файловой системы.Отмонтирование
umount.s3ql /mnt/containerОтмонтировать файловую систему может только тот пользователь, который её примонтировал или root. При отмонтировании происходит дозагрузка данных в хранилище, которые еще не были записаны — при этом команда блокируется до момента завершения загрузок.
Итог
Плюсы
- шифрование на стороне клиента, что обеспечивает хранение полностью зашифрованых данных в хранилище;
- при помощи дедупликации данных можно сократить расходы на хранение данных в облаке относительно традиционного подхода;
- кеширование данных позволяет сократить затраты на исходящий трафик для хранилища.
Недостатки
- Нет возможности множественного монтирования (одновременно на разных машинах).
P.S. Для более подробного ознакомления с s3ql можно воспользоваться его документацией
Источник статьи.
habr.com
Домашнее хранилище данных — возможные варианты
Наверняка многие рано или поздно сталкивались с проблемой, где хранить накопленные непосильным трудом фотографии, коллекции музыки, результаты профессиональной деятельности, фильмотеку и т. п. Простая замена жесткого диска более емким вопрос решает, но как-то не очень, и ненадолго. Внешний диск тоже не лучшее решение. Одно его неудачное падение – и происходит катастрофа. Облачные хранилища отчасти помогают, но и тут достаточно ограничений. О том, какое домашнее хранилище данных выбрать, какие они бывают, сегодня и поговорим.
Суть проблемы
Думаю, практически у всех постепенно копятся какие-либо файлы, которые очень хочется сохранить, и чтобы с которыми ничего не произошло. Взять хотя бы домашний фото- и видеоархив. Мир меняется, и на смену альбомам с бумажными фотографиями пришли современные технологии. С ними же пришли и объемы, которые занимает все это «хозяйство». Фотографии «весят» все больше, видеоролики, снятые в FullHD (про 4K и выше даже говорить страшно) тоже все больше поражают количеством гигабайт.
Возникает два вопроса: где это хранить и… опять-таки, где хранить то же самое, но уже в виде резервных копий. Надеюсь, священная мантра «обязательно делайте бэкапы» для вас действительно священна.
Свежекупленный диск на 4 (6, 8 и т. д.) терабайт кажется бездонным. Поначалу. Если туда складировать коллекцию любимой музыки (особенно если вы почитатель действительно качественно звука и до MP3 не «опускаетесь»), аудиокниги, фильмы, сериалы и проч., то быстро оказывается, что диск то уже почти заполнен. А резервные копии? Их же надо хранить на ДРУГОМ носителе.
Значит, надо как минимум 2 диска, или надо распихивать все свое хозяйство по облачным хранилищам. Вот только бесплатно дается места там совсем немного. Правда, можно заплатить n-ую сумму и купить много сотен гигабайт или даже терабайты на одном-двух, но вы готовы на эти траты? А вдруг что-то произойдет, и доступ к данным прервется? Да и сам факт, что что-то личное лежит где-то там, неизвестно где…
В итоге, вырисовывается понимание того, что необходимо некое устройство, способное хранить терабайты важной информации, которая должна быть доступна в любой момент, ну и гарантировать высокую степень сохранности всего записанного.
Надеяться на то, что жесткий диск, какой бы самый крутой он не был, не откажет в неподходящий (а когда он бывает подходящим?) момент наивно. Резервные копии спасают, но давайте согласимся, что бэкапить ВСЕ – слишком накладно. То, что никак нельзя восстановить, или это потребует много времени и средств – обязательно, а остальное?
Вот это остальное вполне можно доверить дискам, но не просто нескольким отдельным накопителям, а работающим совместно в RAID массиве. С большой долей уверенности можно сказать, что при выходе из строя какого-либо накопителя информация не исчезнет. О том, что такое RAID, какие они бывают, их достоинствах и недостатках поговорим как-нибудь отдельно.
Итак, на данный момент уже сформировался ряд требований, достаточный для того, чтобы заняться проблемой организации домашнего хранилища данных. Т. е., это будут жесткие диски, собранные в RAID-массив, и оптимальнее будет разместить их в отдельном корпусе, а не нагружать домашний рабочий/игровой десктоп еще и функциями дискового хранилища.
Теперь давайте посмотрим на варианты решения задачи. В данном случае я веду речь о чисто домашнем использовании дискового хранилища. Для использования в офисе или для более серьезных задач типа сервера для баз данных нужен несколько иной подход. В данном случае все проще — файловое хранилище. Из приятных бонусов желательно иметь возможность его использования в качестве медиаплеера, возможно, веб-сервера. Поехали.
Домашнее хранилище самолепное — из того, что удалось наскрести по сусекам
У многих после очередного апгрейда компьютера остаются комплектующие, которые уже морально (но не физически) устарели, современным реалиям не соответствуют, но вполне могут послужить для сборки чего-то… Да чего, собственно, думать то? Core i7 или AMD Ryzen для дискового хранилища избыточны. Правда, если у вас отработал свое старенький i5, то почему бы и нет.
Если из валяющейся кучки комплектующих вполне можно собрать полноценный компьютер, то можно остановиться на таком варианте. Цели описывать самостоятельную сборку и настройку такого сетевого хранилища у меня сейчас нет, это тема отдельная и довольно обширная. Сейчас только в общих словах.
Итак, основные требования к такому компьютеру несколько специфические. Высокая производительность не требуется, и тем более, если планируется работа собираемого хранилища в режиме 24/7, то чем менее мощной оно будет, тем меньше платить за электричество.
Важно только, чтобы была возможность собрать диски в массив, и при этом желательно, чтобы этот RAID был не «софтовым». Если материнская плата поддерживает организацию массива – отлично, если же нет, то все же желательно пойти на некоторые расходы и обзавестись соответствующим контроллером. Останется еще озаботиться корпусом ну и, собственно, самими дисками.
Наверняка многие скажут, что для выполнения функций сетевого хранилища оптимальным выбором станет ОС Nas4Free. Кстати, можно будет обойтись и софтовым RAID. Во многих случаях этого действительно будет достаточно. Как вариант – что-то подобное на основе Linux.
Проблема только в том, что тем, кто всю жизнь просидел на «окошках», эта ось гораздо ближе и понятнее, и не надо осваивать незнакомую систему для того, чтобы выполнить все необходимые действия. А времени для этого может потребоваться не так уж и мало. Потому не буду так уж однозначно сбрасывать со счетов ОС Windows, особенно если сетевое хранилище должно будет выполнять еще какие-то мелкие сопутствующие задачи.
Из минусов самостоятельной сборки хранилища можно назвать некоторую «колхозность» получаемого результата. Впрочем, если место такого компьютера где-нибудь в шкафу, за шкафом или в какой-нибудь кладовке, то эстетические качества становятся вообще малозначимыми. Главное, чтобы работало стабильно.
Скорее всего, не будет возможности «горячей» замены дисков. Насколько принципиально вам такое ограничение? Да, для вытаскивания вышедшего из строя накопителя и установки нового придется открыть корпус, выкручивать диск, ставить новый. Но как часто это приходится делать?
Заморачиваться с такой сборкой имеет смысл только в том случае, если почти все комплектующие (диски, скорее всего, все равно покупать отдельно), у вас уже есть. Ну или что-то задешево вполне можно докупить на барахолке, например, процессор, планку памяти уже неактуального форм-фактора, естественно, убедившись в работоспособности.
Собирать такую систему с нуля, думаю, смысла большого нет. Экономии может не получиться.
DAS – готовое, но недорогое
Всем знакомы переносные жесткие диски, подключаемые по USB. Многие ими пользуются, да и у меня их есть штуки три, причем один такой диск уже работает лет 5 и радует безотказностью и здоровьем.
andiriney.ru
Консольная версия Cyberduck: работа с облачным хранилищем

В предыдущих публикациях мы уже неоднократно рассказывали об утилитах, которые могут быть использованы для работы с нашим облачным хранилищем (1 и 2). В одной из статей мы уже упоминали утилиту Cyberduck — удобный файловый менеджер для MacOS , Linux и Windows, работающий с протоколами FTP, SFTP, WebDAV, OpenStack Swift и AmazonS3. С нашего официального сайта можно также скачать профиль, с помощью которого Cyberduck автоматически конфигурируется для работы с нашим облачным хранилищем.
Пользователи в большинстве своём знакомы с графической версией Cyberduck. Совсем недавно появилась и консольная версия. В этой статье мы расскажем о её возможностях и покажем, как её можно использовать для работы с хранилищем.
Общая информация
Консольная версия Cyberduck работает со всеми основными операционными системами — MacOS, Windows и Linux. Программа может использоваться в качестве FTP и SFTP-клиента, а также для работы с различными сервисами облачного хранения данных.
Документация к консольной версии Cyberduck опубликована на официальном сайте, но, к сожалению, о большинстве важных функций в ней рассказано не так подробно, как хотелось бы. Ниже мы расскажем о том, какие операции с нашим хранилищем можно выполнять с её помощью, а также дадим подробные разъяснения по синтаксису основных команд.
Установка
Mac OS
Консольная версия Cyberduck для MacOS устанавливается с помощью менеджера пакетов Homebrew:
$ brew install duck
Linux
В этой статье мы опишем процедуру установке для Ubuntu 14.04; пользователей других дистрибутивов отсылаем к официальной документации.
Чтобы установить консольную версию Cyberduck, добавим сначала соответствующий репозиторий:
$ echo 'deb https://s3.amazonaws.com/repo.deb.cyberduck.io nightly main'>/etc/apt/sources.list $ echo 'deb https://s3.amazonaws.com/repo.deb.cyberduck.io stable main'>/etc/apt/sources.list
Затем добавим ключ:
$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys FE7097963FEFBE72
и выполним команды
$ sudo apt-get update $ sudo apt-get install duck
Основные операции с облачным хранилищем
Все команды для работы с облачным хранилищем имеют следующий вид:
$ duck -<аргумент> swift://<имя пользователя>@auth.selcdn.ru/<путь к объекту> -p<пароль>
После ввода команды программа запросит имя владельца учётной записи (Tenant). В ответ нужно указать пользователя, под учётной записью которого осуществляется доступ к хранилищу. Диалоговый режим можно вообще отключить — для этого используется опция -q.
Получение списка файлов в контейнере
Чтобы получить список файлов, хранимых в некотором контейнере, используется опция -l (или −−list):
$ duck -l swift://[email protected]/<путь к контейнеру> -p <пароль> Listing directory images… 1.jpg 2.jpg 3.png
Скачивание файла
Для скачивания файла из хранилища используется команда вида:
$ duck -d swift://[email protected]/ <путь к файлу> <имя файла> -p <пароль>
Открытие файла для редактирования на локальной машине
С помощью консольной версии CyberDuck можно открывать файлы для редактирования на локальной машине; по завершении редактирования в хранилище будет загружена обновленная (со всеми внесёнными изменениями) версия файла. Для этого используется опция −−edit:
$ duck --edit swift://<имя пользователя>@auth.selcdn.ru/<путь к файлу> -p <пароль>
Файл будет открыт в приложении, используемом в системе для данного типа файлов; загрузка изменённая версии начинается автоматически.
Эта функция Cyberduck будет особенно интересной для пользователей, размещающих в нашем хранилище статические сайты. Чтобы, например, быстро отредактировать текст на сайте, достаточно выполнить указанную выше команду, внести изменения в нужные файлы и сохранить их.
Загрузка объекта в хранилище
Операция загрузки выполняется при помощи команды вида:
$ duck --upload swift://[email protected] <полный путь к объекту в хранилище> <путь к объекту на локальной машине> -p <пароль>
Обратим особое внимание на то, что при загрузке объекта нужно указывать полный путь к месту хранения этого самого объекта. Например, если мы хотим сохранить файл myimage.png в контейнере images, то путь к нему нужно указать так: /images/ myimage.png.
Большие (размером более 2ГБ) объекты Cyberduck загружает в хранилище по частям.
Версии объектов и резервное копирование
Консольная версия Cyberduck представляет собой удобный инструмент для резервного копирования и архивирования данных. Рассмотрим эти функции более подробно на конкретных практических примерах.
Представим себе, что у нас на локальной машине имеется директория, содержимое которой нужно периодически копировать в облачное хранилище. Для этого написан специальный скрипт и добавлено задание Cron, которое отправляет резервную копию к хранилище каждый день в указанное время.
Скрипт выглядит так:
#!/bin/bash SWIFT_USERNAME=имя пользователя SWIFT PASSWORD=пароль для входа в хранилище SWIFT_AUTH_URL=auth.selcdn.ru BACKUP_PATH=путь к месту хранения бэкапа LOCAL_PATH=путь к папке на локальной машине duck --upload swift://$SWIFT_USERNAME@$SWIFT_AUTHURL/$BACKUP_PATH/ $LOCAL_PATH --existing rename --password $SWIFT_PASSWORD -q
Обратим внимание на синтаксис команды duck. В приведённом примере используются ключ —existing, который указывает, что делать с уже имеющимися в хранилище файлами. Опция rename переименовывает уже имеющуюся резервную копию, добавляя к её имени время и дату.
С помощью cyberduck можно осуществлять и дифференциальное резервное копирование. Для этого используются опция compare:
$ duck --upload swift://[email protected] <полный путь к объекту в хранилище> <путь к файлу на локальной машине> --existing compare -p <пароль>
При выполнении приведённой команды программа сравнит загружаемую резервную копию с уже имеющейся по размеру, дате изменения и контрольной сумме. Если парамерты отличаются, то старая версия будет удалена, а новая — загружена в хранилище.
При использовании опции skip в хранилище будут загружены только новые файлы (те, которые появились в папке на локальной машине после предыдущей загрузки). Уже имеющиеся файлы не будут загружены, даже если на локальной машине они были изменены.
Наконец, опция overwrite просто удалит из хранилища имеющуюся резервную копию и загрузит новую.
Синхронизация локальных файлов с файлами в хранилище
Синхронизация файлов — это процесс, в результате которого две директории, одна из которых находится на локальной машине, а другая — в хранилище, будут содержать одинаковый набор файлов в одной и той же версии с наиболее свежей датой изменений. Если на локальной машине какие-либо файлы были изменены, добавлены или удалены, эти же самые файлы будут изменены, добавлены или удалены в хранилище, и наоборот.
Синхронизация выполняется при помощи команды:
$ duck --synchronize swift://<[email protected]>/<путь к папке в хранилище> <путь к папке на локальной машине>
С помощью функции синхронизации можно поддерживать помещённые в хранилище резервные копии данных с локальной машины в актуальном состоянии.
Вот пример простого скрипта:
#bin/bash SWIFT_USERNAME=имя пользователя SWIFT PASSWORD=пароль для входа в хранилище SWIFT_AUTH_URL=auth.selcdn.ru BACKUP_PATH=путь к месту хранения бэкапа LOCAL_PATH=путь к папке на локальной машине duck --synchronize swift://$SWIFT_USERNAME@SWIFT_AUTHURL/$BACKUP_PATH $LOCAL_PATH --password $SWIFT_PASSWORD -q
Достаточно добавить соответствующее задание в cron — и данные будут автоматически синхронизироваться с указанной периодичностью.
Описываемая функция будет полезной и для тех, кто размещает в хранилище статические сайты. Чтобы обновить сайт, достаточно внести соответствующие изменения в файлы на локальной машине, а затем выполнить команду синхронизации.
Копирование файлов
Чтобы скопировать файл из одного контейнера в другой , используется команда вида:
$ duck --сopy swift:// <[email protected]>/<полный путь к файлу> <[email protected]>/<путь к новому месту хранения> -p <пароль>
Опция -v
Чтобы на консоль выводилась информация обо всех HTTP-запросах, осуществляемых при выполнении операций с хранилищем, а также об ответах на них, используется опция -v (или —verbose). Это помогает понять, как с хранилищем взаимодействуют сторонние приложения.
Заключение
Консольная версия Cyberduck представляет собой удобный инструмент для работы с облачным хранилищем, обладающий широкими возможностями. Появление такого инструмента должно порадовать пользователей ОС Windows. Дело в том, что для Windows но недавнего времени вообще не было консольных программ для работы с облачными хранилищами на базе OpenStack Swift, и для этих целей приходилось пользоваться FTP-клиентами, что не всегда удобно.
Надеемся, что вы оцените консольную версию Cyberduck по достоинству будете пользоваться ей в повседневной практике.
Актуальная инструкция по работе с Cyberduck лежит в нашей базе знаний.
blog.selectel.ru
Бесплатное облачное хранилище на 1000 ГБ
Сегодняшняя статья посвящена бесплатному облачному хранилищу с объемом в 1000гб или 1ТБ. Это действительно правда.
Компания mail взяла пример с других известных компаний: google, yandex и т. д. Которые своим пользователям предоставляют бесплатное облачное хранилище.
Если гугл предоставляет 5гб, yandex -10, то mail переплюнул их всех и решил предоставлять 1000 гб.
Изначально они предоставляли 100гб, но в честь новогодних праздников в период с 20 декабря по 20 января действует акция по увеличению вашего дискового пространства до 1ТБ.Причем по окончании акции подаренное дисковое пространство остается у пользователей. Этого объема хватит для того что бы почти ко всем вашим данным был доступ: на работе, отдыхе, командировке или на отдыхе.
Если на вашем ноутбуке или другом устройстве не достаточно места для хранения ваших данных, то вы можете сполна воспользоваться данной услугой.
Для использования облачного хранилища необходимо иметь почтовый ящик от mail. Если же у вас его нет, зарегистрироваться у вас не составит труда.
Во время регистрации попросят предоставить телефон, не переживайте, туда придет простое смс с подтверждением об окончании регистрации.
Инструкция по регистрации в облачном хранилище
Данный сервис доступный по этой адресу cloud.mail.ru
После окончания регистрации вам будет предоставлено 100гб, но по условиям акции для расширения дискового пространства необходимо скачать приложение для любого из устройств, будь это: компьютер, ноутбук, смартфон, планшет и т. д.
После скачивания и установки приложения ваше дисковое пространство автоматически увеличится.
Раньше компания mail вместе с установкой любого приложения устанавливала кучу разных программ, всяких там «спутников» или «защитников», то сейчас все координально изменилось, вместе с установкой данного приложения на ваш ноутбук не ставится ни одного «левого» приложения.
Еще очень важной особенностью есть то, что сервис поддерживает почти все известные ОС: Windows, Mac, Linux.
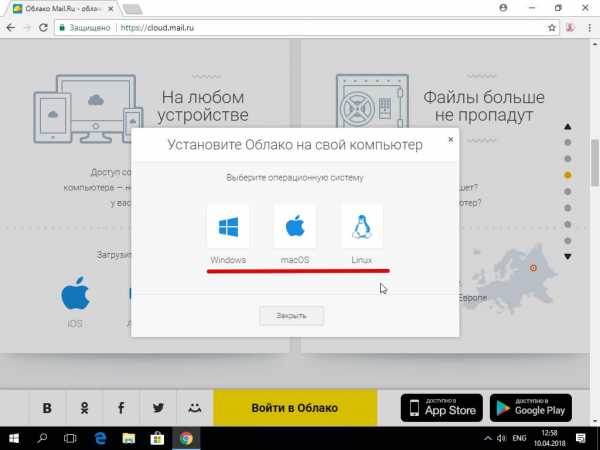
Как вы видите главной особенностью есть то, что сервис поддерживает операционные системы Linux, что я не могу сказать про google, для того чтобы пользоваться гугл диском пользователям unix систем необходимо купить стороннее приложение.
Так же имеется возможность хранить любые файлы в облачном хранилище, видео или изображения, презентацию и музыку.
Таблица сравнения характеристик облачного хранилища.
Теперь все что я описал я предоставлю в цифрах и небольшом описании
| Характеристика | Описание |
| Объем диска | 100 гб |
| Возможность увеличения | Да, до 1000Гб |
| Синхронизация | Синхронизации происходит с любой папкой |
| Операционные системы | Windows, Mac, Linux |
| Расшаривать файлы (открывать доступ) | Имеется, необходим почтовый ящик от mail |
| Возможность просматривать файлы | Да |
| Возможность редактировать файлы | Нет |
| Скорость загрузки файлов | Зависит от вашего интернета. При тестирование скорость доходила до 10 метров в секунду. |
| Возможность скачивать файлы | Да |
| Имеется плохая закономерность | При загрузке фотографий (большого количества одновременно) довольно часто выдает ошибку загрузки файла. Примерно из 1000 загружаемых файлов 50 будет не загружено. |
Ну вот на этом и все. Успейте зарегистрироваться и пользоваться бесплатно 1000 гб памяти.
Согласитесь это очень много, учесть что Google, Yandex и другие предоставляют максимум 10гб, за остальное необходимо платить.
laptop-info.ru