NVIDIA Volta и другие анонсы NVIDIA для ИИ
NVIDIA Volta и другие анонсы NVIDIA для ИИ — GTC 2017
На этой неделе в Сан-Хосе проходит ежегодная конференция NVIDIA по GPU-технологиям. 7000 участников, 600 технических сессий, 150 стендов, 310 сессий по искусственному интеллекту и 67 лабораторий по технологиям глубокого обучения (Deep Learning).
Сегодня, в рамках выступления CEO NVIDIA Дженсена Хуанга, были представлены новая архитектура графических процессоров NVIDIA Volta и серия аппаратно-программных решений, призванных ускорить и упростить работу с искусственным интеллектом.
Архитектура NVIDIA Volta – Volta – это самая мощная в мире архитектура GPU, призванная стать катализатором новой волны достижений в области искусственного интеллекта и высокопроизводительных вычислений. Первый процессор на базе Volta – это GPU для дата-центров Tesla V100, который обеспечивает сверхвысокую скорость и масштабируемость обучения и инференса глубоких нейронных сетей, а также ускоряет высокопроизводительные и графические вычисления.
В основе Volta, седьмого поколения графических архитектур NVIDIA, находится 21 млрд транзисторов, обеспечивающих производительность задачах в глубокого обучения, эквивалентную 100 CPU. Пиковая производительность Volta в 5 раз выше архитектуры Pascal — текущей графической архитектуры NVIDIA, и в 15 раз выше Maxwell, представленной два года назад. Эта цифра вчетверо больше того, что предсказывал закон Мура.
Volta станет новым стандартом высокопроизводительных вычислений. Благодаря объединению ядер CUDA® и нового ядра Volta Tensor в унифицированной архитектуре, один сервер на базе GPU Tesla V100 сможет заменить сотни центральных процессоров в высокопроизводительных вычислениях.
Ключевые технологии GPU Tesla V100,которые позволили преодолеть 100-терафлопсный рубеж в
задачах глубокого обучения:
- Специализированные ядра Tensor, созданные для ускорения работы искусственного интеллекта. Оснащенный 640 ядрами Tensor, процессор V100 обеспечивает производительность 120 терафлопс в глубоком обучении, что эквивалентно производительности 100 CPU.
- Новая архитектура GPU с более чем 21 млрд транзисторов. Она объединяет ядра CUDA и Tensor в рамках унифицированной архитектуры, обеспечивая производительность суперкомпьютера для ИИ в одном GPU.
- NVLink™
- Память 900 ГБ/с HBM2 DRAM, разработанная совместно с Samsung, увеличивает полосу пропускания на 50% по сравнению с предыдущим поколением.
- Оптимизированное под Volta программное обеспечение, включая CUDA, cuDNN и TensorRT™, которое ведущие фреймворки и приложения для ускорения ИИ и исследований могут взять на вооружение.
Подробнее об архитектуре NVIDIA Volta — https://devblogs.nvidia.com/parallelforall/inside-volta/.
Новые DGX системы на базе Volta – Анонсирована новая линейка суперкомпьютеров с искусственным интеллектом NVIDIA DGX AI с исключительными вычислительными возможностями. Системы построены на GPU NVIDIA Tesla V100 на базе новой архитектуры Volta и используют полностью оптимизированное для задач ИИ программное обеспечение. Производительность такой системы втрое выше, чем у предыдущего поколения DGX, и соответствует мощности примерно 800 CPU в рамках всего одной системы.
Платформа NVIDIA GPU Cloud – NVIDIA GPU Cloud (NGC) – это облачная платформа, которая предоставляет разработчикам удобный доступ — с помощью ПК, системы DGX или облака — к полноценному программному набору инструментов внедрения ИИ. Благодаря NGC разработчики смогут легче получать доступ к новейшим оптимизированным фреймворкам и передовым ускорителям.
Сотрудничество с Toyota – Toyota начнет внедрение автомобильной вычислительной платформы с поддержкой искусственного интеллекта NVIDIA DRIVE™ PX в системы автономного вождения, запланированные к выводу на рынок в течение ближайших лет. Команды инженеров обеих компаний уже работают над созданием программного обеспечения на высокопроизводительной ИИ-платформе NVIDIA, которое позволит лучше понимать огромные объемы данных, получаемых с автомобильных датчиков, и автономно справляться с широким спектром ситуаций на дороге.
Для того чтобы справляться с задачами подобного уровня вычислительной сложности, в прототипах автомобилей зачастую используют мощные компьютеры, которые занимают весь багажник. Платформа NVIDIA DRIVE PX на базе процессора нового поколения Xavier легко помещается в руке, обеспечивая при этом 30 млрд операций глубокого обучения в секунду.
SAP Brand Impact – Проект SAP Brand Impact на базе решений NVIDIA для глубокого обучения измеряет атрибуты бренда (например, логотипы) практически в реальном времени. Эффективный анализ видеоконтента стал возможен благодаря использованию для анализа глубоких нейросетей, обученных на NVIDIA DGX-1 и TensorRT.
Isaac Robotics Simulator – В нашем новом имитаторе роботов по имени Isaac применяются сложные игровые и графические технологии, чтобы быстро и эффективно обучать машины в сымитированных условиях реального мира. NVIDIA также представила набор референсных платформ на базе NVIDIA Jetson™, которые позволят ускорить процесс создания умных машин.

ИИ для трассировки лучей – С помощью ИИ мы ускоряем трассировку лучей (ray tracing) и получение высокодетализированных изображений. Метод трассировки лучей генерирует изображение фотореалистичного качества, но требует больших вычислительных ресурсов, при этом на изображении может появляться шум. Благодаря использованию алгоритмов глубокого обучения в NVIDIA Iray, шумоподавление становится доступным в режиме реального времени.
Project Holodeck – Project Holodeck – это фотореалистичное VR-окружение для совместной работы, которое позволяет видеть, слышать и осязать виртуализированные объекты. Среда Holodeck позволяет создателям импортировать модели высокой четкости и высокого разрешения в VR для совместной работы над ними вместе с коллегами.
Другие новости и анонсы GTC 2017 читайте в нашей группе Вконтакте.
Скачать презентацию NVIDIA.
Фотографии с мероприятия: https://www.flickr.com/photos/nvidia.
Производительность NVIDIA Volta GV100 может достигнуть 9,5 терафлопс
Как известно, следующим после Pascal поколением графических процессоров NVIDIA является Volta. Впрочем, к современным чипам название «графический процессор» применимо всё меньше — с тех пор, как их архитектура стала полностью унифицированной и программируемой, они прочно утвердились в различных проектах суперкомпьютеров, некоторые из которых уже вступили в строй и вовсю заняты научными и другими сложными вычислениями. Создавая свой первый чип Pascal GP100, NVIDIA уделила больше внимания его вычислительным возможностям, нежели графическим, и, похоже, первенца в семействе Volta, чип GV100, ожидает аналогичный подход.
Уже подтверждено, что GV100 станет сердцем, а точнее, сердцами суперкомпьютеров Summit в Национальной лаборатории Ок-Ридж (Oak Ridge National Laboratory) и Sierra в Ливерморской национальной лаборатории (Lawrence Livermore National Laboratory). Первый проект должен войти в рабочую стадию в начале 2018 года и развить пиковую мощность 200 петафлопс, что существенно превышает показатель самого быстрого сегодняшнего китайского суперкомпьютера Sunway TaihuLight, чьи возможности оцениваются в 125,4 петафлопса. К сожалению, о характеристиках и архитектуре GV100 мы до сих пор знаем не так много, как хотелось бы, но кое-какие сведения о проекте Summit позволяют сделать некоторые выводы.
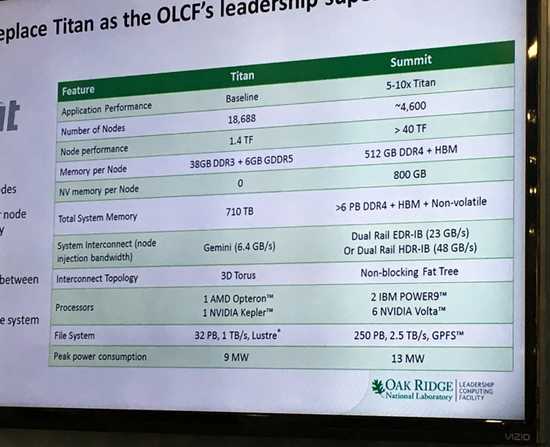
Тот самый слайд
Лаборатория в Ок-Ридже опубликовала слайд, на котором Summit сравнивается с суперкомпьютером Titan, базирующимся на чипах Kepler GK110. Состоит он из 18688 узлов, мощность каждого из них составляет 1,4 терафлопса. На том же плакате указаны спецификации Summit: 4600 узлов с мощностью более 40 терафлопс на узел. Указано также, что в каждом узле будет 512 Гбайт памяти DDR4, 800 Гбайт энергонезависимой памяти и некий объём памяти HBM (речь, разумеется, идёт о HBM2). Основой каждого узла станут пара процессоров IBM POWER9 и шесть процессоров NVIDIA Volta. Чипы POWER9, помимо традиционных линий PCI Express (версия 4.0) имеют и 48 линий интерфейса Bluelink, который будет работать в режиме NVLink 2.0 и соединять их с процессорами Volta, что позволит процессорам различных архитектур делить общее пространство памяти, практически не теряя в скорости: пропускная способность может составлять от 80 до 200 Гбайт/с.

Использование NVLink экономит энергию и повышает производительность
Потребляемая Summit мощность составит 13 мегаватт — всего на 4 мегаватта больше, нежели у Titan, при более чем десятикратном превосходстве в производительности. Как мы знаем, NVIDIA объявила о том, что GV100 будет демонстрировать эффективность 72 гигафлопса на ватт при операции перемножения матриц с одинарной точностью (Single precision floating General Matrix Multiply). Для GP100 этот показатель равен 42 гигафлопса на ватт. Нетрудно посчитать, приняв за основу теплопакет GV100 на уровне 300 ватт, что этот чип в теории может достичь производительности 9,5 терафлопс на вычислениях двойной точности (FP64). Шесть чипов GV100 при потреблении не выше 300 ватт на чип как раз и дадут упомянутые на плакате «более 40 терафлопс», а точнее, в теории, смогут выдать 57,2 терафлопса. Даже при конфигурации с теплопакетом 200 ватт и на 20‒25 % более низкой производительности производительность узла составит 45,6 терафлопс, так что у создателей Summit явно есть задел по части экономии электроэнергии при сохранении заявленных характеристик. По крайней мере, такой подход может существенно облегчить работу холодильных установок Summit.
Источник: servernews.ru
itoboz.com
Новости про NVIDIA и Volta — МИР NVIDIA
Пользователь Reddit с ником dustinbrooks опубликовал фото прототипа видеокарты, который подписал как «это тестировал приятель, который работает на компанию, тестирующую платы NVIDIA». При этом он спросил у сообщества, что же это за устройство. И конечно, энтузиасты заинтересовались.
Видеокарта, как следует из маркировки возле коннектора PCI-Express x16, сделана NVIDIA. На снимке также видны три 8-контактных разъёма дополнительного питания и гигантская схема управления питания, охлаждаемая четырьмя вентиляторами. Чип разглядеть нельзя, но скорее всего речь идёт о GV102, наследнике GP102. Он окружён двенадцатью микросхемами GDDR6 с маркировкой D9WCW, что означает MT61K256M32JE-14:A. Это 8 гигабитные микросхемы GDDR6 от Micron с напряжением 1,35 В и пропускной способностью в 14 Гб/с. Это значит, что в сумме память будет работать на скорости 672 ГБ/с, что быстрее, чем 484 ГБ/с в Vega 64.
Прототип на базе GV102
Наверху платы расположился коннектор NVLink, однако в нём нет половины контактов, а значит, последовательно соединить несколько видеокарт будет невозможно.
Поражает энергопотребление платы — 525 Вт. Учитывая массу тестовых выходов и джамперов, можно допустить, что плата используется для проверки производительности при разном энергопотреблении, так что конечный продукт должен потреблять несколько меньше.
Размер GPU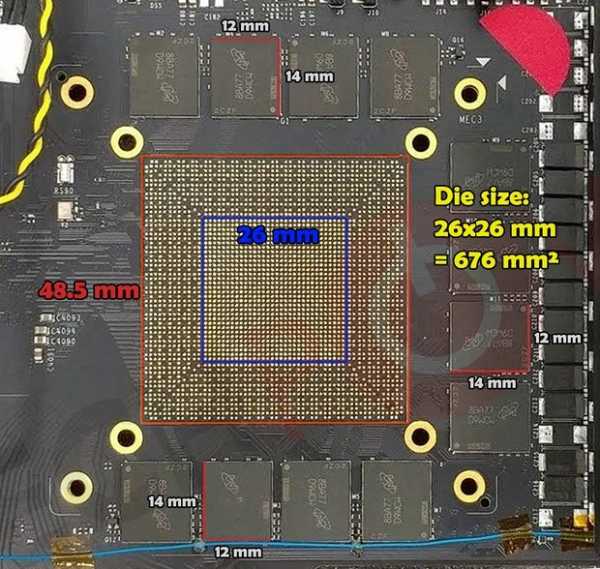
Что касается процессора, то наши коллеги из TechPowerUp решили всё-таки определить его размер. Зная габариты чипов памяти они масштабировали изображение и выяснили, что размер GPU составляет 48,5х48,5 мм. Размер же ядра равен 26х26 мм. Это значит, что площадь GV102 составляет 676 мм2, что на 40% крупнее GP102, площадь которого равна 471 мм2.
nvworld.ru
Производительность NVIDIA Volta GV100 может достигнуть 9,5 терафлопс / ServerNews
Как известно, следующим после Pascal поколением графических процессоров NVIDIA является Volta. Впрочем, к современным чипам название «графический процессор» применимо всё меньше — с тех пор, как их архитектура стала полностью унифицированной и программируемой, они прочно утвердились в различных проектах суперкомпьютеров, некоторые из которых уже вступили в строй и вовсю заняты научными и другими сложными вычислениями. Создавая свой первый чип Pascal GP100, NVIDIA уделила больше внимания его вычислительным возможностям, нежели графическим, и, похоже, первенца в семействе Volta, чип GV100, ожидает аналогичный подход.

Новый принцип построения узлов суперкомпьютера. Количество плат ускорителей не соответствует указанному в заметке
Уже подтверждено, что GV100 станет сердцем, а точнее, сердцами суперкомпьютеров Summit в Национальной лаборатории Ок-Ридж (Oak Ridge National Laboratory) и Sierra в Ливерморской национальной лаборатории (Lawrence Livermore National Laboratory). Первый проект должен войти в рабочую стадию в начале 2018 года и развить пиковую мощность 200 петафлопс, что существенно превышает показатель самого быстрого сегодняшнего китайского суперкомпьютера Sunway TaihuLight, чьи возможности оцениваются в 125,4 петафлопса. К сожалению, о характеристиках и архитектуре GV100 мы до сих пор знаем не так много, как хотелось бы, но кое-какие сведения о проекте Summit позволяют сделать некоторые выводы.
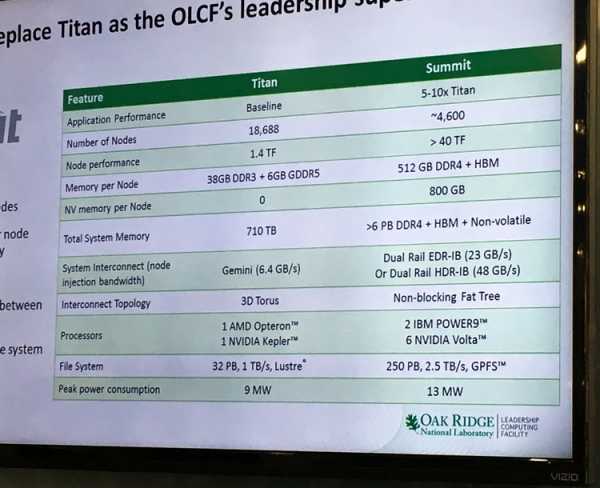
Тот самый слайд
Лаборатория в Ок-Ридже опубликовала слайд, на котором Summit сравнивается с суперкомпьютером Titan, базирующимся на чипах Kepler GK110. Состоит он из 18688 узлов, мощность каждого из них составляет 1,4 терафлопса. На том же плакате указаны спецификации Summit: 4600 узлов с мощностью более 40 терафлопс на узел. Указано также, что в каждом узле будет 512 Гбайт памяти DDR4, 800 Гбайт энергонезависимой памяти и некий объём памяти HBM (речь, разумеется, идёт о HBM2). Основой каждого узла станут пара процессоров IBM POWER9 и шесть процессоров NVIDIA Volta. Чипы POWER9, помимо традиционных линий PCI Express (версия 4.0) имеют и 48 линий интерфейса Bluelink, который будет работать в режиме NVLink 2.0 и соединять их с процессорами Volta, что позволит процессорам различных архитектур делить общее пространство памяти, практически не теряя в скорости: пропускная способность может составлять от 80 до 200 Гбайт/с.

Использование NVLink экономит энергию и повышает производительность
Потребляемая Summit мощность составит 13 мегаватт — всего на 4 мегаватта больше, нежели у Titan, при более чем десятикратном превосходстве в производительности. Как мы знаем, NVIDIA объявила о том, что GV100 будет демонстрировать эффективность 72 гигафлопса на ватт при операции перемножения матриц с одинарной точностью (Single precision floating General Matrix Multiply). Для GP100 этот показатель равен 42 гигафлопса на ватт. Нетрудно посчитать, приняв за основу теплопакет GV100 на уровне 300 ватт, что этот чип в теории может достичь производительности 9,5 терафлопс на вычислениях двойной точности (FP64). Шесть чипов GV100 при потреблении не выше 300 ватт на чип как раз и дадут упомянутые на плакате «более 40 терафлопс», а точнее, в теории, смогут выдать 57,2 терафлопса. Даже при конфигурации с теплопакетом 200 ватт и на 20‒25 % более низкой производительности производительность узла составит 45,6 терафлопс, так что у создателей Summit явно есть задел по части экономии электроэнергии при сохранении заявленных характеристик. По крайней мере, такой подход может существенно облегчить работу холодильных установок Summit.
Если вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Источник:
servernews.ru
Новости про Volta — МИР NVIDIA
Пользователь Reddit с ником dustinbrooks опубликовал фото прототипа видеокарты, который подписал как «это тестировал приятель, который работает на компанию, тестирующую платы NVIDIA». При этом он спросил у сообщества, что же это за устройство. И конечно, энтузиасты заинтересовались.
Видеокарта, как следует из маркировки возле коннектора PCI-Express x16, сделана NVIDIA. На снимке также видны три 8-контактных разъёма дополнительного питания и гигантская схема управления питания, охлаждаемая четырьмя вентиляторами. Чип разглядеть нельзя, но скорее всего речь идёт о GV102, наследнике GP102. Он окружён двенадцатью микросхемами GDDR6 с маркировкой D9WCW, что означает MT61K256M32JE-14:A. Это 8 гигабитные микросхемы GDDR6 от Micron с напряжением 1,35 В и пропускной способностью в 14 Гб/с. Это значит, что в сумме память будет работать на скорости 672 ГБ/с, что быстрее, чем 484 ГБ/с в Vega 64.
Прототип на базе GV102Наверху платы расположился коннектор NVLink, однако в нём нет половины контактов, а значит, последовательно соединить несколько видеокарт будет невозможно.
Поражает энергопотребление платы — 525 Вт. Учитывая массу тестовых выходов и джамперов, можно допустить, что плата используется для проверки производительности при разном энергопотреблении, так что конечный продукт должен потреблять несколько меньше.
Размер GPUЧто касается процессора, то наши коллеги из TechPowerUp решили всё-таки определить его размер. Зная габариты чипов памяти они масштабировали изображение и выяснили, что размер GPU составляет 48,5х48,5 мм. Размер же ядра равен 26х26 мм. Это значит, что площадь GV102 составляет 676 мм2, что на 40% крупнее GP102, площадь которого равна 471 мм2.
nvworld.ru
Производительность NVIDIA Volta GV100 может достигнуть 9,5 терафлопс
Как известно, следующим после Pascal поколением графических процессоров NVIDIA является Volta. Впрочем, к современным чипам название «графический процессор» применимо всё меньше — с тех пор, как их архитектура стала полностью унифицированной и программируемой, они прочно утвердились в различных проектах суперкомпьютеров, некоторые из которых уже вступили в строй и вовсю заняты научными и другими сложными вычислениями. Создавая свой первый чип Pascal GP100, NVIDIA уделила больше внимания его вычислительным возможностям, нежели графическим, и, похоже, первенца в семействе Volta, чип GV100, ожидает аналогичный подход.
Уже подтверждено, что GV100 станет сердцем, а точнее, сердцами суперкомпьютеров Summit в Национальной лаборатории Ок-Ридж (Oak Ridge National Laboratory) и Sierra в Ливерморской национальной лаборатории (Lawrence Livermore National Laboratory). Первый проект должен войти в рабочую стадию в начале 2018 года и развить пиковую мощность 200 петафлопс, что существенно превышает показатель самого быстрого сегодняшнего китайского суперкомпьютера Sunway TaihuLight, чьи возможности оцениваются в 125,4 петафлопса. К сожалению, о характеристиках и архитектуре GV100 мы до сих пор знаем не так много, как хотелось бы, но кое-какие сведения о проекте Summit позволяют сделать некоторые выводы.
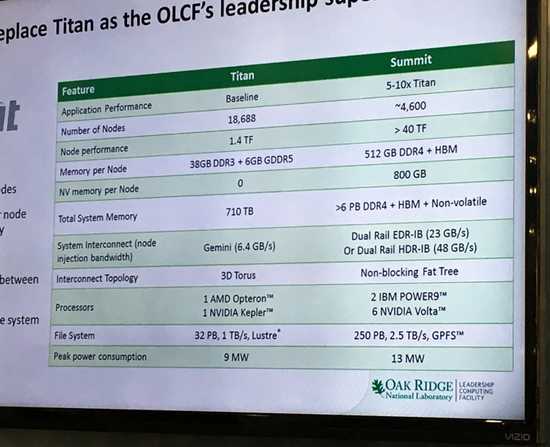
Тот самый слайд
Лаборатория в Ок-Ридже опубликовала слайд, на котором Summit сравнивается с суперкомпьютером Titan, базирующимся на чипах Kepler GK110. Состоит он из 18688 узлов, мощность каждого из них составляет 1,4 терафлопса. На том же плакате указаны спецификации Summit: 4600 узлов с мощностью более 40 терафлопс на узел. Указано также, что в каждом узле будет 512 Гбайт памяти DDR4, 800 Гбайт энергонезависимой памяти и некий объём памяти HBM (речь, разумеется, идёт о HBM2). Основой каждого узла станут пара процессоров IBM POWER9 и шесть процессоров NVIDIA Volta. Чипы POWER9, помимо традиционных линий PCI Express (версия 4.0) имеют и 48 линий интерфейса Bluelink, который будет работать в режиме NVLink 2.0 и соединять их с процессорами Volta, что позволит процессорам различных архитектур делить общее пространство памяти, практически не теряя в скорости: пропускная способность может составлять от 80 до 200 Гбайт/с.

Использование NVLink экономит энергию и повышает производительность
Потребляемая Summit мощность составит 13 мегаватт — всего на 4 мегаватта больше, нежели у Titan, при более чем десятикратном превосходстве в производительности. Как мы знаем, NVIDIA объявила о том, что GV100 будет демонстрировать эффективность 72 гигафлопса на ватт при операции перемножения матриц с одинарной точностью (Single precision floating General Matrix Multiply). Для GP100 этот показатель равен 42 гигафлопса на ватт. Нетрудно посчитать, приняв за основу теплопакет GV100 на уровне 300 ватт, что этот чип в теории может достичь производительности 9,5 терафлопс на вычислениях двойной точности (FP64). Шесть чипов GV100 при потреблении не выше 300 ватт на чип как раз и дадут упомянутые на плакате «более 40 терафлопс», а точнее, в теории, смогут выдать 57,2 терафлопса. Даже при конфигурации с теплопакетом 200 ватт и на 20‒25 % более низкой производительности производительность узла составит 45,6 терафлопс, так что у создателей Summit явно есть задел по части экономии электроэнергии при сохранении заявленных характеристик. По крайней мере, такой подход может существенно облегчить работу холодильных установок Summit.
Источник: servernews.ru
internetua.com
Производительность NVIDIA Volta GV100 может достигнуть 9,5 терафлопс — Блоги
Как известно, следующим после Pascal поколением графических процессоров NVIDIA является Volta. Впрочем, к современным чипам название «графический процессор» применимо всё меньше — с тех пор, как их архитектура стала полностью унифицированной и программируемой, они прочно утвердились в различных проектах суперкомпьютеров, некоторые из которых уже вступили в строй и вовсю заняты научными и другими сложными вычислениями. Создавая свой первый чип Pascal GP100, NVIDIA уделила больше внимания его вычислительным возможностям, нежели графическим, и, похоже, первенца в семействе Volta, чип GV100, ожидает аналогичный подход.
Новый принцип построения узлов суперкомпьютера. Количество плат ускорителей не соответствует указанному в заметке
Уже подтверждено, что GV100 станет сердцем, а точнее, сердцами суперкомпьютеров Summit в Национальной лаборатории Ок-Ридж (Oak Ridge National Laboratory) и Sierra в Ливерморской национальной лаборатории (Lawrence Livermore National Laboratory). Первый проект должен войти в рабочую стадию в начале 2018 года и развить пиковую мощность 200 петафлопс, что существенно превышает показатель самого быстрого сегодняшнего китайского суперкомпьютера Sunway TaihuLight, чьи возможности оцениваются в 125,4 петафлопса. К сожалению, о характеристиках и архитектуре GV100 мы до сих пор знаем не так много, как хотелось бы, но кое-какие сведения о проекте Summit позволяют сделать некоторые выводы.
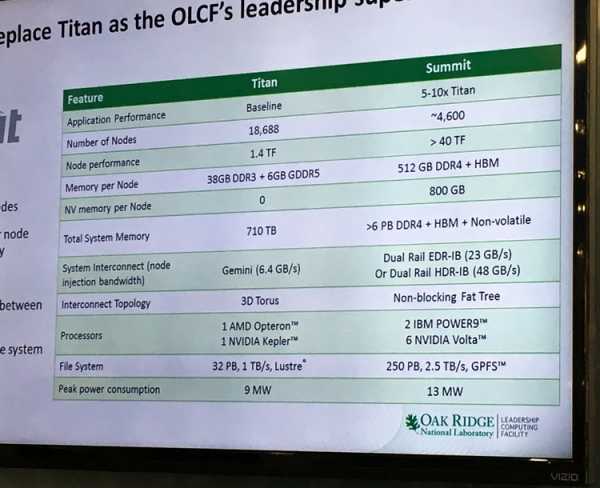
Тот самый слайд
Лаборатория в Ок-Ридже опубликовала слайд, на котором Summit сравнивается с суперкомпьютером Titan, базирующимся на чипах Kepler GK110. Состоит он из 18688 узлов, мощность каждого из них составляет 1,4 терафлопса. На том же плакате указаны спецификации Summit: 4600 узлов с мощностью более 40 терафлопс на узел. Указано также, что в каждом узле будет 512 Гбайт памяти DDR4, 800 Гбайт энергонезависимой памяти и некий объём памяти HBM (речь, разумеется, идёт о HBM2). Основой каждого узла станут пара процессоров IBM POWER9 и шесть процессоров NVIDIA Volta. Чипы POWER9, помимо традиционных линий PCI Express (версия 4.0) имеют и 48 линий интерфейса Bluelink, который будет работать в режиме NVLink 2.0 и соединять их с процессорами Volta, что позволит процессорам различных архитектур делить общее пространство памяти, практически не теряя в скорости: пропускная способность может составлять от 80 до 200 Гбайт/с.

Использование NVLink экономит энергию и повышает производительность
Потребляемая Summit мощность составит 13 мегаватт — всего на 4 мегаватта больше, нежели у Titan, при более чем десятикратном превосходстве в производительности. Как мы знаем, NVIDIA объявила о том, что GV100 будет демонстрировать эффективность 72 гигафлопса на ватт при операции перемножения матриц с одинарной точностью (Single precision floating General Matrix Multiply). Для GP100 этот показатель равен 42 гигафлопса на ватт. Нетрудно посчитать, приняв за основу теплопакет GV100 на уровне 300 ватт, что этот чип в теории может достичь производительности 9,5 терафлопс на вычислениях двойной точности (FP64). Шесть чипов GV100 при потреблении не выше 300 ватт на чип как раз и дадут упомянутые на плакате «более 40 терафлопс», а точнее, в теории, смогут выдать 57,2 терафлопса. Даже при конфигурации с теплопакетом 200 ватт и на 20‒25 % более низкой производительности производительность узла составит 45,6 терафлопс, так что у создателей Summit явно есть задел по части экономии электроэнергии при сохранении заявленных характеристик. По крайней мере, такой подход может существенно облегчить работу холодильных установок Summit.
www.playground.ru