Nvidia Volta – высокопроизводительная архитектура GPU
Nvidia ежегодно принимает активное участие на конференции по GPU-технологиям. В этом году компания в рамках своего выступления официально презентовала новую архитектуру графических процессоров Volta, а также семейство программно-аппаратных решений, которые позволят значительно ускорить работу с искусственным интеллектом.
Nvidia Volta представляет собой архитектуру графических процессоров нового поколения, которая по заявлению разработчиков, станет своего рода катализатором целой волны достижения в области высокопроизводительных вычислений и искусственного интеллекта.
Первым графическим процессором, выпущенным на базе новой архитектуры, стал Tesla V100. Этот GPU идеально подходит для дата-центров, обеспечивая высокую скорость графических вычислений, а также масштабируемость интерфейса нейронных сетей и обучения.
В качестве основы в графической архитектуре нового поколения используется 21 миллиард транзисторов, которые позволяют добиться производительности в задачах глубокого обучения, равную 100 CPU.
На ближайшие годы архитектура Volta станет стандартом высокопроизводительных вычислений. Один сервер на базе GPU Tesla V100, сможет стать заменой 100 обычным центральным процессорам за счет нового ядра Volta Tensor в унифицированной архитектуре.
Преодолеть 100-терафлопсный рубеж в задачах глубокого обучения GPU Tesla V100 удалось благодаря использованию специализированных ядер Tensor. Их общее количество в ускорителе достигает 640, что в конечном итоге дает производительность на уровне 120 терафлопс в глубоком обучении. Для увеличения пропускной способности в GPU используется NVLink нового поколения. Используемая память 900 ГБ/с HBM2 DRAM, разработкой которой занималась Nvidia совместно с Samsung, обеспечивает полосу пропускания, которая стала на 50% больше, чем с памятью прошлого поколения. Специально к выходу нового ускорителя, компанией было выпущено оптимизированное программное обеспечение, в том числе – CUDA, cuDNN и TensorRT.
Помимо презентации новой архитектуры Volta, компания Nvidia также представила линейку суперкомпьютеров с искусственным интеллектом Nvidia DGX AI, которые обладают впечатляющими характеристиками. Все модели новой линейки, базируются на Nvidia Tesla V100 на базе новой архитектуры Volta, в их состав входит обновленное программное обеспечение, оптимизированное для решения задач искусственного интеллекта. По сравнению с системами прошлого поколения, производительность Nvidia DGX AI увеличивается в три раза.
NVIDIA Volta: все, что нужно знать
Прошел всего год с тех пор, как была представлена первая видеокарта на основе архитектуры Pascal, и Nvidia недавно объявила о своем преемнике Volta. Это не обязательно может быть хорошей новостью для всех вас, особенно если вы недавно приобрели видеокарту из линейки NVIDIA Pascal. Сказав это, детали, которые мы знаем до сих пор, довольно интересны, если не сказать больше, поскольку Volta обещает значительно улучшить производительность под капотом.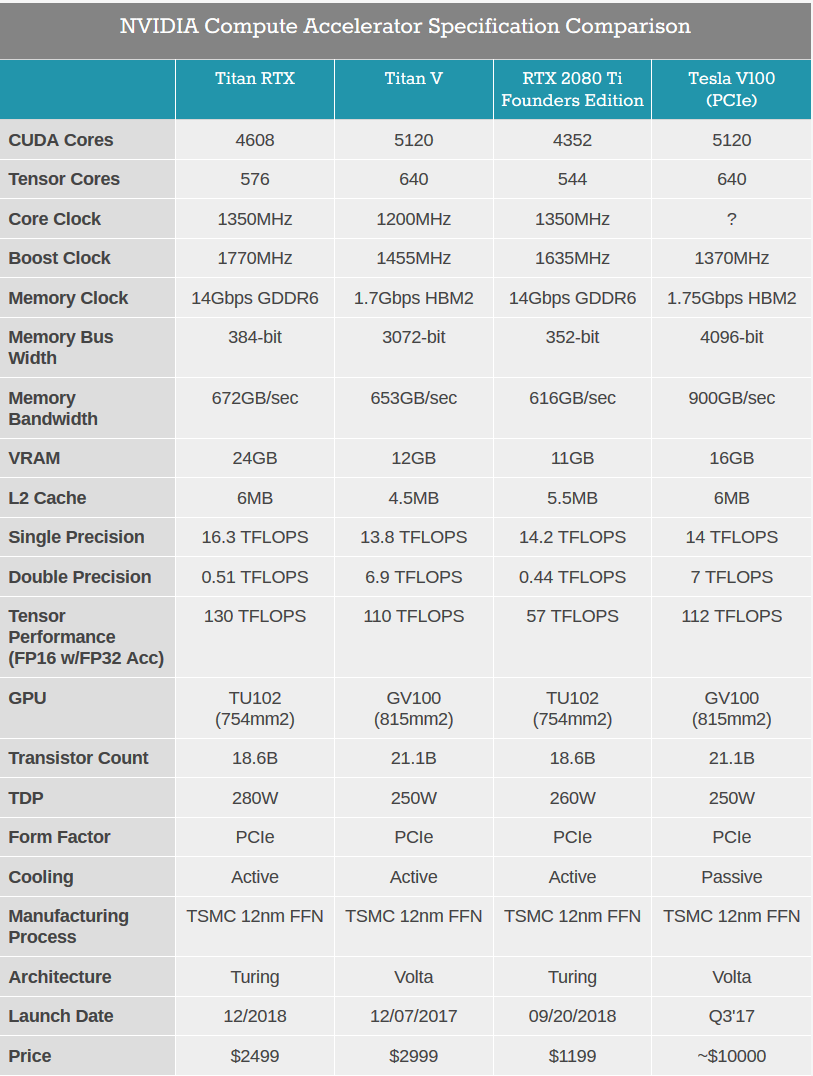
Что такое NVIDIA Volta?
Volta — это архитектура графических процессоров NVIDIA следующего поколения, которая полностью соответствует современной архитектуре Pascal, поддерживающей видеокарты серии GTX 10. Он будет использовать 12 нм процесс FinFET, так что это большой шаг вперед по сравнению с архитектурой Pascal.
Раз в 18–20 месяцев NVIDIA имеет тенденцию переходить на новую архитектуру, и, учитывая, что Pascal был представлен около года назад, пришло время получить некоторую подробную информацию об их следующей архитектуре. Хотя NVIDIA также представила свой первый графический процессор Tesla V100 на базе Volta, предназначенный для рынка баз данных, мы знаем, что вы, ребята, не в восторге от этого. Мы четко понимаем, что вы ждете видеокарты GeForce GTX на базе Volta, которые выйдут через несколько месяцев. При этом графический процессор Tesla V100 на основе архитектуры Volta стал возможен благодаря 21 миллиарду транзисторов и способен обеспечить производительность, эквивалентную 100 процессорам, для приложений, таких как глубокое обучение.
Мы четко понимаем, что вы ждете видеокарты GeForce GTX на базе Volta, которые выйдут через несколько месяцев. При этом графический процессор Tesla V100 на основе архитектуры Volta стал возможен благодаря 21 миллиарду транзисторов и способен обеспечить производительность, эквивалентную 100 процессорам, для приложений, таких как глубокое обучение.
Где будет использоваться Вольта?
Первый графический процессор на базе Volta, недавно представленный NVIDIA, Tesla V100, в первую очередь, займет свое место в центрах обработки данных и будет использоваться в области искусственного интеллекта и глубокого обучения. Вскоре архитектура Volta перейдет к популярной видеокарте NVIDIA GeForce GTX, которая будет ориентирована на игровой рынок . Помимо этих двух сегментов, вы также станете свидетелями мастерства Вольта в видеокартах NVIDIA Quadro для рабочих станций, которые создатели контента будут использовать в полной мере для рендеринга высокого разрешения и компьютерных изображений.
Как работает Volta?
Что касается производительности, для начала рассмотрим Tesla V100. Помимо того, что у графического процессора 21 млрд. Транзисторов, он также содержит 5120 ядер CUDA с тактовой частотой 1455 МГц . Это буквально ставит в тупик основанные на Pascal графические процессоры Tesla P100 для центров обработки данных, поскольку в них всего 15 миллиардов транзисторов и 3840 ядер CUDA. Признайте это или нет, но это определенно огромное улучшение всего за один год.
Переходя к играм, ожидайте огромного прироста производительности по сравнению с предыдущим поколением благодаря внедрению памяти GDDR6 и HBM2 . Учитывая нынешний флагман, NVIDIA Titan Xp способна обрабатывать почти все игры с разрешением 4K, сохраняя при этом частоту кадров выше 60 к / с, флагманская карта на базе Volta должна быть способна выдавать около 100 к / с в играх на 4K, что будет дополнять грядущие 4K мониторы с поддержкой G-Sync HDR с частотой обновления 144 Гц.
Как Вольта противостоит Паскалю?
Нельзя отрицать тот факт, что, как только появятся карты на базе Volta, линейка Pascal наверняка будет сломлена, когда дело доходит до чистой производительности . Это не значит, что состав Паскаля ни в коем случае не впечатляет. В 2016-17 годах они управляли всем игровым сегментом из-за того, что предлагали по цене. Высококачественные карты на основе Pascal, такие как GTX 1080, 1080 Ti и Titan Xp, легко справились с большинством игр с собственным разрешением 4K с плавной плавной частотой кадров 60 кадров в секунду, чего и терпеливо ждут геймеры ПК.
Теперь давайте вернемся к 6 мая 2016 года. Именно тогда GTX 1080 был официально представлен. Компания заявила, что GTX 1080 может предложить на 30% лучшую производительность, чем видеокарты Titan X на базе архитектуры Maxwell прошлого года и 980 Ti. Если принять во внимание эту запись, то графический процессор 80-й серии на базе Volta должен быть в состоянии превзойти Titan X Pascal, когда дело доходит до игровой производительности . Если это так, карты должны быть в состоянии справиться с большинством игр в разрешении 4K с невероятно быстрой скоростью 100 кадров в секунду, и это, мои друзья, является святым Граалем компьютерных игр.
Если это так, карты должны быть в состоянии справиться с большинством игр в разрешении 4K с невероятно быстрой скоростью 100 кадров в секунду, и это, мои друзья, является святым Граалем компьютерных игр.
Может ли AMD Vega конкурировать с Volta?
«Ждите Вегу» — это то, что мы слышали в течение нескольких месяцев от верующих AMD, но пока нет никаких признаков этого. Тем не менее, AMD подтвердила, что карты на базе Vega не за горами, и ожидается, что они будут представлены к концу этого квартала. Это нормально, но может ли он соответствовать NVIDIA Volta, когда он сводится к производительности? Ответ явно нет . AMD Vega запустится задолго до того, как Volta выйдет на прилавки, и, как сообщается, будет идти лицом к лицу с самыми мощными графическими процессорами NVIDIA Pascal, такими как GTX 1080 и GTX 1080 Ti. Возможно, он даже не сможет превзойти флагманский Titan Xp, но на самом деле это не проблема, потому что AMD в последнее время стремится к соотношению цены и производительности для своих последних продуктов, таких как процессоры Ryzen и GPU Polaris. Таким образом, к моменту выхода графических процессоров Volta AMD Vega не сможет конкурировать с новейшей архитектурой NVIDIA .
Таким образом, к моменту выхода графических процессоров Volta AMD Vega не сможет конкурировать с новейшей архитектурой NVIDIA .
Когда мы можем ожидать Вольта?
До сих пор NVIDIA была мамой о дате выпуска карт GeForce GTX на базе Volta. Однако, как обсуждалось ранее, если принять во внимание обычную дорожную карту компании, мы можем ожидать, что NVIDIA запустит ее примерно через 18–20 месяцев с момента анонса предыдущего состава. По сути, это означает, что карты GTX на базе Volta появятся на полках магазинов либо в этот праздничный сезон, либо в начале следующего года . Что касается Tesla V100, вы не найдете его в центрах обработки данных до третьего или четвертого квартала этого года.
В восторге от графических процессоров Volta?
 Тем не менее, если вы планируете построить новый ПК в ближайшем будущем, вы, вероятно, уже познакомились с графическими процессорами Volta. Итак, что вы думаете о будущих графических процессорах NVIDIA на базе Volta? Как вы думаете, это пока разрушит все тесты? Обязательно сообщите нам свои мысли, добавив несколько слов в разделе комментариев ниже.
Тем не менее, если вы планируете построить новый ПК в ближайшем будущем, вы, вероятно, уже познакомились с графическими процессорами Volta. Итак, что вы думаете о будущих графических процессорах NVIDIA на базе Volta? Как вы думаете, это пока разрушит все тесты? Обязательно сообщите нам свои мысли, добавив несколько слов в разделе комментариев ниже.Сравнение Google TPUv2 и Nvidia V100 на ResNet-50 / Хабр
Недавно NVIDIA представила новую архитектуру Volta (правда, пока только для серверов). По словам Хуань Женьсуна, одного из основателей и руководителей графического гиганта, новые GPU — это совсем не то, что было год назад, и вообще чуть ли не революция на рынке. Впрочем, то же самое он говорил и про Pascal, и про Maxwell, и раньше. И каждый раз, как ни странно, был прав. Как же так получается? Чтобы понять, придётся отправиться в прошлое и обратиться к древним технологиям. Итак, на дворе 1999-й год…
Начало новой эпохи
Приход архитектуры Pascal на рынок PC-железа — это что-то среднее между появлением GeForce 256 или переходом с «классической» архитектуры на концепцию полностью программируемого GPGPU. NVIDIA провела огромную работу по оптимизации внутренней структуры чипов: перетряхнули буквально всё, от потоковых процессоров и кеш-памяти до способов их соединения друг с другом. В результате Pascal рвёт в клочья достижения Maxwell’а везде, где это возможно. Но самое главное — компания научилась отлично оптимизировать сами ядра прямо внутри поколения. Хотите пример?
NVIDIA провела огромную работу по оптимизации внутренней структуры чипов: перетряхнули буквально всё, от потоковых процессоров и кеш-памяти до способов их соединения друг с другом. В результате Pascal рвёт в клочья достижения Maxwell’а везде, где это возможно. Но самое главное — компания научилась отлично оптимизировать сами ядра прямо внутри поколения. Хотите пример?
Сервер NVIDIA DGX-1 возглавил рейтинг производительности Geekbench
11.05.2017 [10:00], Иван Грудцын 12 нм dgx dgx station gv100 hbm2 hgx nvidia volta nvlink 2. 0 tensor tesla v100 hardware искусственный интеллект облачные технологии
0 tensor tesla v100 hardware искусственный интеллект облачные технологии
На конференции GTC 2021 в американском городе Сан-Хосе компания NVIDIA в лице её генерального директора Дженсена Хуанга (Jen-Hsun Huang) представила ускоритель Tesla V100 для дата-центров на основе графического процессора Volta GV100. Разработка последнего обошлась NVIDIA в $3 млрд, и в результате свет увидел чип площадью 815 мм², содержащий 21,1 млрд транзисторов, более 5000 потоковых процессоров и новые блоки Tensor, повышающие производительность GPU в так называемых матричных вычислениях. Изготовление ядер GV100 было поручено давнему партнёру NVIDIA — тайваньскому полупроводниковому гиганту TSMC. Техпроцесс выпуска — 12-нм FFN. Последняя буква в аббревиатуре FFN обозначает не что иное, как «NVIDIA»: технологическая норма разрабатывалась с учётом требований заказчика.
Tesla V100
Из года в год сложность архитектуры кремниевых кристаллов для HPC-задач продолжает расти, и теперь, с дебютом NVIDIA Volta, остаётся констатировать, что помимо потоковых процессоров, кеш-памяти первого и второго уровней, текстурных блоков, контроллеров VRAM и системного интерфейса, частью high-end GPU становятся блоки Tensor. У GV100 их по 8 на мультипроцессорный кластер (SM) и 672 в целом.
У GV100 их по 8 на мультипроцессорный кластер (SM) и 672 в целом.
SM-блок Volta GV100
Матричные вычисления в блоках Tensor увеличивают производительность нового ядра в задачах машинного обучения до 120 Тфлопс. В то же время быстродействие GV100 в FP32-вычислениях составляет 15 Тфлопс, а в FP64-вычислениях — 7,5 Тфлопс.
Volta GV100
Ядро Volta GV100 неотделимо от буферной памяти — четырёх микросхем HBM2, взаимодействующих с GPU по 4096-битной шине. Объём каждого чипа составляет 4 Гбайт, пропускная способность подсистемы памяти — 900 Гбайт/с. Кристалл GV100 дебютирует одновременно с ускорителем Tesla V100, являясь его основой. В V100 ядро работает на частоте до 1455 МГц (с учётом динамического разгона) обеспечивая вышеуказанную производительность в FP32-, FP64- и матричных (Tensor) вычислениях. Адаптер с GPU впечатляющих размеров потребляет умеренные 300 Вт — столько же, сколько и Tesla P100.
Спецификации ускорителей NVIDIA Tesla разных лет
Вычислительные возможности Volta GV100
По эскизу в начале данной заметки можно было догадаться, что соединение Tesla V100 с такими же ускорителями и центральным процессором обеспечивает интерфейс типа NVLink. В этот раз это не интерфейс первого поколения, а NVLink 2.0 — соответствующие контакты находятся на тыльной поверхности карты. В Tesla V100 реализовано шесть двунаправленных 25-Гбайт соединений (суммарно 300 Гбайт/с), а также функция согласования содержимого кеш-памяти с кешем центрального процессора IBM POWER9.
В этот раз это не интерфейс первого поколения, а NVLink 2.0 — соответствующие контакты находятся на тыльной поверхности карты. В Tesla V100 реализовано шесть двунаправленных 25-Гбайт соединений (суммарно 300 Гбайт/с), а также функция согласования содержимого кеш-памяти с кешем центрального процессора IBM POWER9.
Распространение новых HPC-ускорителей будет осуществляться по межкорпоративным (B2B) каналам. При этом заказчики получат свободный выбор между готовыми решениями вкупе с сопутствующим программным обеспечением и технической поддержкой. Все три системы — DGX-1, HGX-1 и DGX Station — предназначены для решения задач, связанных с развитием искусственного интеллекта (AI).
С системой глубинного обучения NVIDIA DGX-1 первого поколения мы уже знакомили читателей — она использует восемь ускорителей Tesla P100 с производительностью 170 Тфлопс в вычислениях половинной точности (FP16). Обновлённый сервер DGX-1 содержит восемь карт Tesla V100 с быстродействием 960 Тфлопс (FP16), два центральных процессора Intel Xeon и блок(-и) питания суммарной мощностью не менее 3200 Вт. Такой апгрейд позволяет выполнять не только типичные задачи в области исследования AI, но и переходить к новым, целесообразность решения которых прежде была под вопросом ввиду высокой сложности вычислений.
Такой апгрейд позволяет выполнять не только типичные задачи в области исследования AI, но и переходить к новым, целесообразность решения которых прежде была под вопросом ввиду высокой сложности вычислений.
Предварительный заказ системы NVIDIA DGX-1 второго поколения обойдётся всем желающим в $149 000. Ориентировочный срок начала поставок — третий квартал текущего года.
Сервер HGX-1 на восьми ускорителях Tesla V100 аналогичен DGX-1. Ключевое отличие данной системы заключается в применении жидкостного охлаждения компонентов. Кроме того, NVIDIA HGX-1 проще внедрить с ИТ-инфраструктуру компаний. Помимо глубинного обучения, этот сервер может использоваться в экосистеме GRID, а также для решения широкого круга HPC-задач.
NVIDIA DGX Station представляет собой высокопроизводительную рабочую станцию с четырьмя картами Tesla V100, центральным процессором Intel Xeon, системой жидкостного охлаждения и 1500-ваттным источником питания. Ускорители NVIDIA в составе DGX Station оснащены интерфейсом NVLink 200 Гбайт/с и тремя разъёмами DisplayPort с поддержкой разрешения 4K.
В матричных Tensor-вычислениях DGX Station обеспечивает быстродействие на уровне 480 Тфлопс. Стоимость рабочей станции для рынка США равна $69 000.
Постоянный URL:
Большой и злой Pascal
Новое поколение представляли видеокарты разного ценового сегмента. GTX 1080 и 1070 для игр в 4k и 2560×1440 соответственно, GTX 1060 как оптимальный выбор для игр в FullHD, и всё такое. Вершиной инженерной мысли, само собой, был Titan X. Спустя некоторое время вышла GTX1080 Ti — всё тот же «титан», но с упрощениями. Для увеличения выхода годных чипов два самых сложных блока — контроллер памяти и блок растеризации изображения — признаны условно-бракованными и отключены: чипы тестируются, если находится ошибка в одном из блоков, именно его «отрезают». Дело в шляпе: были дорогущие и идеальные Titan X, получились значительно более дешёвые (из-за меньшего количества отбраковки) «тишки».
Путь к Volta
Красным помечены различия между GTX 1080Ti (модули отсутствуют) и Titan X Pascal. Серый блок был включен в обеих девайсах и стал доступен только в TitanXP, единственной карте с необрезанным чипом GP102.
Серый блок был включен в обеих девайсах и стал доступен только в TitanXP, единственной карте с необрезанным чипом GP102.
Производительность практически не пострадала — наоборот, техпроцесс отработали, внутреннюю разводку чипов отполировали, снизили температурную напряжённость в определённых участках кристалла, и в результате получили более высокие рабочие частоты. Попробуйте вспомнить хоть один пример такого апгрейда внутреннего устройства железа посреди поколения — на ум приходит разве что выход Radeon HD7970 1GHz edition в далёком 2012-м. Тогда видеокарте разом накинули 10% производительности из воздуха, просто оптимизировав производство её чипов.
Путь к Volta
Вот так NVIDIA получает более простые карточки из неудавшихся чипов старших серий
Та же история и с 1080Ti — это качественное улучшение безумно дорогого процессора GP102, пусть и с некоторыми функциональными упрощениями. А потеря одного гигабайта оперативки — да и чёрт бы с ним, не все игры 8 ГБ в режиме 4k умеют загрузить, а вы про разницу между 11-ю и 12-ю говорите…
Путь к Volta
Лучше 96% всех других компьютеров — примерно на такой результат могут рассчитывать владельцы GTX 1080 Ti и мощного современного процессора.
Если сравнивать с «Максвеллом», то эффект просто взрывной. Суперфлагманская 1080 Ti быстрее старушки 980 Ti на 50-60%, и при этом холоднее! Вот что техпроцесс животворящий делает!
1 — Тактовые частоты могут отличаться в зависимости от производителя видеокарты и разгонного потенциала конкретного чипа. 2 — Эффективная частота GDDR5X вдвое выше таковой у GDDR5 из-за архитектурных особенностей.
Спарка из 980 Ti может осадить дерзкого новичка только в определённых условиях — бенчмарках, идеально загружающих оба чипсета, да редких ААА-играх, чьи разработчики заморочились оптимизацией не только под мэйнстрим, но и под маргинальные сборки геймеров-толстосумов. Результаты наглядно видны на картинках и в сводной таблице:
Путь к Volta
На конференции GTC 2021 в американском городе Сан-Хосе компания NVIDIA в лице её генерального директора Дженсена Хуанга (Jen-Hsun Huang) представила ускоритель Tesla V100 для дата-центров на основе графического процессора Volta GV100. Разработка последнего обошлась NVIDIA в $3 млрд, и в результате свет увидел чип площадью 815 мм², содержащий 21,1 млрд транзисторов, более 5000 потоковых процессоров и новые блоки Tensor, повышающие производительность GPU в так называемых матричных вычислениях. Изготовление ядер GV100 было поручено давнему партнёру NVIDIA — тайваньскому полупроводниковому гиганту TSMC. Техпроцесс выпуска — 12-нм FFN. Последняя буква в аббревиатуре FFN обозначает не что иное, как «NVIDIA»: технологическая норма разрабатывалась с учётом требований заказчика.
Разработка последнего обошлась NVIDIA в $3 млрд, и в результате свет увидел чип площадью 815 мм², содержащий 21,1 млрд транзисторов, более 5000 потоковых процессоров и новые блоки Tensor, повышающие производительность GPU в так называемых матричных вычислениях. Изготовление ядер GV100 было поручено давнему партнёру NVIDIA — тайваньскому полупроводниковому гиганту TSMC. Техпроцесс выпуска — 12-нм FFN. Последняя буква в аббревиатуре FFN обозначает не что иное, как «NVIDIA»: технологическая норма разрабатывалась с учётом требований заказчика.
Tesla V100
Из года в год сложность архитектуры кремниевых кристаллов для HPC-задач продолжает расти, и теперь, с дебютом NVIDIA Volta, остаётся констатировать, что помимо потоковых процессоров, кеш-памяти первого и второго уровней, текстурных блоков, контроллеров VRAM и системного интерфейса, частью high-end GPU становятся блоки Tensor. У GV100 их по 8 на мультипроцессорный кластер (SM) и 672 в целом.
SM-блок Volta GV100
Матричные вычисления в блоках Tensor увеличивают производительность нового ядра в задачах машинного обучения до 120 Тфлопс. В то же время быстродействие GV100 в FP32-вычислениях составляет 15 Тфлопс, а в FP64-вычислениях — 7,5 Тфлопс.
В то же время быстродействие GV100 в FP32-вычислениях составляет 15 Тфлопс, а в FP64-вычислениях — 7,5 Тфлопс.
Volta GV100
Ядро Volta GV100 неотделимо от буферной памяти — четырёх микросхем HBM2, взаимодействующих с GPU по 4096-битной шине. Объём каждого чипа составляет 4 Гбайт, пропускная способность подсистемы памяти — 900 Гбайт/с. Кристалл GV100 дебютирует одновременно с ускорителем Tesla V100, являясь его основой. В V100 ядро работает на частоте до 1455 МГц (с учётом динамического разгона) обеспечивая вышеуказанную производительность в FP32-, FP64- и матричных (Tensor) вычислениях. Адаптер с GPU впечатляющих размеров потребляет умеренные 300 Вт — столько же, сколько и Tesla P100.
Спецификации ускорителей NVIDIA Tesla разных лет
Вычислительные возможности Volta GV100
По эскизу в начале данной заметки можно было догадаться, что соединение Tesla V100 с такими же ускорителями и центральным процессором обеспечивает интерфейс типа NVLink. В этот раз это не интерфейс первого поколения, а NVLink 2.0 — соответствующие контакты находятся на тыльной поверхности карты. В Tesla V100 реализовано шесть двунаправленных 25-Гбайт соединений (суммарно 300 Гбайт/с), а также функция согласования содержимого кеш-памяти с кешем центрального процессора IBM POWER9.
Распространение новых HPC-ускорителей будет осуществляться по межкорпоративным (B2B) каналам. При этом заказчики получат свободный выбор между готовыми решениями вкупе с сопутствующим программным обеспечением и технической поддержкой. Все три системы — DGX-1, HGX-1 и DGX Station — предназначены для решения задач, связанных с развитием искусственного интеллекта (AI).
С системой глубинного обучения NVIDIA DGX-1 первого поколения мы уже знакомили читателей — она использует восемь ускорителей Tesla P100 с производительностью 170 Тфлопс в вычислениях половинной точности (FP16). Обновлённый сервер DGX-1 содержит восемь карт Tesla V100 с быстродействием 960 Тфлопс (FP16), два центральных процессора Intel Xeon и блок(-и) питания суммарной мощностью не менее 3200 Вт. Такой апгрейд позволяет выполнять не только типичные задачи в области исследования AI, но и переходить к новым, целесообразность решения которых прежде была под вопросом ввиду высокой сложности вычислений.
Предварительный заказ системы NVIDIA DGX-1 второго поколения обойдётся всем желающим в $149 000. Ориентировочный срок начала поставок — третий квартал текущего года.
Сервер HGX-1 на восьми ускорителях Tesla V100 аналогичен DGX-1. Ключевое отличие данной системы заключается в применении жидкостного охлаждения компонентов. Кроме того, NVIDIA HGX-1 проще внедрить с ИТ-инфраструктуру компаний. Помимо глубинного обучения, этот сервер может использоваться в экосистеме GRID, а также для решения широкого круга HPC-задач.
NVIDIA DGX Station представляет собой высокопроизводительную рабочую станцию с четырьмя картами Tesla V100, центральным процессором Intel Xeon, системой жидкостного охлаждения и 1500-ваттным источником питания. Ускорители NVIDIA в составе DGX Station оснащены интерфейсом NVLink 200 Гбайт/с и тремя разъёмами DisplayPort с поддержкой разрешения 4K.
В матричных Tensor-вычислениях DGX Station обеспечивает быстродействие на уровне 480 Тфлопс. Стоимость рабочей станции для рынка США равна $69 000.
Если вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER. | Можете написать лучше? Мы всегда рады новым авторам.
V — значит Volta
Если переход от Maxwell к Pascal в чем-то сродни переводу архитектуры видеокарт с узкоспециализированных железяк на GPGPU, то шаг от Pascal до Volta сейчас сложно охарактеризовать: тестов мы не видели, и новые технологии Volta ещё не прошли обкатку рынком и реальными продуктами. Но можем проанализировать то, что уже известно.
Путь к Volta
Разработка вот этой «штучки» в руках Хуан Жэньсюня стоила 3 миллиарда долларов
Главной фишкой текущего поколения был переход с древнего техпроцесса в 28 нм (его, простите, ещё в 2012 году использовала та самая 7970) на современные 16 и 14 нм. Этот шаг радикально улучшил частотный потенциал новинок и снизил энергопотребление: отсюда и грубая производительность, и хороший разгон, и удивительная производительность недорогих карточек во многих играх.
Путь к Volta
За три с половиной поколения размеры кристалла выросли, но количество транзисторов увеличилось ещё больше — спасибо новому техпроцессу.
В Volta частотных чудес ждать не стоит, разница между 16 нанометрами «Паскаля» и планируемыми 12 у будущих королей графона не так велика, как между 28 и 16 в прошлом году. Но… если Pascal был соковыжималкой для технологий CUDA, которым уже больше десяти лет, и которые были изначально представлены в семействе 8800, то Volta — это первый по-настоящему новый продукт, в корне отличающийся от всех предыдущих плат вместе взятых.
Новые ядра
GPU обычных NVIDIA уже давно состоят из объединённых в блоки мультипроцессоров универсальных ядер CUDA. Они занимаются обработкой треугольников, обсчётом шейдеров, выполнением общих расчётов, и так далее. В Volta помимо CUDA будут использоваться новые ядра Tensor, достаточно узкоспециализированные, но крайне полезные в ряде задач.
Основное назначение этих чудо-ядер — работа со специфическими данными. Карта выдаёт «ядру» две матрицы 4×4 в формате FP16, перемножает их, а дальше прибавляет третью матрицу 4х4 формата FP16 или FP32 и прибавляет к ней результат. За один проход. Если кто с матрицами ещё не работал, или забыл, как это выглядит, вот пример расчётов, которые надо выполнить для умножения двух простеньких прямоугольных таблиц с целыми числами:
Путь к Volta
Pascal на CUDA может проводить операции построчно, Tensor-ядра из Volta проделывают те же расчёты для всех строк разом. Разница в производительности между старыми картами и новыми — до 12 раз. В основном такие операции используются при машинном обучении, распознавании образов, конфигурирования нейросетей и прочих штуках, оперирующих огромными массивами данных.
Новая память
Для обеспечения GPU достаточным количеством данных необходима быстрая память. Вариантов тут не много: использовать очень дорогую и сложную в производстве HBM2 (что и делают в ускорителях для научных расчётов и некоторых картах от AMD), увеличивать шину памяти (крайне затратно и тяжело) или всячески наращивать частотный потенциал классической GDDR. Так как первые два подхода годятся учёным и энтузиастам, но не среднему игроку, то NVIDIA будет использовать новейшую разработку Samsung — память GDDR6: она быстрее, чем GDDR5X у «Титанов» и флагманов текущего поколения, выделяет меньше тепла при работе, и главное — объёмы могут снова вырасти.
Новый софт
Хорошее железо — полдела. Задействовать мощь Volta на полную катушку помогут новые инструменты, помогающие работать напрямую с GPU из множества популярных языков программирования.
Производительность NVIDIA Volta GV100 может достигнуть 9,5 терафлопс
Как известно, следующим после Pascal поколением графических процессоров NVIDIA является Volta. Впрочем, к современным чипам название «графический процессор» применимо всё меньше — с тех пор, как их архитектура стала полностью унифицированной и программируемой, они прочно утвердились в различных проектах суперкомпьютеров, некоторые из которых уже вступили в строй и вовсю заняты научными и другими сложными вычислениями. Создавая свой первый чип Pascal GP100, NVIDIA уделила больше внимания его вычислительным возможностям, нежели графическим, и, похоже, первенца в семействе Volta, чип GV100, ожидает аналогичный подход.
Новый принцип построения узлов суперкомпьютера. Количество плат ускорителей не соответствует указанному в заметке
Новый принцип построения узлов суперкомпьютера. Количество плат ускорителей не соответствует указанному в заметке
Уже подтверждено, что GV100 станет сердцем, а точнее, сердцами суперкомпьютеров Summit в Национальной лаборатории Ок-Ридж (Oak Ridge National Laboratory) и Sierra в Ливерморской национальной лаборатории (Lawrence Livermore National Laboratory). Первый проект должен войти в рабочую стадию в начале 2021 года и развить пиковую мощность 200 петафлопс, что существенно превышает показатель самого быстрого сегодняшнего китайского суперкомпьютера Sunway TaihuLight, чьи возможности оцениваются в 125,4 петафлопса. К сожалению, о характеристиках и архитектуре GV100 мы до сих пор знаем не так много, как хотелось бы, но кое-какие сведения о проекте Summit позволяют сделать некоторые выводы.
Тот самый слайд
Тот самый слайд
Лаборатория в Ок-Ридже опубликовала слайд, на котором Summit сравнивается с суперкомпьютером Titan, базирующимся на чипах Kepler GK110. Состоит он из 18688 узлов, мощность каждого из них составляет 1,4 терафлопса. На том же плакате указаны спецификации Summit: 4600 узлов с мощностью более 40 терафлопс на узел. Указано также, что в каждом узле будет 512 Гбайт памяти DDR4, 800 Гбайт энергонезависимой памяти и некий объём памяти HBM (речь, разумеется, идёт о HBM2). Основой каждого узла станут пара процессоров IBM POWER9 и шесть процессоров NVIDIA Volta. Чипы POWER9, помимо традиционных линий PCI Express (версия 4.0) имеют и 48 линий интерфейса Bluelink, который будет работать в режиме NVLink 2.0 и соединять их с процессорами Volta, что позволит процессорам различных архитектур делить общее пространство памяти, практически не теряя в скорости: пропускная способность может составлять от 80 до 200 Гбайт/с.
Использование NVLink экономит энергию и повышает производительность
Использование NVLink экономит энергию и повышает производительность
Потребляемая Summit мощность составит 13 мегаватт — всего на 4 мегаватта больше, нежели у Titan, при более чем десятикратном превосходстве в производительности. Как мы знаем, NVIDIA объявила о том, что GV100 будет демонстрировать эффективность 72 гигафлопса на ватт при операции перемножения матриц с одинарной точностью (Single precision floating General Matrix Multiply). Для GP100 этот показатель равен 42 гигафлопса на ватт. Нетрудно посчитать, приняв за основу теплопакет GV100 на уровне 300 ватт, что этот чип в теории может достичь производительности 9,5 терафлопс на вычислениях двойной точности (FP64). Шесть чипов GV100 при потреблении не выше 300 ватт на чип как раз и дадут упомянутые на плакате «более 40 терафлопс», а точнее, в теории, смогут выдать 57,2 терафлопса. Даже при конфигурации с теплопакетом 200 ватт и на 20‒25 % более низкой производительности производительность узла составит 45,6 терафлопс, так что у создателей Summit явно есть задел по части экономии электроэнергии при сохранении заявленных характеристик. По крайней мере, такой подход может существенно облегчить работу холодильных установок Summit.
Что это даёт нам
Сами по себе видеокарты на базе Volta, безусловно, принесут свои 15-20-30% чистой производительности относительно Pascal за счёт более высоких частот, внутренних оптимизаций и большего количества ресурсов, доступных играм. Но это не всё. Тензорные ядра позволят разработчикам практически «бесплатно» использовать алгоритмы машинного обучения в играх.
Например, заставить движок игры анализировать влияние настроек на производительность на конкретно вашей системе, и выработать уникальный паттерн «динамических параметров», убирающий просадки в FPS ещё на стадии формирования сцены в кадре. Где-то текстурки попроще, снизить детализацию моделей на момент взрыва и блюра, и так далее. Или же применить алгоритмы для обучения ИИ вашему стилю игры. Привыкли к игре вдолгую? Вот вам ранняя атака по ресусной базе. Предпочитаете зерг-раш? Через пару миссий ждите застройку на рампе. Занимаетесь снайперскими вылазками и предпочитаете бой на дальних дистанциях? Ждите ловушек и миномётчиков, готовых к обстрелу указанного квадрата. В гонках рассчитываете на мощное ускорение на выходе из поворота? Не пустят на траекторию или подрежут. В общем, анализ поведения игрока и применение дополнительных мощностей для улучшения игрового разнообразия — один из актуальных сценариев применения новых ядер.
Фотореалистичный KINGSGLAIVE: Final Fantasy XV в реальном времени на NVIDIA Tesla Volta
И не стоит забывать про применение дополнительных ресурсов к построению красивой картинки. В конце концов, матричные операции очень часто применяются в современных спецэффектах и для создания компьютерных лент.
Видеокарта Volta Nvidia новости на 06.01.2018 г. Всё, что известно на данный момент.
Почему так? Причина тому в крайне вялотекущем выходе на рынок Vega. Vega и без того очень сильно задержались, и помимо этого толком еще и продаваться не начала. Точнее начали, но о дефиците и завышенных ценниках слыхали уже все. В текущей ситуации NVIDIA просто незачем как-либо шевелиться. В своем сегменте GTX 1070 и GTX 1080 наряду с Ti все еще остаются великолепными видеокартами, у которых конкурентов как бы и нет.
Nvidia представляет самый быстрый GPU по несколько раз в год. Titan V является самой мощной видеокартой из всех когда-либо созданных. Это первый графический процессор, основанный на новой архитектуре Volta от Nvidia.
Ещё в мае компания Nvidia представила монструозный графический процессор GV100 поколения Volta. GPU состоит из 21,1 млрд транзисторов и насчитывает 5376 ядер CUDA. Сложно даже представить, какой игровой производительностью может обладать видеокарта с таким ядром.
GPU обычных NVIDIA уже давно состоят из объединённых в блоки мультипроцессоров универсальных ядер CUDA. Они занимаются обработкой треугольников, обсчётом шейдеров, выполнением общих расчётов, и так далее. В Volta помимо CUDA будут использоваться новые ядра Tensor, достаточно узкоспециализированные, но крайне полезные в ряде задач.
Новая вычислительная архитектура Nvidia Volta 06.01.2018 г. Эксклюзив.
Видеокарты GeForce GTX 1050 и GTX 1050 Ti имеют референсный дизайн, но они не имеют официальной даты анонса, есть дата начала продаж — 25 октября. Дата выхода видеокарт зависит от сроков, в которые партнеры NVIDIA смогут выпустить модельный ряд видеокарт своего дизайна[4].
SAP Brand Impact – Проект SAP Brand Impact на базе решений NVIDIA для глубокого обучения измеряет атрибуты бренда (например, логотипы) практически в реальном времени. Эффективный анализ видеоконтента стал возможен благодаря использованию для анализа глубоких нейросетей, обученных на NVIDIA DGX-1 и TensorRT.
купить дешево GTX 1070 купить дешево GTX 1080 купить GTX 1060 3Gb дешево купить GTX 1060 6Gb дешево купить RX 460 дешево купить дешево GTX 750 ti купить дешево GTX 950 купить дешево R9 380 купить дешево RX 470
Чип Xavier впечатляет. Он состоит из 8 вычислительных ядер с заказной архитектурой ARM64, а также из 512 графических ядер архитектуры Volta. Однако NVIDIA заявляла, что это будут 16 нм процессоры. Возможно, что производственные партнёры компании позволили NVIDIA влиться в гонку технологий.
Новый GPU NVIDIA построен из 21 миллиарда транзисторов, а производиться он будет по 12 нм FFN процессу на заводах TSMC. Габариты процессора просто огромны. Его площадь составляет 815 мм2. В ходе презентации Дзень-Хсунь Хуан сравнил размер новой разработки с часами Apple Watch.
Например, заставить движок игры анализировать влияние настроек на производительность на конкретно вашей системе, и выработать уникальный паттерн «динамических параметров», убирающий просадки в FPS ещё на стадии формирования сцены в кадре. Где-то текстурки попроще, снизить детализацию моделей на момент взрыва и блюра, и так далее. Или же применить алгоритмы для обучения ИИ вашему стилю игры. Привыкли к игре вдолгую? Вот вам ранняя атака по ресусной базе. Предпочитаете зерг-раш? Через пару миссий ждите застройку на рампе. Занимаетесь снайперскими вылазками и предпочитаете бой на дальних дистанциях? Ждите ловушек и миномётчиков, готовых к обстрелу указанного квадрата. В гонках рассчитываете на мощное ускорение на выходе из поворота? Не пустят на траекторию или подрежут. В общем, анализ поведения игрока и применение дополнительных мощностей для улучшения игрового разнообразия — один из актуальных сценариев применения новых ядер.
Заметили, что с 2001 по 2007 программистам давали всё больше доступа к непосредственному контролю над видеокартой: позволяли указывать, что и как делать? Молодцы. Потому что в 2007 году NVIDIA перешла на архитектуру Tesla, в основе которой лежали именно управляемые вычисления на базе графического процессора — из узкоспециализированной железки плата превратилась в мощный высокопараллельный модуль.
Вопрос на какой видеокарте собирать свою будущую игровую систему, волнует многих игроманов. Кто то даже нацелен на будущее поколение видеокарт от Nvidia с архитектурой Volta. А стоит ли ждать их появления должно ответить это видео.
Архитектура NVIDIA Volta и другие анонсы. Главные новости.
Но новые данные указывают на то, что игровых адаптеров этого поколения может не быть вовсе. Источник утверждает, что на мероприятии GPU Technology Conference 2021, которое пройдёт с 26 по 29 марта, Nvidia расскажет о новом поколении игровых видеокарт. Но называться оно будет Ampere.
Со дня выхода первых видеокарт GeForce GTX на базе графических процессоров Nvidia Pascal прошло уже почти полтора года и многие компьютерные энтузиасты уже предвкушают скорый анонс игровых ускорителей на базе архитектуры Volta. Как сообщает немецкий веб-ресурс Heise.de, формальный дебют графических адаптеров GeForce GTX следующего поколения состоится в рамках мероприятия GPU Technology Conference (GTC) 2021, которое пройдёт с 26 по 29 марта в Кремниевой долине. Однако вместо ожидаемых игровых видеокарт «семейства» Volta на нём будут представлены первые адаптеры, использующие микроархитектуру Ampere.
Конечно, только лишь новый техпроцесс не позволит NVIDIA увеличить производительность Ampere по сравнению с Pascal вдвое. Конечно, он должен обеспечить более высокий частотный потенциал, при более низком, или хотя бы том же уровне потребления энергии. Но одной частотой сыт не будешь. Возможно, нас ждут некие достаточно весомые изменения в архитектуре? Увидим весной или вначале лета будущего года.
Следующее поколение GPU NVIDIA будет изготавливаться на заводах TSMC по 16 нм технологии FinFET, в то время как AMD в будущих чипах Vega будет применять 14 нм процесс от Global Foundries. Об этих GPU также известно, что они будут работать со стековой памятью HBM 2.0 и будут выпущены в будущем году. Компания AMD после 14 нм производства перейдёт сразу к 7 нм технологии, минуя 10 нм процесс, что, непременно, потребует много времени.
В Fermi особый акцент делался на качественные изменения в архитектуре чипа: если Tesla на микрофотографии выглядела, как творческий беспорядок, то Fermi — как произведение инженерного искусства, куда более сложный и формализованный.
Для работы GPU в сфере искусственного интеллекта и глубокого обучения NVIDIA интегрировала в GPU ядро Tensor. Модуль Tesla V100 имеет 16 Гб видеопамяти с 20 Мб SM RF. Видеопамять реализована на микросхемах HBM2 со скоростью 900 Гб/с. Модуль поддерживает шину NVlink со скоростью 300 ГБ/с.
Интересным же этот драйвер делает то, что кроме стандартного набора поддержки GPU и утилит, в нём содержится информация о графических процессорах Pascal и Volta. Также примечательной является предварительная поддержка API Vulkan, наследника OpenGL.
С другой стороны, если впервые о Volta компания Nvidia рассказала в уже далёком 2013 году, то фамилия французского физика Андре-Мари Ампера ещё ни разу не была услышана из уст представителей «зелёного» чипмейкера или замечена в дорожной карте. И наверняка узнать какую именно замену
видеокартам GeForce GTX 10-й серии готовит Nvidia, удастся только в начале следующего года.
На этой неделе в Сан-Хосе проходит ежегодная конференция NVIDIA по GPU-технологиям. 7000 участников, 600 технических сессий, 150 стендов, 310 сессий по искусственному интеллекту и 67 лабораторий по технологиям глубокого обучения (Deep Learning).
Для того чтобы справляться с задачами подобного уровня вычислительной сложности, в прототипах автомобилей зачастую используют мощные компьютеры, которые занимают весь багажник. Платформа NVIDIA DRIVE PX на базе процессора нового поколения Xavier легко помещается в руке, обеспечивая при этом 30 млрд операций глубокого обучения в секунду.
Что за видеокарта Volta Nvidia все данные мощность тех. характеристики. Все последние сведения на 06.01.2018 г.
Конфигурация графического ускорителя Titan V предусматривает использование 5120 ядер CUDA и 640 ядер Tensor. Заявленная производительность достигает 110 Тфлопс в глубоком обучении. Базовая частота равна 1200 МГц, форсированная частота — 1455 МГц.
Project Holodeck – Project Holodeck – это фотореалистичное VR-окружение для совместной работы, которое позволяет видеть, слышать и осязать виртуализированные объекты. Среда Holodeck позволяет создателям импортировать модели высокой четкости и высокого разрешения в VR для совместной работы над ними вместе с коллегами.
Кроме уже известных архитектур NVIDIA объявила о новой архитектуре Volta. Сроки её выхода пока неизвестны, но учитывая нынешние тенденции можно предположить, что эти GPU выйдут в 2016 году. Наряду со всеми модификациями предшественников, процессоры Volta предложат технологию использования памяти DRAM в стеках, что позволит увеличить пропускную способность памяти до 1 ТБ/с. Для сравнения, современные топовые видеокарты, такие как GeForce Titan и Radeon HD 7970 GHz Edition, имеют пропускную способность памяти в 300 ГБ/с, так что планы NVIDIA выглядят вполне реализуемыми.
Видео новости Видеокарта Volta. Срочная информация.
Прочитали ? Поделитесь с друзьями. Спасибо!
Брать или ждать
Главный вопрос, который терзает многих. Брать «Паскаль» или дождаться-таки «Вольты»? Если у вас любая NVIDIA 4хх, 5хх, 6хх, Radeon HD или R5/7/9-серий, или ещё более старые/слабые видеокарты — переход на Pascal оправдан. GTX 1050Ti в большинстве современных игр выдаёт FullHD 60 FPS картинку на высоких настройках и опережает GTX 680, пусть и незначительно. Про более мощные варианты и говорить не стоит. Тем же, кто рассматривает покупку флагманских решений можно лишь посочувствовать. Новый майнерский бум высосал с рынка все доступные варианты, и достать сейчас GTX 1070, 1080 или 1080 Ti за разумные деньги затруднительно.
Путь к Volta
Потребительская Volta ожидается лишь к весне 2021, а технологии, заложенные в новое поколение GPU, начнут раскрываться лишь спустя пару лет — после накопления критической массы пользователей и завершения поисковых работ на тему применения машинного обучения и тензорных ядер в играх. Так что купившие топовую NVIDIA этим летом вряд ли пожалеют о своём выборе через год.
Подробности NVIDIA GPU GV100
NVIDIA на мероприятии GTC 2021, анонсировала архитектуру нового поколения «Volta». Как и в случае с нынешней архитектурой «Pascal», «Вольта» была представлена в своей самой большой и функциональной реализации — плате Tesla V100 HPC, управляемой GPU GV100. Учитывая применение HPC в продуктах семейства продуктов Tesla от NVIDIA, у GV100 есть определённые компоненты, которые не попадут в потребительскую семью GeForce. Несмотря на это, GV100 является вершиной инженерной разработки NVIDIA. Согласно блок-схеме графического процессора, выпущенной компанией, GV100 имеет похожую иерархию компонентов с чипами предыдущего поколения от NVIDIA, но с некоторыми существенными изменениями в базовой вычислительной машине, потоковом мультипроцессоре (SM — streaming multiprocessor).
SM Volta на кристалле GV100 имеет ядра CUDA как для FP32, так и FP64. Потребительские графические реализации Volta, будущие продукты GeForce, могут не получить специализированных ядер FP64. Далее. Каждый SM имеет 64 ядра FP32 и 32 ядра FP64. Ядра FP64 могут обрабатывать 32, 16 и даже примитивные 8-битные операции. Чип GV100 имеет 80 SM: 5.120 FP32 и 2.560 FP64 ядер CUDA. Кроме того, Volta вводит компонент под названием «Tensor core», специализированный механизм, предназначенный для ускорения обучения и построения нейронной сети. Каждый SM несёт 8 из них, поэтому GV100 в сумме получает 640. Как и в случае с ядрами FP64, тензорные ядра могут не соответствовать реалиям потребительской графики. Учитывая количество SM, GV100 имеет 320 TMU. NVIDIA разогнала GV100 до 1455 МГц.
Объявлено, что Tesla V100 обеспечивает максимальную производительность FP32 и FP64 на 50% по сравнению с Pascal. Его максимальная пропускная способность FP32 оценивается в 15 TFLOP/s, с максимальной пропускной способностью 7.5 TFLOP/s для FP64. Тензорные ядра «эффективно» работают на скорости 120 TFLOP/s, чтобы выполнять свою очень специализированную задачу обучения глубоких нейронных сетей. Эти компоненты имеют матричные единицы умножения, ключевой математической операцией в обучении нейронной сети. Они ускоряют постройку/тренировку нейронной сети в 12 раз.
Похожие:
AMD Radeon «Big Navi» протестирован в Firestrike…
Microsoft выпускает Windows 10 October 2021 Update
Утечка спецификаций AMD Radeon RX 6000-й серии: RX 6900 XT,…
Построенный на новом 12-нанометровом процессе, GV100 является многочиповым модулем с площадью кристалла 815 мм² с гигантским количеством транзисторов 21.1 миллиарда, рядом соседствуют четыре 32-гигабитных микросхемы памяти HBM2, объём которой составляет 16 ГБ. Эти стеки взаимодействуют с GV100 посредством 4096-битного интерфейса памяти через кремниевый интерполятор. С эффективной частотой 1 ГГц, GV100 обеспечивается пропускной способностью в районе 1 ТБ/с. Память HBM2 все ещё остаётся эксклюзивной для семейства Tesla в продуктовой линейке NVIDIA, поскольку она продолжает быть дорогостоящей в потребительском сегменте для NVIDIA. Однако потребительские реализации «Вольта» могут включать недорогую, но довольно быструю память GDDR6. Одни из новаторских производителей HBM, SK Hynix, даже продемонстрировал GDDR6 в GTC, поэтому, если NVIDIA не собирается бороться за очередной отрыв-скачок в производительности по сравнению с продуктами AMD, ожидаемо, что компания станет придерживаться GDDR6 в потребительском сегменте.
Карточка Tesla V100 HPC будет разработана в двух пакетах: интегрированных плат с интерфейсом NVLink для более высокой плотности сборки ферм и дополнительных плат с интерфейсом PCI-Express для рабочих станций. Продажа будет осуществляться по специализированным розничным каналам.
С уважением, procompsoft.ru
Тест и обзор: NVIDIA Titan V – архитектура Volta в играх
Страница 1: Тест и обзор: NVIDIA Titan V – архитектура Volta в играх
На прошлой неделе NVIDIA приготовила для нас еще один сюрприз, объявив новую видеокарту NVIDIA Titan V. А именно первую модель на новой архитектуре Volta для потребительского рынка, которая может заинтересовать и геймеров. Хотя видеокарта все же нацелена на профессиональны пользователей. Видеокарта за 3.100 евро поступила в нашу тестовую лабораторию, будет интересно посмотреть на ее результаты в играх.
По NVIDIA Titan V хорошо видно стратегию NVIDIA на 2018 год. Мы уже неоднократно отмечали, что в будущем NVIDIA будет следовать двумя путями – профессиональный сегмент получит собственные вычислительные ускорители, а для геймеров NVIDIA представит оптимизированные или упрощенные GPU. Архитектура Volta как раз следует первому пути, в играх многие архитектурные функции Volta просто не нужны. В любом случае, прогресс по потоковым процессорами и памяти оказался весьма существенным.
Весной NVIDIA представила видеокарту GeForce GTX 1080 Ti, как раз через 12 месяцев после появления архитектуры Pascal в видеокартах GeForce. Конечно, видеокарту GeForce GTX 1070 Ti можно назвать переходной моделью на пути к новой архитектуре, но NVIDIA за последние 24 месяца предлагала геймерам только одну архитектуру, пусть и с разными вариантами реализации. NVIDIA была вполне довольна архитектурой Pascal, которая используется на всех уровнях производительности, от low-end до high-end. Однако некоторые геймеры начали сетовать на застой, ожидая от NVIDIA новых сильных шагов.
Архитектура Volta была представлена на конференции GPU Technology Conference весной. Ускорители Tesla V100 наши свое применение в суперкомпьютерах. Но следует учитывать огромный размер GPU, его сложность и тот факт, что от многих компонентов GPU, тех же блоков FP64 или Tensor Cores, геймер не выиграет. Поэтому данный GPU вряд ли выйдет на видеокартах GeForce. Также он сопровождается дорогой памятью HBM2, которая по доле выхода годных кристаллов и частотам не оправдала первоначальных планов.
На GTC 2017 NVIDIA рассказала об улучшениях потоковых процессоров, что само по себе должно обеспечить прирост производительности. GPU GV100 оснащен 5.120 потоковыми процессорами, что на 43% больше, чем у GPU GP102 видеокарты GeForce GTX 1080 Ti. Память HBM2 с пропускной способностью 653 Гбайт/с вряд ли будет ограничивать вычислительную производительность.
Конечно, нам было интересно оценить производительность NVIDIA Titan V в играх. Пусть даже видеокарта стоит около 3.100 евро, но она позволит пролить свет на то, что можно ожидать в 2018 году. Уже появились слухи о том, что грядущая архитектура GPU от NVIDIA будет называться Ampere. Она вновь будет ориентирована на видеокарты GeForce. Но Ampere вряд ли станет полностью новой разработкой. Вполне возможно, что мы получим ту же архитектуру Volta без блоков, ориентированных на вычислительную/научную сферу. И с памятью GDDR5X или GDDR6. С данной точки зрения Titan V можно считать окном в будущее.
| Модель: | NVIDIA Titan V | |||
| Цена: | 3.100 евро | |||
| Сайт производителя: | NVIDIA | |||
| Техническая информация | ||||
|---|---|---|---|---|
| GPU: | GV100 | |||
| Техпроцесс: | 12 нм | |||
| Число транзисторов: | 21,1 млрд. | |||
| Тактовая частота GPU (базовая): | 1.200 МГц | |||
| Тактовая частота GPU (Boost) | 1.455 МГц | |||
| Частота памяти | 1.850 МГц | |||
| Тип памяти | HBM2 | |||
| Объём памяти | 12 GB | |||
| Ширина шины памяти | 3.072 бит | |||
| Пропускная способность памяти | 652,8 Гбайт/с | |||
| Версия DirectX: | 12 | |||
| Потоковые процессоры: | 5.120 | |||
| Текстурные блоки: | 320 | |||
| Конвейеры растровых операций (ROP): | 96 | |||
| Типичное энергопотребление: | ||||
| SLI/CrossFire | — | |||
Подобно многим предыдущим архитектурам, в том числе Pascal, чип Volta GV100 состоит из кластеров Graphics Processing Clusters (GPCs), Texture Processing Clusters (TPCs), Streaming Multiprocessors (SMs) и контроллера памяти. GPU GV100 оснащен шестью GPCs, 84 Volta SMs, 42 TPCs (один на два SMs) и восемью 512-битными контроллерами памяти (4.096 бит в сумме). Каждый SM имеет 64 ядра FP32, 64 ядра INT32, 32 ядра FP64 и восемь новых ядер Tensor. Также каждый SM содержит четыре текстурных блока.
Но NVIDIA пока не использует полную версию чипа ни для Tesla V100, ни для Titan V. Активны 80 Volta SMs, что как раз дает 5.120 потоковых процессоров. Также отметим 2.560 блоков FP64, а привычные потоковые процессоры теперь называются FP32. Для сферы глубокого обучения будут полезны 640 ядер Tensor, которые выполняют вычисления INT8. Для процесса тренировки сетей глубокого обучения наиболее важны операции матричного умножения (BLAS GEMM), именно на них ориентированы ядра Tensor. У ядер Tensor в SM имеются собственные пути передачи данных, их также можно полностью выключать с помощью стробирования частоты, если ядра не требуются. Каждое ядро Tensor может обрабатывать матрицу 4 x 4 x 4 в виде D = A x B + C. Входные матрицы A и B относятся к типу FP16, для сложения может использоваться матрица FP16 или FP32. Каждое ядро Tensor выполняет 64 операции FMA со смешанной точностью за такт – каждая такая операция может содержать умножение и сложение. В итоге восемь ядер Tensor на SM обеспечивают производительность 1.024 операций с плавающей запятой за такт.
Каждый стек памяти HBM2 подключен к двум контроллерам памяти. В общей сложности GPU GV100 оснащен восемью 512-битными контроллерами памяти. Но в случае Titan V активны только шесть контроллеров, то есть ширина интерфейса памяти составляет 3.072 бита. В результате объем памяти составляет 12 Гбайт HBM2, частота 850 МГц, пропускная способность 652,8 Гбайт/с. NVIDIA использует три стека HBM2 вместо четырех. Не совсем понятно, является ли такая конфигурация следствием одного дефектного стека. Или NVIDIA просто адресует два стека из четырех с половинной емкостью. Отметим 768 кбайт кэша L2 у каждого контроллера, причем с одним стеком HBM2 работают два контроллера. Таким образом, у GPU GV100 кэш L2 в нашем случае составляет 4.608 кбайт (6.144 кбайт у полной версии).
NVIDIA внесла изменения в дизайн потоковых мультипроцессоров, которые имеют мало общего с предыдущими поколениями Maxwell и Pascal. Впрочем, все эти изменения связаны с одним: с увеличением вычислительной производительности. Если SMs в GP100 GPU (Pascal) состоят из двух вычислительных блоков, каждый с 32 ядрами FP32, 16 ядрами FP64, буфером инструкций, диспетчером warp, двумя блоками распределения и 128-кбайт файлом регистров, в случае архитектуры Volta мы получили заметные изменения. SM в составе GPU GV100 разделены уже на четыре вычислительных блока. Каждый состоит из 16 ядер FP32, 8 ядер FP64, 16 ядер INT32, двух новых ядер Tensor со смешанной точностью, нового кэша инструкций L0, диспетчера warp, блока распределения и 64-кбайт файла регистров. В отличие от архитектуры Pascal, которая не допускала одновременное выполнение инструкций FP32 и INT32, в случае Volta одновременное выполнение возможно благодаря отдельным блокам в SM, что тоже увеличивает вычислительную производительность.
Поскольку NVIDIA фокусировалась на вычисления на GPU, влияние архитектурных изменений на игровую производительность оценить сложно. Свежий драйвер GeForce поддерживает Titan V на архитектуре Volta, но оптимизации в нем наверняка не такие существенные. В любом случае, будет интересно оценить прирост производительности, связанный не только с увеличением числа потоковых процессоров.
Скриншоты GPU-Z подтверждают технические спецификации NVIDIA Titan V. Ниже представлены тактовые частоты GPU под нагрузкой.
| Игра | Температура | Частота |
| The Witcher 3: Wild Hunt | 84 °C | 1.719 МГц |
| Rise of the Tomb Raider | 84 °C | 1.706 МГц |
| Hitman | 84 °C | 1.706 МГц |
| Far Cry Primal | 84 °C | 1.719 МГц |
| DiRT Rally | 84 °C | 1.740 МГц |
| Anno 2205 | 84 °C | 1.719 МГц |
| The Division | 84 °C | 1.740 МГц |
| Fallout 4 | 84 °C | 1.719 МГц |
| DOOM | 84 °C | 1.740 МГц |
Эталонный кулер NVIDIA нам хорошо знаком. Неудивительно, что Titan V всегда упирается в ограничения по температуре. Подобную картину мы уже встречали с видеокартой GeForce GTX 1080 Ti, да и Titan Xp не могла полностью раскрыть потенциал производительности. Тем более что вентилятор не пытается снизить температуру, под полной нагрузкой скорость вращения составила всего 2.375 об/мин. Однако вместо заявленной частоты Boost 1.455 МГц мы получаем существенно более высокие частоты от 1.706 до 1.740 МГц.
<>Тест и обзор: NVIDIA Titan V – архитектура Volta в играхNVIDIA Titan V — впечатления (1)
Производительность NVIDIA Volta GV100 может достигнуть 9,5 терафлопс
Как известно, следующим после Pascal поколением графических процессоров NVIDIA является Volta. Впрочем, к современным чипам название «графический процессор» применимо всё меньше — с тех пор, как их архитектура стала полностью унифицированной и программируемой, они прочно утвердились в различных проектах суперкомпьютеров, некоторые из которых уже вступили в строй и вовсю заняты научными и другими сложными вычислениями. Создавая свой первый чип Pascal GP100, NVIDIA уделила больше внимания его вычислительным возможностям, нежели графическим, и, похоже, первенца в семействе Volta, чип GV100, ожидает аналогичный подход.
Новый принцип построения узлов суперкомпьютера. Количество плат ускорителей не соответствует указанному в заметке
Уже подтверждено, что GV100 станет сердцем, а точнее, сердцами суперкомпьютеров Summit в Национальной лаборатории Ок-Ридж (Oak Ridge National Laboratory) и Sierra в Ливерморской национальной лаборатории (Lawrence Livermore National Laboratory). Первый проект должен войти в рабочую стадию в начале 2018 года и развить пиковую мощность 200 петафлопс, что существенно превышает показатель самого быстрого сегодняшнего китайского суперкомпьютера Sunway TaihuLight, чьи возможности оцениваются в 125,4 петафлопса. К сожалению, о характеристиках и архитектуре GV100 мы до сих пор знаем не так много, как хотелось бы, но кое-какие сведения о проекте Summit позволяют сделать некоторые выводы.
Лаборатория в Ок-Ридже опубликовала слайд, на котором Summit сравнивается с суперкомпьютером Titan, базирующимся на чипах Kepler GK110. Состоит он из 18688 узлов, мощность каждого из них составляет 1,4 терафлопса. На том же плакате указаны спецификации Summit: 4600 узлов с мощностью более 40 терафлопс на узел. Указано также, что в каждом узле будет 512 Гбайт памяти DDR4, 800 Гбайт энергонезависимой памяти и некий объём памяти HBM (речь, разумеется, идёт о HBM2). Основой каждого узла станут пара процессоров IBM POWER9 и шесть процессоров NVIDIA Volta. Чипы POWER9, помимо традиционных линий PCI Express (версия 4.0) имеют и 48 линий интерфейса Bluelink, который будет работать в режиме NVLink 2.0 и соединять их с процессорами Volta, что позволит процессорам различных архитектур делить общее пространство памяти, практически не теряя в скорости: пропускная способность может составлять от 80 до 200 Гбайт/с.
Использование NVLink экономит энергию и повышает производительность
Потребляемая Summit мощность составит 13 мегаватт — всего на 4 мегаватта больше, нежели у Titan, при более чем десятикратном превосходстве в производительности. Как мы знаем, NVIDIA объявила о том, что GV100 будет демонстрировать эффективность 72 гигафлопса на ватт при операции перемножения матриц с одинарной точностью (Single precision floating General Matrix Multiply). Для GP100 этот показатель равен 42 гигафлопса на ватт. Нетрудно посчитать, приняв за основу теплопакет GV100 на уровне 300 ватт, что этот чип в теории может достичь производительности 9,5 терафлопс на вычислениях двойной точности (FP64). Шесть чипов GV100 при потреблении не выше 300 ватт на чип как раз и дадут упомянутые на плакате «более 40 терафлопс», а точнее, в теории, смогут выдать 57,2 терафлопса. Даже при конфигурации с теплопакетом 200 ватт и на 20‒25 % более низкой производительности производительность узла составит 45,6 терафлопс, так что у создателей Summit явно есть задел по части экономии электроэнергии при сохранении заявленных характеристик. По крайней мере, такой подход может существенно облегчить работу холодильных установок Summit.
Источник:
Сопроцессоры NVIDIA Tesla
NVIDIA Tesla V100 SXM2
Графический ускоритель Tesla V100 с тензорными ядрами – самый технически продвинутый в мире GPU для дата-центров, предназначенный для ускорения искусственного интеллекта, HPC, наука о данных и графики. Созданный на основе архитектуры NVIDIA Volta, он доступен в конфигурации с 16 или 32ГБ памяти и обеспечивает производительность на уровне 100 CPU.
Спецификация:
- Вычислительные ядра: CUDA 5120, Tensor 640
- Оперативная память: 32GB HBM2
- Полоса пропускания памяти (без ECC) 900 GB/s
- Пиковая производительность Tensor Performance 125 Tflops
- Пиковая производительность DP 7,8 Tflops
Запросить цену в проект
NVIDIA TESLA V100S
Графический ускоритель Tesla V100S с тензорными ядрами – самый технически продвинутый в мире GPU для дата-центров, предназначенный для ускорения искусственного интеллекта, HPC, наука о данных и графики. Созданный на основе архитектуры NVIDIA Volta, он доступен в конфигурации с 16 или 32ГБ памяти и обеспечивает производительность на уровне 100 CPU.
Спецификация:
- Вычислительные ядра: CUDA 5120, Tensor 640
- Оперативная память: 32GB HBM2
- Полоса пропускания памяти (без ECC) 1134 GB/s
- Пиковая производительность Tensor Performance 130 Tflops
- Пиковая производительность DP 8,2 Tflops
Запросить цену в проект
NVIDIA TESLA K80
Tesla K80 GPU создан для выполнения самых требовательных к ресурсам вычислительных задач. Этот GPU идеально подходит для вычисления операций с двойной точностью, для которых требуется не только высокая производительность вычислений, но и высокая пропускная способность памяти.
Спецификация:
- Вычислительные ядра 4992
- Оперативная память: 24GB GDDR5
- Полоса пропускания памяти (без ECC) 480 GB/s
- Пиковая производительность SP 8.73 Tflops
- Пиковая производительность DP 2.91 Tflops
Запросить цену в проект
NVIDIA TESLA T4
GPU NVIDIA® T4 ускоряет различные задачи в облаке, в том числе высокопроизводительные вычисления, тренировку и инференс алгоритмов глубокого обучения, машинное обучение, анализ данных и работу с графикой. T4 создан на базе новой архитектуры NVIDIA Turing™ и заключен в компактный форм-фактор PCIe с уровнем энергопотребления 70 Вт.
Спецификация:
- Вычислительные ядра: CUDA 2560, Tensor 320
- Оперативная память: 16GB GDDR6
- Полоса пропускания памяти 300 GB/s
- Пиковая производительность Mixed Precision 65 Tflops
- Пиковая производительность INT8 130 Tflops
- Пиковая производительность INT4 260 Tflops
Запросить цену в проект
NVIDIA TESLA M60
Графический ускоритель Tesla M60 специально создан для дата-центров, предназначенных для десктопной виртуализации. Его двухслотовый форм-фактор для стоечных и напольных серверов позволяет одновременно поддерживать 32 пользователя.
Спецификация:
- Вычислительные ядра 4096
- Оперативная память: 16GB GDDR5
- Полоса пропускания памяти (без ECC) 160 Gb/s x 2
- Пиковая производительность SP 8 Tflops
- Пиковая производительность DP 0,2 Tflops
Запросить цену в проект
NVIDIA TESLA P100
Графический ускоритель Tesla P100 позволяет создавать новый класс серверов с производительностью уровня нескольких сотен классических серверов на базе CPU. Ускоритель Tesla P100, основанный на новой архитектуре NVIDIA Pascal™ с пятью передовыми технологиями, обеспечивает несравненную производительность и экономичность для самых ресурсоемких приложений.
Спецификация:
- Вычислительные ядра 3584
- Оперативная память: 16GB HBM2 4096-bit
- Полоса пропускания памяти (без ECC) 720 GB/s
- Пиковая производительность HP 18.7 Tflops
- Пиковая производительность SP 9.3 Tflops
- Пиковая производительность DP 4.7 Tflops
Запросить цену в проект
NVIDIA TESLA P40
Графический ускоритель Tesla P40 создан специально для тренировки алгоритмов глубокого обучения. Он является самым быстрым ускорителем глубокого обучения в дата-центрах. В основе Tesla P40 лежит архитектура NVIDIA Pascal™. Серверы на основе Tesla P40 превосходят по производительности серверы на базе CPU в 17 раз
Спецификация:
- Вычислительные ядра 3840
- Оперативная память: 24GB GDDR5
- Полоса пропускания памяти 346 GB/s
- Пиковая производительность SP 12 Tflops
- Пиковая производительность INT8 47 TOPS
Запросить цену в проект
NVIDIA TESLA P4
Графический ускоритель Tesla P4 создан специально для тренировки алгоритмов глубокого обучения. Он является самым быстрым ускорителем глубокого обучения в дата-центрах. В основе Tesla P4 лежит архитектура NVIDIA Pascal™. Серверы на основе Tesla P4 превосходят по производительности серверы на базе CPU в 13 раз
Спецификация:
- Вычислительные ядра 2560
- Оперативная память: 8GB GDDR5
- Полоса пропускания памяти 288 Gb/s x 2
- Пиковая производительность SP 5.5 Tflops
- Пиковая производительность INT8 21.8 TOPS
Запросить цену в проект
Новый графический чип обошелся Nvidia в $3 млрд
| Поделиться Nvidia представила ряд новых технологий в области машинного обучения, ИИ и «облаков», а также анонсировала новые направления сотрудничества с Toyota и SAP. Разработка чипа Volta GV100 в новой архитектуре обошлась компании в $3млрд.Новое поколение производительной графики
Nvidia в рамках конференции GTC 2017 анонсировала новое поколение графической архитектуры Volta, первый графический процессор Volta GV100 на его основе, а также первый графический ускоритель на этом чипе – Tesla V100, предназначенный для работы в составе производительных дата-центров.
По словам Дженсена Хуанга (Jen-Hsun Huang), представившего новую архитектуру, разработка чипа обошлась компании примерно в $3 млрд. Новый чип содержит более 5000 потоковых процессоров, новые исполнительные блоки Tensor для увеличения производительности в матричных вычислениях. Процессор Volta GV100 также обладает кеш-памятью первого и второго уровней, текстурными блоками, контроллером VRAM, системным интерфейсом и по 8 блоков Tensor на мультипроцессорный кластер (SM), в сумме 672 блоков.
Как отметил в своем выступлении Дженсен Хуанг, архитектура Nvidia Volta призвана стать катализатором новой волны достижений в области искусственного интеллекта и высокопроизводительных вычислений. Первый процессор на базе Volta – GPU Tesla V100, разработан специально для дата-центров и обеспечивает высокую скорость и масштабируемость обучения и взаимодействия глубоких нейронных сетей, а также ускоряет высокопроизводительные и графические вычисления.
Подробности о новой архитектуре
Volta представляет собой седьмое поколение графических архитектур Nvidia. По данным компании, чип обеспечивает производительность задачах в глубокого обучения, эквивалентную производительности 100 современных процессоров.
Дженсен Хуанг, глава Nvidia, представляет процессор Volta
Пиковая производительность Volta в 5 раз выше предыдущей архитектуры Nvidia Pascal и в 15 раз выше производительности представленной два года назад архитектуры Nvidia Maxwell. По данным компании, темпы роста производительности графических архитектур Nvidia вчетверо больше того, что предсказывал закон Мура.
Новый процессор содержит порядка 21,1 млрд транзисторов, площадь его кристалла составляет 815 кв. мм.
Графический процессор Volta GV100
Выпуском графических процессоров Nvidia GV100 займется тайваньский производственный холдинг TSMC. Чипы будут производиться по технологическому процессу FFN с соблюдением норм 12-нм.
В Nvidia планируют, что архитектура Volta станет новым стандартом высокопроизводительных вычислений. Благодаря объединению ядер CUDA и нового ядра Volta Tensor в унифицированной архитектуре, один сервер на базе GPU Tesla V100 сможет заменить сотни центральных процессоров в высокопроизводительных вычислениях. Матричные вычисления в блоках Tensor увеличивают производительность нового ядра в задачах машинного обучения до 120 Тфлопс, быстродействие GV100 в вычислениях с точностью FP32 составляет 15 Тфлопс, FP64 7,5 Тфлопс.
Дженсен Хуанг, глава Nvidia, рассказывает о воможностях архитектуры Volta
Список ключевых технологий GPU Tesla V100, которые позволили преодолеть 100-терафлопсный рубеж в задачах глубокого обучения, включает специализированные ядра Tensor, созданные для ускорения работы искусственного интеллекта. Оснащенный 640 ядрами Tensor, процессор V100 обеспечивает производительность 120 терафлопс в глубоком обучении, что эквивалентно производительности 100 CPU.
Новый GPU для дата-центров
Интерфейс NVLink поднимает на новый уровень скорость взаимодействия между графическими и центральным процессорами, вдвое увеличивая пропускную способность по сравнению с предыдущим поколением NVLink.
Графическая память HBM2 DRAM с производительностью до 900 ГБ/с, разработанная совместно с Samsung, увеличивает полосу пропускания на 50% по сравнению с предыдущим поколением. Ядро Volta GV100 взаимодействует с буферной памятью HBM2 по 4096-битной шине.
Тактовая частота ядра Volta GV100 составляет 1455 МГц. Энергопотребление ускорителя Tesla V100 не превышает 300 Вт, что практически сравнимо с показателями ускорителя предыдущей архитектуры Tesla P100.
Графический процессор Volta GV100
В рамках анонса также было представлено программное обеспечение с оптимизацией под архитектуру Volta, включая CUDA, cuDNN и TensorRT.
Новые суперкомпьютеры DGX на базе Volta
Вместе с новой архитектурой Nvidia также представила обновленную линейку суперкомпьютеров с искусственным интеллектом DGX AI. Системы построены на GPU Nvidia Tesla V100 и используют полностью оптимизированное для задач ИИ программное обеспечение.
Суперкомпьютеры DGX на базе Volta
Производительность такой системы втрое выше, чем у предыдущего поколения DGX, и соответствует мощности примерно 800 CPU в рамках всего одной системы.
Платформа Nvidia GPU Cloud
Кризис кадров: крупный вендор сам будет готовить ИТ-специалистов для российских компаний
ИнфраструктураНовая Nvidia GPU Cloud (NGC) представляет собой облачную платформу с удобным удаленным доступом для разработчиков — с помощью ПК, системы DGX или облака, к полноценному набору инструментов внедрения ИИ.
Благодаря NGC, разработчики смогут получать доступ к новейшим оптимизированным фреймворкам и передовым ускорителям.
Nvidia и сотрудничество с Toyota
На GTC 2017 также было объявлено о сотрудничестве Nvidia и Toyota.
Toyota планирует начать внедрение автомобильной вычислительной платформы с поддержкой искусственного интеллекта Nvidia DRIVE PX в системы автономного вождения, запланированные к выводу на рынок в течение ближайших лет.
Команды инженеров обеих компаний уже работают над созданием программного обеспечения на ИИ-платформе Nvidia, которое позволит лучше понимать огромные объемы данных, получаемых с автомобильных датчиков, и автономно справляться с широким спектром ситуаций на дороге.
Для того чтобы справляться с задачами подобного уровня вычислительной сложности, в прототипах автомобилей зачастую используют мощные компьютеры, которые занимают весь багажник. Платформа Nvidia DRIVE PX на базе процессора нового поколения Xavier помещается в руке, обеспечивая при этом до 30 млрд операций глубокого обучения в секунду.
Проект SAP Brand Impact
На конференции был представлен проект SAP Brand Impact на базе решений Nvidia для глубокого обучения. Проект обеспечивает измерение атрибутов бренда – например, логотипов, практически в реальном времени.
Эффективный анализ видеоконтента стал возможен благодаря использованию для анализа глубоких нейросетей, обученных на Nvidia DGX-1 и TensorRT.
Проект SAP Brand Impact
«С такими партнерами как Nvidia, наши возможности безграничны, — отметил CIO SAP Юрген Мюллер (Juergen Mueller). – Новые приложения, беспрецедентная производительность с нынешних приложениях и простой доступ к сервисам машинного обучения обеспечит вам высокий уровень интеллекта вашего собственного предприятия».
О конференции GTC 2017
Ежегодная конференция Nvidia по GPU-технологиям – GPU Technology Conference (GTC), проходит на этой неделе в Сан-Хосе, Калифорния.
В конференции принимают участие порядка 7000 специалистов, для которых будет представлено около 600 технических сессий, 150 стендов, 310 сессий по искусственному интеллекту и 67 лабораторий по технологиям глубокого обучения (Deep Learning).
Владимир Бахур
Дата выпуска графического процессора Nvidia Volta, характеристики, слухи и производительность
Несмотря на много шума о потенциальной архитектуре графического процессора Turing, графическая технология Nvidia Volta по-прежнему остается нашим лучшим выбором для того, что станет основой следующего поколения видеокарт Nvidia.
К сожалению, на данный момент кремний Volta упаковывается только в машины профессионального уровня. Но с объявлением о том, что к концу года в компьютерных играх появится трассировка лучей в реальном времени, а технология RTX встроена в последние версии драйверов, нам понадобится новое поколение графических процессоров с мощью Volta внутри.
И в связи с тем, что в конце августа состоится одно из крупнейших игровых событий года — Gamescom, конечно, — мы уверены, что знаем, когда Nvidia может упустить что-то интересное.
Volta — это кремниевый преемник графических карт поколения Pascal — того же поколения, которое принесло нам мощные карты GTX 1080 Ti и Titan Xp. Но могут ли какие-либо будущие карты с питанием от Volta продолжать обеспечивать такой же прирост производительности от поколения к поколению, который обеспечивает впечатляющая графическая микросхема Nvidia последнего поколения? И будет ли он называться Volta, когда достигнет своего уровня GeForce?
Основная статистика Дата выпуска Nvidia Volta
Следующее поколение массовых графических процессоров должно быть подробно описано на симпозиуме Hot Chips 20 августа.Это означает, что мы должны увидеть первые игровые видеокарты, основанные на архитектуре Volta или ее производных, примерно в это время или раньше.
Nvidia Volta specs
Volta профессионального класса — Tesla V100 — использует 12-нм дизайн TSMC FinFET, а полный графический процессор GV100 имеет 5376 ядер CUDA. Представьте себе GTX 2080 Ti с этим.
Цена Nvidia Volta
Не стреляйте в мессенджер, но вполне возможно, что потребительские карты Volta снова поднимут цены. 699 долларов за GTX 1180/2080? Не за гранью возможностей…
Производительность Nvidia Volta
Мы слишком рано находимся в цикле выпуска, чтобы какие-либо цифры производительности летали вокруг, но мы надеемся на большую эффективность и на то, что последняя архитектура Nvidia будет лучше работать и обеспечивать более высокую частоту кадров, с API DX12 и Vulkan.
По обыкновению Nvidia, новая архитектура графического процессора получила свое название в честь известного ученого-историка. Алессандро Вольта дал свое имя Volt, который был пионером в области производства электроэнергии и ее хранения. Он также был первооткрывателем донного газа, метана — забавный маленький научный факт для вас. Всегда учусь, всегда учу…
Но в последнее время ходят самые тонкие слухи о выпуске новых кодовых имен Nvidia Ampere и Nvidia Turing в качестве следующих графических чипов от Nvidia skunkworks.Черт, мы, , можем придумывать ложные кодовые имена GPU во сне…
Оба названия GPU взяты из одной строчки в двух разрозненных статьях, посвященных финансовым результатам Nvidia, и не имеют источников, чтобы хоть как-то поверить в эти названия. Если это или , они могут быть исключительно тем, что Nvidia использует для ссылки на игровые варианты базовой технологии Volta, используемой в грядущей GTX 1180 или GTX 2080, в зависимости от того, как они называются.
ОднакоVolta — это архитектура графического процессора, которая определенно существует и была впервые представлена - по крайней мере в теоретической форме — на конференции Nvidia по графическим технологиям еще в 2013 году.Первоначально он задумывался как микросхема графического процессора, которая последовала непосредственно за архитектурой Maxwell (которая составляла графические карты серии GTX 900), но год спустя появляется дизайн Pascal, используемый в самых последних частях GeForce 10-й серии. , отодвигая перспективные чипы Nvidia Volta еще дальше.
Что подводит нас к…
Nvidia Volta дата выпуска
Первая конкретная новость, которую мы получили о следующем поколении видеокарт GeForce, — это объявление, которое Стюарт Оберман из Nvidia представит на симпозиуме Hot Chips 20 августа.Выступление носит скромное название «Основной графический процессор Nvidia следующего поколения» и не упоминает ни названия новых карт, ни основную архитектуру, которую они будут использовать.
Однако похоже, что Nvidia не была довольна этим раскрытием, и Hot Chips с тех пор пришлось удалить любое упоминание команды GeForce, говорящей о своих графических процессорах следующего поколения. Слот для графических решений сейчас — это просто большой жир, подлежащий уточнению, и Hot Chips также удалили упоминание о «графическом процессоре следующего поколения» из своего пресс-релиза. Это, вероятно, не означает, что разговор был отменен, но Nvidia не хотела, чтобы о ее присутствии обязательно знали.
Кошачий, похоже, сбежал из Mulberry, хотя Jen-Hsun выступил с заявлением незадолго до начала выставки Computex в Тайбэе, заявив, что его новые карты не будут выпущены «в течение длительного времени».
Однако, если это произойдет, это будет не первый раз, когда видеокарты, потенциально работающие на базе Volta, будут представлены, так что это означает, что мы, вероятно, представим их где-то около 20 августа. Gamescom стартует на следующий день после выступления Обермана. , так что не глупо ожидать, что в Германии упадет популярность GeForce.
Согласно предыдущим слухам, видеокарты Nvidia Volta готовятся к запуску в третьем квартале 2018 года. Недавний отчет Tom’s Hardware привязал выпуск к июлю, когда AIB получат карты примерно 15 июня или около того. нас, и мы все еще делаем ставку на запуск в конце августа.
SK Hynix, как сообщается, наращивает производство GDDR6, которую Nvidia, как сообщается, также использует исключительно со своими неизданными видеокартами.
Когда компания Hynix впервые объявила о выпуске GDDR6, она упомянула, что «планирует массовое производство продукта для клиента, который выпустит высокопроизводительную видеокарту [sic] к началу 2018 года, оснащенную высокопроизводительными модулями DRAM GDDR6.«Я не единственный, кто думает, что это отсылка к Nvidia и выпуску графических процессоров Volta на базе GDDR6.
Samsung также объявила, что ее собственная память GDDR6 будет «играть критически важную роль в ранних выпусках видеокарт следующего поколения», что подтверждает наши подозрения относительно запуска в начале 2018 года. Хотя это могло быть просто потому, что мы отчаянно нуждаемся в выпуске нового графического процессора, чтобы потенциально вылечить кризис криптовалюты, который украл все наши видеокарты…
Ожидается, что эти микросхемы памяти с самого начала будут на 20% дороже для производителей, чем GDDR5, хотя в конечном итоге они упадут в цене по мере того, как производственные мощности отходят от старых стандартов.Тем не менее, это будет не так дорого, как HBM от Vega…
Мы думали, что Nvidia выпустит что-то на GDC в этом году, но наши источники в зеленой команде сказали нам, что в марте она категорически не собирается выпускать новый графический процессор. Также компания не запустила ничего, связанного с играми, на GTC неделю спустя — все это было просто глубокое обучение, искусственный интеллект и т. Д. То же самое нам сказали и о Computex. Nvidia сообщила нам, что готовится к большой Gamescom, но не дала никаких дополнительных подробностей о том, что это может означать.
Самое близкое, что мы подошли к настоящей видеокарте на базе Nvidia Volta, которую мы могли бы вставить в наши ПК, — это Titan V за 3000 долларов. GTX 1180 следующего поколения.
Nvidia Volta характеристики
Вы могли быть прощены за то, что вы были взволнованы, когда множество новостных агентств начали кричать о том, что Nvidia GTX 1180 занесена в онлайн-базу данных графического процессора, но я сожалею, что это был просто заполнитель.
TechPowerUp только что заполнил свою базу данных, используя текущие слухи, и высказал предположения о тактовых частотах графического процессора и памяти с использованием существующих частот Pascal 10-й серии, и затем это было представлено как утечка многими людьми, сообщившими об этом в Интернете.
К сожалению, мы все еще не знаем, какими будут карты следующего поколения, как они будут называться и когда они появятся. Насколько нам известно, ее все еще можно было бы назвать GTX 2080, когда в конце концов появится топовая карта нового поколения.
Фактически, недавнее пополнение запасов карт 10-й серии компанией Nvidia кажется свидетельством того, что они не собираются поступать в продажу в ближайшее время.
Приточный пробег. pic.twitter.com/B1AQRkgnwV
— NVIDIA GeForce (@NVIDIAGeForce) 9 мая 2018 г.
Однако все выпущенные графические процессоры Volta — от Tesla V100 до Titan V и Quadro GV100 — используют ту же 12-нм литографию TSMC. TSMC также заявила, что приступит к массовому производству своих 12-нм чипов FinFET в четвертом квартале 2017 года, поэтому мы ожидали полного запуска потребительских карт Nvidia Volta в начале 2018 года.
Первоначально предполагалось, что Volta будет построена с использованием нового 10-нм техпроцесса TSMC, но темпы усадки транзисторов в последние годы стали довольно медленными. По другим слухам, Nvidia придерживалась существующей 16-нм технологии TSMC, чтобы иметь возможность придерживаться своей дорожной карты и получить настоящие карты Nvidia Volta на полках в 2018 году. Теперь это похоже на что-то среднее между ними.
| Тесла V100 | Титан V | Quadro GV100 | Тесла P100 | GTX 1080 Ti | |
| Литография | 12-нм FinFET | 12-нм FinFET | 12-нм FinFET | 16 нм FinFET | 16 нм FinFET |
| Количество транзисторов | 21млрд | 21млрд | 21млрд | 15млрд | 12млрд |
| Размер матрицы | 815 мм2 | 815 мм2 | 815 мм2 | 610 мм2 | 471 мм2 |
| ядер CUDA | 5,120 | 5,120 | 5,120 | 3,584 | 3,584 |
| Память | 32 ГБ HBM2 | 12 ГБ HBM2 | 32 ГБ HBM2 | 16 ГБ HBM2 | 11 ГБ GDDR5X |
| Пропускная способность памяти | 900 ГБ / с | 653 ГБ / с | 870 ГБ / с | 732 ГБ / с | 484 ГБ / с |
TSMC, в отличие от Intel Cannonlake, станет скорее временной мерой между нынешним процессом и почти мифической 7-нм литографией.Для сравнения: 7 морских миль — это высота трех Томов Круза, стоящих друг у друга на плечах. Но переход на 10 нм кажется более сложной задачей, чем, возможно, даже ожидала TSMC. Я предполагаю, что либо цена непомерно высока, либо урожайность слишком низкая, чтобы компенсировать преимущества новой конструкции. Или сочетание того и другого.
Узел 12 нм, очевидно, основан на существующей конструкции TSMC 16 нм, но с улучшенными плотностью, производительностью и энергоэффективностью. Будет ли этот 12-нм узел действительно упакован 12-нм транзисторами или это будет просто умный маркетинг, в настоящее время почти так же ясно, как термопаста.
Компоновка графического процессора Volta немного отличается от предыдущих графических процессоров Nvidia, но в основном это позволяет втиснуть все 5120 ядер CUDA. Фактически, полный графический процессор GV100 фактически способен вместить 5376 ядер CUDA, поэтому Titan V а чипы Tesla V100 даже не самые мощные из потенциальных графических процессоров Nvidia Volta.
Маловероятно, что фактическая установка сильно изменится с игровыми вариантами, если не считать вырезанных ядер двойной точности. Если Nvidia следует традиции, из каждого потокового мультипроцессора (SM), составляющего GV104, будет удалено определенное количество неигрового кремния, чтобы сделать более массовые видеокарты.
Но Nvidia заявила, что в архитектуре Volta есть определенное оборудование, которое помогает трассировке лучей для игр, но это не обязательно добавленные ядра Tensor, которые Nvidia добавила в кремний Volta. Это действительно помогает, так что есть большая вероятность, что мы увидим тензорные ядра и в наших игровых чипах. Это означает, что вполне возможно, что в потребительском чипе не будет столько радикальных изменений, сколько мы видели в прошлом.
Что касается конфигурации памяти, то выпущенные графические процессоры Nvidia Volta работают с памятью с высокой пропускной способностью второго поколения (HBM2), но, судя по тому, как SK Hynix и Samsung говорили о GDDR6, мы не ожидаем, что игровые карты Volta будут следуйте той же настройке.И это хорошо. HBM2 может обеспечить серьезные уровни пропускной способности памяти, но GDDR6 по-прежнему довольно быстр и быстрее, чем GDDR5X. Он предлагает скорость передачи данных 16 Гбит / с, в отличие от 14 Гбит / с у GDDR5X, а также большую пропускную способность памяти.
Hynix заявила, что с 384-битной шиной памяти — типом дизайна, который обычно предпочитают высокопроизводительные видеокарты Nvidia — он может предложить пропускную способность памяти до 768 ГБ / с, что не далеко от 900 ГБ / с конструкции HBM2 V100. Titan Xp на базе Pascal использует GDDR5X и может управлять только 548 ГБ / с с его мощной настройкой 12 ГБ.
GDDR6 примерно на 20% дороже в производстве, чем GDDR5, но намного дешевле, чем запретительные цены на HBM2. По сути, именно это подорвало AMD Vega в соотношении цена / производительность, и Nvidia вряд ли совершит ту же ошибку.
Nvidia Volta цена
О, привет, добро пожаловать в угол спекуляции цен. Очевидно, мы не знаем, как Nvidia будет оценивать свои новые карты, но мы все же можем сделать некоторые обоснованные предположения на основе Nvidia passim. И исходя из смехотворной цены на Titan V.
Короче говоря, карты, вероятно, будут дороже, чем старое поколение Паскаля. Ну, в любом случае, по сравнению с первоначальной ценой, не связанной с добычей полезных ископаемых.
Цены на одиночные карты корректируются в сторону повышения, и это сделает карты Volta GeForce вторым поколением подряд, в котором Nvidia подняла цены до небес. С картами на базе Pascal 10-й серии GTX 1080 был выпущен на беспрецедентном уровне, особенно с учетом махинаций эталонного / Founders Edition.
Если 699 долларов станут де-факто стандартом для высокопроизводительных видеокарт Nvidia, как показано на примере видеокарт GTX 1080 Ti, то настали тревожные времена. Если вы не AMD и не уверены, что вы сможете и дальше уступать графическим процессорам Nvidia. Надо, чтобы они были построены в объеме, первые ребята…
Но мы вряд ли увидим какие-либо махинации с Founders Edition с точки зрения ценообразования. Nvidia может по-прежнему называть свои эталонные карты Founders Edition, но я думаю, что времена дополнительной платы за базовый дизайн нагнетателя Nvidia, к счастью, прошли.
Производительность Nvidia Volta
В чистом тесте поколения-поколения между графическими процессорами профессионального уровня Pascal P100 и Volta V100 новая архитектура Nvidia демонстрирует производительность, которая на 132% выше, чем у чипов последнего поколения. Если мы приблизимся к такому уровню прироста производительности игровых приложений, Volta будет ошеломляющим. Это маловероятно, потому что эти тесты основаны на тестах Geekbench, выполняются в среде Linux с использованием специального API CUDA, а не Shadow of War на 4K.
Профессиональные карты Nvidia Volta были настроены специально для рабочих нагрузок AI, с новым дизайном ядра Tensor в его основе. Эти новые кремниевые кусочки не имеют ничего общего с игровой частотой кадров, по крайней мере, на данный момент, поэтому, если это единственные реальные улучшения Volta, вполне возможно, что вообще не будет значительного повышения производительности по сравнению с Pascal.
Очевидно, мы все еще ожидаем некоторого повышения игровой производительности от Volta, и я уже говорил о необходимости того, чтобы он лучше справлялся с низкоуровневыми API-интерфейсами Vulkan и DirectX 12, но мы также должны ожидать некоторого повышения эффективности, рожденного обоими из-за немного сокращенного производственного процесса GPU, а также переделанной архитектуры.
Учитывая, что Вольта является тезкой итальянского джентльмена, которому приписывают изобретение батареи, вы, безусловно, надеетесь на некоторое повышение эффективности. Что касается ноутбуков, Pascal добился больших успехов в повышении производительности мобильных графических процессоров, и Volta должна продвигать этот прогресс еще дальше.
Когда он объявил о существовании кодового имени Nvidia Volta на GTC 2013, Jen-Hsun Huang объяснил, что «мне нравится это имя Volta, потому что оно предполагает, что оно будет еще более энергоэффективным.”
Скрестив пальцы, это не просто предложение…
Самым большим показателем для технологии Volta, встроенной в игровой графический процессор, является внедрение в конце года трассировки лучей в реальном времени.
На GDC Nvidia и Microsoft объявили о партнерстве, которое в этом году принесет в игры трассировку лучей в реальном времени. Большой M приносит отраслевой стандарт через DirectX Raytracing API, а Nvidia создает его с помощью собственного аппаратного ускорителя RTX для своих графических архитектур Volta «и будущих».
RTX построен с использованием набора программных и аппаратных алгоритмов, специально разработанных для архитектуры Nvidia Volta, хотя Nvidia не сообщает нам, в какой именно части конструкции графического процессора используется функция трассировки лучей.
«В Volta определенно есть функция, ускоряющая трассировку лучей, — сказал нам Тони Томази из Nvidia, — но я не могу комментировать, что это такое».
Но у тензорных ядер Volta есть что-то вроде , хотя, по-видимому, только косвенно.Возможности машинного обучения ядер Tensor позволяют Volta делать то, что называется шумоподавлением AI на изображении, что кажется неотъемлемой частью высококачественной трассировки лучей.
«Это также называется реконструкцией», — говорит Томази. «Что он делает, так это то, что он использует меньше лучей и очень интеллектуальные фильтры или обработку, чтобы по существу восстановить окончательное изображение или пиксель. Тензорные ядра использовались для создания того, что мы называем шумоподавителем искусственного интеллекта.
«Используя искусственный интеллект, мы можем обучить нейронную сеть восстанавливать изображение с использованием меньшего количества образцов, поэтому на самом деле ядра Tensor могут использоваться для управления этим шумоподавителем AI, который может создавать гораздо более качественное изображение с использованием меньшего количества образцов.И это один из ключевых компонентов, который помогает раскрыть возможности трассировки лучей в реальном времени ».
Ключевым моментом является то, что Томази считает, что в этом году появятся игры, использующие эффекты трассировки лучей в реальном времени, и это, безусловно, означает, что игровые графические процессоры на базе Volta появятся до конца года.
Либо это, либо целое новое поколение графических процессоров, которые сохранят те же ядра Tensor, ориентированные на ИИ, как у Volta, но без названия.Что могло бы показаться немного странным.
Мы также только что представили наши первые проблески, возможно, первой игры, которая будет включать платформу RTX с ускорением Volta от Nvidia, Metro Exodus. Демонстрация GDC от 4A Games демонстрирует свою последнюю игру, в которой реализованы функции окружающего окклюзии и трассировки лучей непрямого освещения в RTX. К сожалению, запуск игры впоследствии был отложен, поэтому вполне возможно, что сейчас , а не , мы увидим трассировку лучей в реальном времени в играх на этой стороне 2019 года.
Печальные времена.
{«схема»: {«страница»: {«контент»: {«заголовок»: «Дата выпуска графического процессора Nvidia Volta, характеристики, слухи и производительность», «тип»: «оборудование», «категория»: «nvidia «},» user «: {» loginstatus «: false},» game «: {» publisher «:» «,» genre «:» «,» title «:» Nvidia «,» genres «: []}} }}
NVIDIA Ampere A100 — самый быстрый графический процессор AI, в 4,2 раза быстрее, чем Volta V100
NVIDIA только что опубликовала первые реальные показатели производительности своего графического процессора Ampere A100, и результаты просто безумные. Компания побила в общей сложности 16 рекордов производительности в тестах, связанных с ИИ, а также опередила своих основных конкурентов в конкретной категории производительности машинного обучения.
Графический процессор NVIDIA Ampere A100 побил 16 мировых рекордов AI, в 4,2 раза быстрее, чем Volta V100
Результаты получены от MLPerf, отраслевой группы эталонного тестирования, созданной еще в 2018 году с упором исключительно на производительность машинного обучения. Набор тестов состоит из восьми тестов, и NVIDIA установила все рекорды с рекордной скоростью обучения.
NVIDIA RTX A2000 для настольных ПК — это низкопрофильная видеокарта Ampere Workstation
Это третий подряд и самый сильный показатель NVIDIA в обучающих тестах от MLPerf, отраслевой группы тестирования, сформированной в мае 2018 года.NVIDIA установила шесть рекордов в первых тестах обучения MLPerf в декабре 2018 года и восемь в июле 2019 года.
NVIDIA была единственной компанией, представившей коммерчески доступные продукты для всех тестов. В большинстве других представленных материалов использовалась категория предварительного просмотра для продуктов, которые могут быть недоступны в течение нескольких месяцев, или категория исследования для продуктов, которые, как ожидается, будут недоступны в течение некоторого времени.
Блоги NVIDIA
NVIDIA также сообщила о восьми дополнительных рекордах с ее системой DGX SuperPOD, которая представляет собой массивный кластер систем DGX A100 HPC, соединенных вместе через HDR InfiniBand.DGX SuperPod состоит из 140 систем DGX A100 с в общей сложности 1120 графических процессоров NVIDIA Ampere A100, 170 коммутаторов Mellanox Quantum 200G Infiniband, 4 ПБ памяти и 15 км оптического кабеля.
Это около 7,7 миллионов ядер CUDA в системе DGX SuperPod, что просто потрясающе. Система является частью плана расширения DGX V, добавляя почти 700 Петафлопс вычислительной мощности к системе, которая в настоящее время развернута в штаб-квартире NVIDIA в Санта-Кларе, Калифорния.
Тесты производительности AI — Ampere vs Volta & MoreNVIDIA сравнила свой ускоритель Ampere A100 Tensor Core GPU со своим предшественником Volta V100. В сравнение также включены TPU 3-го поколения от Google и чипы Huawei Ascend HPC. Сами MLPerf имеют более подробные списки тестов, а также включают предварительный просмотр будущих ускорителей AI, таких как процессоры Intel Cooper Lake-SP Xeon и TPU 4-го поколения от Google. С учетом сказанного, давайте посмотрим на сами тесты.
Colorful Releases Special Edition iGame RTX 3070 LHR для Bilibili E-Sports Team
Согласно MLPerf, их набор тестов включает тесты, нацеленные на рабочие нагрузки производительности, которые наиболее актуальны в категориях машинного обучения и искусственного интеллекта. NVIDIA Ampere A100 просто разрушает Volta V100 с увеличением производительности в 2,5 раза. Даже при минимальном опережении Ampere A100 обеспечивает прирост на 50% по сравнению с графическим процессором Volta V100, что впечатляет. Масштаб чипа здесь был приведен к одному графическому процессору, чтобы обеспечить честное сравнение между Ampere и Volta.
Чип Huawei Ascend смог завершить только один тест вовремя, и это тоже с более низкой производительностью, чем Volta V100, в то время как TPU V3 от Google успел завершить только два теста вовремя. В одном тесте чип на 20% опережал NVIDIA Volta V100, а во втором тесте он был на 10% медленнее, чем V100.
По сравнению с 8-сокетной конфигурацией Cooper Lake-SP, которая завершает тест классификации изображений за 1104,53 минуты, двойная система NVIDIA A100 может пройти тот же тест всего за 33.37 мин. NVIDIA также продолжает сравнивать производительность своего Ampere A100 с неизданным Google TPU V4, который все еще находится на стадии исследования и по крайней мере через год от доступности.
NVIDIA также демонстрирует, как производительность их графических ускорителей со временем улучшилась благодаря последним инновациям полного стека для ИИ. По сравнению с MLPerf 0.5, работающим на Volta V100, пакет MLPerf 0.7, работающий с Ampere A100, обеспечивает поразительный прирост производительности в 4,2 раза.
Это сделано для того, чтобы показать, насколько впечатляющим является чип NVIDIA Ampere A100 GPU в реальных тестах в рамках пакета, признанного всеми основными игроками сообщества AI.Графический процессор Ampere A100 также считался самым быстрым графическим процессором, когда-либо зарегистрированным в другом тесте, даже по сравнению с графическим процессором Turing, который имел методы hw-ускорения, позволяющие обеспечить лучшую производительность, но все же не мог сравниться с Ampere A100 и его огромной производительностью. Все эти возможности тестирования делают нас еще более взволнованными, увидев Ampere в потребительской форме, что определенно должно произойти через несколько месяцев.
Gaming with Volta Cards — Взгляд в архитектуру
Хотя Titan V, единственная доступная карта Volta с добавлением Nvidia Quadro GV100 и Tesla V100, которая стоит целое состояние, может не быть игровой картой, она все же может быть Взгляд на то, что архитектура Volta приготовила для нас, в отличие от Pascal в играх.Дело не в том, чтобы смотреть на чистую производительность в сотне разных игр, а в том, чтобы подумать о том, чему нас учит общая производительность и что в конечном итоге может появиться с картами Volta.
Это взгляд на архитектуру Volta.
Volta, микроархитектура графического процессора, разработанная Nvidia, пришла на смену Pascal и была объявлена в качестве будущей дорожной карты в марте 2013 года. Но до сих пор мы не видели настоящих игровых карт GTX Volta.
Nvidia Quadro и Tesla V100 стоят очень дорого, но они обеспечивают впечатляющий прирост производительности по сравнению с Pascal даже в играх, для которых они не предназначены.
Должен иметь17 отзывов
Последнее обновление от 06.08.2021, 01:19 с использованием Amazon Product Advertising API
С одной стороны, сейчас не лучшее время для покупки одного из них, если вы геймер, но с другой стороны, они позволяют нам увидеть, чего мы можем ожидать в будущем. Titan V, последняя выпущенная карта из поколения видеокарт Volta, на самом деле стоит немного более разумно, около 2700 фунтов стерлингов, и обеспечивает значительный скачок производительности по сравнению с любой другой картой на рынке во всем, что на нее бросают. .Это нет. 1 карта на gpu.userbenchmark.com.
Также важно помнить, думая о Volta, что Nvidia не торопится, по крайней мере, с точки зрения маркетинга. По сути, они захватили рынок с помощью Pascal, чтобы им не приходилось торопиться с выпуском своих карт. AMD убедительно отвергла Nvidia даже с помощью Pascal, что бы AMD ни выпускала, даже карты серии VEGA.
Итак, давайте посмотрим, как примерно работает Titan V по сравнению с лучшей игровой видеокартой на сегодняшний день, 1080Ti, ее младшим братом Titan Xp, Nvidia Quadro и Vega FE — с точки зрения игр
Linus Tech TipsLinus Tech СоветыОн показывает на удивление лучше во всем, что в него бросают.Но нужно иметь в виду, что это не карта, разработанная специально для геймеров, как по цене, так и по производительности. Еще раз напомним, что Titan V — это , а не , предназначенный для игр. И хотя это в три раза дороже 1080Ti, я считаю это оправданным.
Это, несомненно, лучшая видеокарта, но следует отметить, что ее следует больше сравнивать с картами, предназначенными для той же цели, неигровыми, огромными рабочими нагрузками, передовыми вычислениями искусственного интеллекта и задачами глубокого обучения графического процессора, такими как Titan Xp, Nvidia Quadro, Vega FE и Tesla V100 в тестах им больше подходят.Но он по-прежнему превосходит любую карту с точки зрения игровой производительности.
Linus Tech TipsМы ясно видим, что Titan V по-прежнему продолжает доминировать над всеми другими высокопроизводительными картами, и это всего лишь понимание того, что Volta может принести нам в будущем. Ей даже удается легко превзойти своего прямого конкурента Volta во всех аспектах, легко претендуя на звание самой быстрой видеокарты на сегодняшний день. Теперь, честно говоря, поскольку мы уже упоминали, что Titan V — это , а не игровая карта, поэтому мы должны также взгляните на некоторые тесты в области глубокого обучения и искусственного интеллекта.
С добавлением новых ядер Tensor , наряду с классическими ядрами CUDA , на которых обычно работает каждый графический процессор, он должен легко превзойти графическую карту на базе CUDA core , поскольку она имеет 5120 ядер CUDA и с 640 тензорными ядрами, по сравнению только с 3840 ядер CUDA, для Titan Xp и 2560 для 1080Ti, без тензорных ядер.
Linus Tech TipsLinus Tech TipsTitan V — абсолютный победитель в COMPUBENCH благодаря добавлению тензорных ядер
Linus Tech TipsИ пока мы на этом, Nvidia также хвастается своей памятью HBM2 для впервые в карте серии Titan.
Но насколько большой на самом деле может быть Вольта? Увидев эти необработанные цифры, Volta демонстрирует свои превосходные возможности как в играх, так и в обучении с глубоким ИИ, для чего он в первую очередь предназначен. Но на самом деле дело в том, когда выйдет серия видеокарт Volta Gen серии Geforce GTX, и все, что мы можем сделать на данный момент, — это предположить, насколько большой скачок производительности мы можем увидеть. Если вам нравятся игры с разрешением 4K, обычно это негабаритные мониторы с максимально возможным FPS, Titan V может быть для вас, и это единственное, что мы получили от Volta до сих пор.
NVidia Volta: всесторонний обзор для обычных геймеров
AMD и NVidia доказывают, что конкуренция может стать катализатором инноваций. В то время как AMD предлагает одни из самых недорогих потребительских графических процессоров, NVidia, кажется, преуспела в разработке микроархитектуры, подходящей для рабочих станций и суперкомпьютеров.
Одним из таких примеров доблести NVidia является ее архитектура Volta, которая присутствует как в суперкомпьютере Sierra Ливерморской национальной лаборатории, так и в компьютере IBM Summit.Для многих энтузиастов линейка Volta от NVidia оставалась незамеченной.
Похоже, что многие пользователи даже не знают, что он был выпущен более двух лет назад. В этом руководстве мы рассмотрим историю Volta, рассмотрим ее использование, обсудим будущие разработки и многое другое.
Что такое NVidia Volta?
Мы обнаружили, что средний геймер не очень разбирается в тонкостях архитектуры GPU. В то время как продвинутые компьютерные геймеры и любители, как правило, чрезмерно педантичны в отношении каждой части, которая входит в их ПК.В большинстве случаев достаточно, чтобы выиграть состязание, объявив, что у вас новейшая и лучшая видеокарта для игр и насколько вы ее разогнали.
Все остальное лишнее. Однако есть геймеры, которые искренне интересуются микроархитектурой графического процессора и ее влиянием на производительность и возможности. Мы подозреваем, что вы явно один из таких игроков.
Так что же такое Volta от NVidia и что отличает его от своих предшественников? Если вы используете карту на основе Паскаля или Максвелла, стоит ли обменивать ее на карту Вольта? Ответ на этот вопрос может вас удивить.Во-первых, давайте пройдемся по истории Вольты.
История NVidia Volta
19 марта 2013 года, во время ежегодной конференции Nvidia по технологиям графических процессоров (GTC), генеральный директор компании Джен-Хсун Хуанг выступил с одним из самых важных основных докладов десятилетия (с точки зрения технологии графических процессоров).
Для тех из вас, кто не знаком с GTC, это глобальная конференция, охватывающая некоторые из наиболее важных тем, касающихся не только NVidia, но и всех сфер вычислений и технологий.На конференции 2020 года будут обсуждаться темы ИИ, Интернета вещей, глубокого обучения, моделирования и т. Д.
Конференция состоится 26 марта в конференц-центре San Jose McEnery. Вы можете узнать больше об этом на странице GTC NVidia.
[вставить] https://www.youtube.com/watch?v=5TUk5BtM0Bc[/embedyt]
Тем не менее, основной доклад Жэнь-Сюнь Хуанга был особенно важен, потому что он подробно рассказал о планах NVidia на будущее. Он изложил дорожную карту, иллюстрирующую планы NVidia на следующие пять лет.
Первым откровением стал преемник Кеплера по прозвищу Максвелл. Можно вспомнить Максвелла за создание видеокарт, таких как GeForce GTX 750 Ti и GTX Titan X. Удивительно, но геймеры все еще используют карты с микроархитектурой Maxwell.
Из основного выступления было понятно, что Вольта будет тем, кто заменит Максвелла. Ретроспективно теперь мы видим, что это было неверно, поскольку графические процессоры на основе архитектуры Pascal появились примерно два года спустя.
Мы не жалуемся, потому что Pascal сделал возможными такие великолепные видеокарты, как GTX 1050 Ti, GTX 1070 и GTX 1080 Ti.
В среднем NVidia выпускает новую микроархитектуру каждые два года. Как ни странно, архитектура Volta была выпущена через год после выпуска Паскаля. Для этого есть веская причина, и мы объясним это далее в этом руководстве.
Volta Дата выпуска
Во время выступления на презентации GTC от NVidia 2017 года компания Volta официально анонсировала Tesla V100. Если вы никогда не слышали о линейке продуктов NVidia Tesla, возможно, вы не являетесь целевой аудиторией (если вы не специалист по данным / вычислительной физике или любой другой ученый, работающий с большими наборами данных).
Логично, что архитектура была названа в честь Алессандро Вольта, итальянского химика и физика 18-19 веков, известного своим изобретением электрического элемента и открытием метана. Это было продолжением традиции NVidia, которая называла свои микроархитектуры именами известных ученых.
[embedyt] https://www.youtube.com/watch?v=fM4JTm9E5os[/embedyt]
СерияTesla от NVidia, конечно же, была названа в честь всеобщего любимого изобретателя-затворника Николы Тесла.Tesla V100 был создан не для игр, а скорее для обработки потоковых данных, вычислений, геопространственного интеллекта, моделирования сложных вычислений и создания визуальных объектов и изображений для различных профессий.
Tesla V100 станет первой видеокартой, которая обнажит архитектуру Volta 1 июня 2017 года. Позже в том же году, 7 декабря, была выпущена NVidia Titan V. В отличие от Tesla V100, NVidia Titan V обладает всеми возможностями графической обработки.
Другими словами, вы можете использовать его для игр (если вы очень богаты).Ни одну из видеокарт NVidia Volta нельзя считать доступной по цене. На момент выпуска NVidia Titan V считалась самой мощной видеокартой. При запуске он был оценен в 2999 долларов.
Характеристики Volta
Volta была введением NVidia в ядра Tensor, которые, как известно, обеспечивают превосходные возможности глубокого обучения, чем обычные ядра CUDA.
Тем не менее, архитектура Volta по-прежнему поддерживает CUDA Compute Capability 7.0. Ядра CUDA необходимы для вычислений общего назначения на графическом процессоре, поскольку они позволяют выполнять параллельные вычисления.
Архитектура изготовлена по 12-нм техпроцессу TSMC FinFET, который позволяет использовать 21,1 миллиарда транзисторов. NVidia всегда была свидетельством закона Мура.
[вставить] https://www.youtube.com/watch?v=vzsryZ0-4VI[/embedyt]
Он оснащен памятью с высокой пропускной способностью второго поколения, HBM2. Это обеспечивает пропускную способность памяти до 8 ГБ (пространство) и 256 ГБ / с (скорость) на пакет. В то время это было очень впечатляюще, пока несколько лет спустя не вышел HBM2E.
Volta также поставляется с PureVideo от NVidia, который поддерживает аппаратное декодирование различных стандартов видеокода.В дополнение к этому Volta использует NVLink 2.0, который обеспечивает превосходную производительность и скорость по сравнению с PCIe. К сожалению, эта функция отключена на NVidia Titan V.
.NVidia стремилась к созданию Volta, чтобы создать микрочипы, которые разожгли бы огонь искусственного интеллекта и продвинули его вперед. Чтобы сделать это возможным, чипы Volta поставляются с 640 тензорными ядрами, которые обеспечивают скорость более 125 TFLOPS в секунду.
Конечно, вы также можете выбрать оптимизированное для Volta программное обеспечение и комплекты.Как API CUDA и библиотеки SDK для глубокого обучения NVidia.
Видеокарты и продукты Volta
В этом разделе мы рассмотрим некоторые из лучших технологий и продуктов, использующих микроархитектуру Volta. Если вы заинтересованы в покупке видеокарты, в этом разделе вы узнаете, что вам доступно. Кроме того, это также должно помочь вам понять возможности и приложения микроархитектуры Volta.
NVidia V100 PCie
- Дата выпуска: 21 сентября 2017 г.
- Цена: 5923–11 458 долларов
- Тензорные ядра NVidia: 640
- Ядра NVidia CUDA : 5120
- Память графического процессора : 16 ГБ / 32 ГБ HBM2
- Базовая частота : 1246 МГц
- Тактовая частота с ускорением: 1380 МГц
- Размер слота: Двойной слот
- Производительность одинарной точности: 14 терафлопс
- Производительность тензор: 112 терафлопс
- Макс.потребляемая мощность: 250 Вт
- Лучшая реализация: PNY Nvidia Tesla v100 16GB
Как мы уже упоминали, NVidia V100 была первой видеокартой, отображающей архитектуру NVidia Volta.Он использует графический процессор GV100. По сей день он по-прежнему обеспечивает одну из лучших вычислительных характеристик. Согласно тестам NVidia, он в 32 раза быстрее, чем средний процессор.
Он поддерживает почти все фреймворки глубокого обучения. От Caffe2 до Pytorch и MXNet. На момент выпуска средняя цена на эту модель составляла 10 644 доллара за версию на 16 ГБ и 11 458 долларов за версию на 32 ГБ. Сегодня вы можете получить версию на 16 ГБ от PNY менее чем за 6000 долларов. HP также продает свою версию за 5 999 долларов (на момент написания этой статьи).В качестве альтернативы вы можете получить версию эталонной карты Tesla V100 на 32 ГБ за 8 509 долларов. NVidia также продает референсную карту на 16 ГБ за 5 995 долларов.
NVidia V100 SXM2
- Дата выпуска: 27 марта 2018
- Цена: 10 664 — 27 500 долларов США
- Тензорные ядра NVidia: 640
- Ядра NVidia CUDA : 5120
- Память графического процессора : 32 ГБ HBM2
- Базовые часы : нет
- Тактовая частота с ускорением: 1601 МГц
- Размер слота: Двойной слот
- Производительность одинарной точности: 16.4 терафлопса
- Производительность тензор: 130 терафлопс
- Макс.потребляемая мощность: 250 Вт
- Лучшая реализация: Н / Д
Спустя шесть месяцев после выпуска NVidia V100 PCIe, NVidia выпустила NVidia SXM2. Поскольку он использует NVIDIA NVLink, он имеет значительно большую пропускную способность межсоединения. Почти в десять раз больше. V100 PCle обеспечивает пропускную способность межсоединения 32 ГБ / с, а V100 SXM2 — колоссальные 300 ГБ / с.
Он также обеспечивает немного лучшую точность и тактовую частоту. Как и ожидалось, он поддерживает вычислительные API, такие как CUD, DirectCompute, OpenCL и OpenACC.
Минус в том, что он намного дороже, чем V100 PCIe, и в большинстве случаев вы сможете получить его только по специальному заказу для сборки системы. Удачи в попытках найти его на Amazon или в любом другом розничном магазине электроники.
NVidia SXM2 также использует пассивное охлаждение и требует необычного блока питания для работы.Ваш блок питания должен иметь не менее 650 единиц мощности для питания V100 SXM2.
NVidia V100S PCIe
- Дата выпуска: 26 ноября 2019
- Цена: 12 000–14 000 долларов
- Тензорные ядра NVidia: 640
- Ядра NVidia CUDA : 5120
- Память графического процессора : 32 ГБ HBM2
- Базовая частота : 1290 МГц
- Тактовая частота с ускорением: 1530 МГц
- Размер слота: Двойной слот
- Производительность одинарной точности: 15.7 терафлопс
- Производительность тензор: 125 терафлопс
- Макс.потребляемая мощность: 300 Вт
- Лучшая реализация: Н / Д
В марте 2019 года NVidia объявила о приобретении израильско-американской сетевой компании для центров обработки данных Mellanox. Эта сделка докажет, что NVidia серьезно относится к переходу на другие технологии, которые еще больше продвинут их стремления в области Интернета вещей, искусственного интеллекта и универсальных графических процессоров.
ВыпускNVidia в сентябре 2018 года Tesla T4 (на основе микроархитектуры Тьюринга) не был признаком того, что они были сделаны с Volta.Спустя год они выпустят NVidia V100S.
Что касается TFLOPS с двойной точностью, это улучшит производительность по сравнению с исходным Tesla V100 PCIe на 17% и SXM2 на 5%. Производительность одинарной точности также увеличилась на 17% по сравнению с PCIe и на 4% для SXM2.
Пока что NVidia выпустила только версию видеокарты на 32 ГБ. Однако они увеличили пропускную способность памяти до 1134 ГБ / с. Это на 26% больше, чем у обоих предшественников. Снаружи NVidia V100 по-прежнему имеет тот же дизайн и цветовую палитру, что и оригинальный Test V100.
Сходство есть и в количестве потребляемой мощности. Обе карты имеют максимальную потребляемую мощность 250 Вт. Это означает, что NVidia нашла способ повысить производительность при оптимизации энергопотребления.
Nvidia Titan V
- Дата выпуска: 7 декабря 2017
- Цена: 2999–3900 долларов
- Тензорные ядра NVidia: 640
- Ядра NVidia CUDA : 5120
- Память графического процессора : 12 ГБ HBM2
- Базовая частота : 1290 МГц
- Тактовая частота с ускорением: 1455 МГц
- Размер слота: Двойной слот
- Производительность одинарной точности: 13.8 терафлопс
- Производительность тензор: 110 терафлопс
- Макс.потребляемая мощность: 250 Вт
- Лучшая реализация: NVIDIA TITAN V VOLTA 12 ГБ HBM2 ВИДЕОКАРТА
Поскольку серия Tesla Volta V100 была создана для вычислений общего назначения, графические карты этой серии не имеют выходов на мониторы. Что, если бы мы могли взять массивный чип Tesla V100 и вставить его в видеокарту, которая действительно предназначена для игр?
NVidia Titan V отвечает на этот вопрос.Почти год она оставалась самой мощной потребительской видеокартой в мире (и самой дорогой), пока RTX 2080 Ti не свергнул ее за половину цены.
Однако NVidia Titan V по-прежнему более оптимизирована для глубокого обучения и искусственного интеллекта. У него больше ядер CUDA и почти вдвое больше тензорных ядер. В конечном итоге это означает, что Titan V подходит как для рабочих станций, так и для игровых устройств высокого класса.
Его внешняя оболочка похожа по дизайну на V100 PCIe и SXM2, но с большим количеством золота.Вот почему NVidia Titan V превосходит свой статус обычной видеокарты. Как яркая золотая цепочка или пара слишком дорогих дизайнерских джинсов, это символ статуса.
Nvidia Titan V CEO Edition
- Дата выпуска: 21 июня 2018
- Цена: НЕТ
- Тензорные ядра NVidia: 640
- Ядра NVidia CUDA : 5120
- Память графического процессора : 32 ГБ HBM2
- Базовая частота : 1200 МГц
- Тактовая частота с ускорением: 1455 МГц
- Размер слота: Двойной слот
- Производительность одинарной точности: 14.8 терафлопс
- Производительность тензор: 125,33 терафлопс
- Макс.потребляемая мощность: 250 Вт
- Лучшая реализация: Н / Д
Несмотря на то, что NVidia Titan V CEO Edition была выпущена ограниченным тиражом, мы все же сочли необходимым включить ее сюда. Карту получили около 20 руководителей. Обычным пользователям также была предоставлена возможность выиграть карты из различных изданий.
Самым примечательным атрибутом Titan V CEO Edition по сравнению с оригиналом было увеличение объема памяти.Первый Titan V имел 12 ГБ памяти. Версия CEO Edition увеличила это количество более чем вдвое. Он имел колоссальные 32 ГБ встроенной памяти.
CEO Edition также превосходит RTX 2080 Ti в большинстве тестов. Тем не менее, RTX 2080 Ti по-прежнему больше подходит для игр из-за его возможностей трассировки лучей, а также поддержки драйверов для более широкого спектра игр.
Если вы думали, что оригинальный Titan V был символом статуса, представьте, какую зависть вы вызовете у других игроков, когда они узнают, что у вас есть этот монстр в вашем снаряжении.
Nvidia Quadro GV100
- Дата выпуска: 27 марта 2018
- Цена: 8 549–8 999 долларов
- Тензорные ядра NVidia: 640
- Ядра NVidia CUDA : 5120
- Память графического процессора : 32 ГБ HBM2
- Базовая частота : 1132 МГц
- Тактовая частота с ускорением: 1628 МГц
- Размер слота: Двойной слот
- Производительность одинарной точности: 16.66 терафлопс
- Производительность тензор: 119,5 терафлопс
- Макс.потребляемая мощность: 250 Вт
- Лучшая реализация: NVIDIA Quadro GV100 Volta GPU 32GB Видеокарта
NVidia любит превзойти самих себя. Если вы были впечатлены серией Titan V или V100 и впервые читаете о Quadro GV100 от NVidia, то ваша челюсть вот-вот упадет.
Подобно серии Tesla, серия Quadro предназначена для рабочих станций, профессиональных настроек и универсальных вычислений.Однако, в отличие от серии Tesla V100, Quadro GV100 имеет четыре порта дисплея.
Quadro V100 в настоящее время является лучшей реализацией микросхемы GV100 и микроархитектуры Volta. Хотя он не предназначен для игр, вы можете получить максимальное разрешение 4096 × 2160 на 4 экранах с частотой 120 Гц, 5120 × 2880 на 4 экранах с частотой 60 Гц и 7680 × 4320 на 2 экранах с частотой 60 Гц.
Как и следовало ожидать, Quadro GV100 также поддерживает VR. Он поддерживает новейшие графические API Vulkan, OpenGL, Shader Model и Direct X.В отличие от V100 SXM2, Quadro GV100 использует активное охлаждение.
Что касается ИИ, вычислений и глубокого обучения, Quadro поддерживает CUDA, DirectCompute и OpenCL. Вы получите ускорение примерно на 133,325 терафлопсей для глубокого обучения. Quadro немного дороже, чем элитная версия V100 PCIe.
На момент выпуска Quadro GV100 стоила 8 999 долларов. Это в три раза дороже, чем Titan V. Сегодня вы можете приобрести его по несколько более низкой цене. Если вы средний потребитель, у которого есть много лишних денег, вы можете приобрести две видеокарты NVIDIA Quadro GV100 и использовать их в тандеме с NVIDIA NVLink.
Просто помните, что вам понадобится набор действительно хороших мониторов и мощный процессор, чтобы максимально использовать возможности GV100.
Заключительные слова
Микроархитектура Volta уже давно отсутствует. Даже с текущими микроархитектурами, такими как Pascal и Turing (а также на горизонте Ampere и Hopper), NVidia не похоже, что она перестанет пытаться получить максимум от своих видеокарт Volta.
Мы прогнозируем, что в будущем появится как минимум еще одна видеокарта на базе GV100 по смехотворной цене.NVidia только что объединила себя с глубоким обучением и технологиями центров обработки данных (условно говоря). В ближайшее время они не перестанут производить и выходить на этот рынок.
В этой статье мы подробно рассказали о микроархитектуре Volta и ее продуктах. К концу этой статьи вы станете экспертом во всем, что касается Volta. Если нет, значит, мы вас подвели. В любом случае, мы надеемся, что вам понравилось читать эту статью. Спасибо за чтение.
Глубокое погружение в архитектуру графического процессора Nvidia Ampere
Когда у вас 54.2 миллиарда транзисторов, с которыми можно поиграть, вы можете упаковать множество различных функций в вычислительное устройство, и это именно то, что Nvidia сделала с энергией и энтузиазмом с новым графическим процессором Ampere GA100, предназначенным для ускорения в центре обработки данных. Мы рассказали о первом анонсе графического процессора GA100 и его реализации ускорителя Tesla A100 две недели назад, а теперь мы собираемся углубиться в архитектуру, а затем, конечно же, провести тщательный анализ соотношения цена / производительность устройства A100 в сравнении. своим предшественникам в линейке Tesla.
Когда мы писали нашу оригинальную историю о графическом процессоре GA100 и ускорителе A100 две недели назад, каналы и скорости устройств не были полностью исчерпаны, и после этого объявления у нас было несколько сеансов с Nvidia, включая сеанс вопросов и ответов с Яном. Бак, вице-президент и генеральный менеджер подразделения центров обработки данных Tesla, и сеанс глубокого погружения с Йоной Албеном, старшим вице-президентом компании по разработке графических процессоров. Многие подробности о GA100 и его карте-ускорителе содержатся в техническом документе по архитектуре Ampere, который мы дополняем материалами из этих сессий и нашим собственным анализом.
Как и в случае с предыдущими графическими процессорами, предназначенными для центров обработки данных, восходящими к чипам Fermi десять лет назад, которые были первыми в истинной линейке Tesla, в Ampere существует иерархия вычислительных механизмов, кэширования и логики координации. дизайн. Базовая организационная единица — это потоковый мультипроцессор, или SM, который имеет ряд различных вычислительных механизмов, которые сидят бок о бок, ожидая, пока работа будет передана им параллельно. Этот SM — это то, что эксперты HPC рассматривают как эквивалент ядра в области ЦП, например, при подсчете количества «ядер» суперкомпьютеров в рейтинге Top 500, который выходит дважды в год.Любая совокупность вещей, лежащих в основе кэшей инструкций и данных L1, является «ядром» этого образа мышления, и то, что Nvidia называет ядрами, мы можем в CPU Land называть «единицей». (Люди из Nvidia тоже иногда называют это устройством.)
Раньше элементы внутри SM назывались по-разному потоковыми процессорами, или SP, или ядрами CUDA, но теперь у этих SP есть много разных вычислительных элементов внутри них с разными форматами данных и типами обработки, а не только 32-битными. ядра одинарной точности CUDA.Надев свою архитектурную шляпу, мы думаем, что можно привести убедительный аргумент в пользу того, что каждый из SP в SM следует рассматривать как «ядро», как мы его знаем, а не SM, как это делают другие, и очень грубо и в некоторой степени аналогично. к ядру в CPU Land. Мы понимаем, что это более тонкий момент. В конечном итоге мы заботимся о мощности на устройство, стоимости мощности и стоимости мощности на ватт.
Сторона: если вы хотите взглянуть на историю архитектуры GPU в устройствах Tesla, начиная с чипа «G80», который положил начало революции вычислений GPU общего назначения, мы сделали большой обзор этого еще в феврале 2018 года, когда мы погрузились в GPU Volta после разговора с архитекторами Nvidia.
Без лишних слов, вот как выглядят Ampere SM и его четыре SP:
Каждый SP имеет шестнадцать 32-битных целочисленных единиц (INT32), шестнадцать 32-битных единиц с плавающей запятой (FP32) и восемь 64-битных (FP64) единиц. Это очень похоже на Volta SM. Как сумасшедший, похожий, как вы можете видеть здесь:
Мы никогда не знали размер кэшей уровня 0 на Volta, как и размер графического процессора Ampere. Но каналы и скорости в планировщике деформации, модуле диспетчеризации и файлах регистров на процессорах Ampere выглядят так же, как и на чипах Volta.Размеры кэша инструкций L1 для двух устройств точно так же не раскрываются, но мы знаем, что кэш данных L1 в SM составлял 128 КБ для Volta, а теперь на 50 процентов больше, на 192 КБ для Ampere. Блоки загрузки / сохранения и текстурные блоки практически одинаковы.
На высоком уровне Ampere очень похож на Volta, но есть много настроек во всех этих элементах Ampere SP и SM, которые делают их разными в деталях, например, объединение пары тензорных ядер. единиц в SP, чтобы они могли выполнять 64-битные математические вычисления с очень высокой скоростью.Как мы уже говорили, существует множество инноваций с форматами данных и ускорением разреженной матрицы, которые обеспечивают высокую производительность при рабочих нагрузках ИИ, эквивалентную удвоению единиц FP или единиц тензорного ядра — чтобы сделать это в рамках того, о чем предположительно идет речь. такой же бюджетный транзистор. Так что не думайте, что мы не впечатлены. Мы.
Это разреженное матричное ускорение, например, является особенно изящным трюком, как показано ниже:
После обучения модели машинного обучения на графических процессорах, модель выводит набор плотных весов.Nvidia создала метод автоматической обрезки, который снижает плотность матрицы вдвое, используя ненулевой шаблон 2: 4, который не приводит к снижению эффективности весов для вывода, и путем пропуска введенных нулей, модуль Tensor Core может выполнять вычисления с плавающей запятой или целыми числами вдвое больше, чем это было бы с более плотной матрицей. Мы не уверены, что происходит с матрицами, которые уже являются разреженными, что происходит с некоторыми рабочими нагрузками AI и HPC. Но, предположительно, если бы они использовали данные в правильных форматах, эти рабочие нагрузки также могли бы получить двукратное ускорение разреженной матрицы.
Чип Volta имел в общей сложности 84 SM, 80 из которых были открытыми, а четыре — неисправными, что помогло Nvidia повысить выход чипа из 12-нанометровых процессов от партнера по производству Taiwan Semiconductor Manufacturing Corp, которые были абсолютно передовыми три года назад . С переходом на 7-нанометровые процессы в TSMC микросхема Ampere может иметь намного больше SM на кристалле, а на самом деле их 128. Это 52,4% -ное увеличение SM, и это большая часть улучшения производительности при переходе от Volta к Ampere.Производственные устройства Volta и Ampere имели 80 SM и 108 SM соответственно, так что сначала это больше похоже на базовое 35-процентное увеличение производительности только за счет увеличения количества вычислительных блоков на устройстве.
Вот как выглядит полностью загруженный Ampere GA100 со всеми своими 128 SM:
Иерархия вычислений в графическом процессоре Ampere выглядит следующим образом. Два SM вместе составляют кластер текстурного процессора или TPC. Восемь из этих TPC (и, следовательно, шестнадцать SM) составляют блок более высокого уровня, называемый кластером обработки графического процессора, а восемь из них составляют полный графический процессор.Это число имеет большое значение, поскольку имеется восемь срезов Multi-Instance GPU, или MIG, которые можно независимо использовать в качестве виртуальных механизмов вывода и виртуальных графических процессоров для инфраструктуры настольных компьютеров. У графического процессора Volta GV100 было шесть GPC, которые теоретически могли быть их собственными MIG, но Nvidia не выделяла отдельные пути между кешами и контроллерами памяти непосредственно для каждого GPC в GV100, как это делается с GA100. Это то, чем на самом деле является MIG — более изолированный и независимый GPC — и это тонкое изменение, которое, тем не менее, является важным, поскольку оно устраняет некоторые конфликты за объем памяти и пропускную способность, когда устройство вместо этого работает как восемь меньших устройств. одного большого толстого гудящего.Это может быть незначительное изменение, но оно важное.
С полным набором модулей SM, микросхема Ampere имеет 8 192 модулей FP32 и INT32, 4096 модулей FP64 и 512 модулей Tensor Core. Это чертовски плотное устройство. При активированном только 108 SM, 6912 единиц FP32 и INT32, 3456 единиц FP64 и 432 модуля Tensor Core, которые могут выполнять рабочие нагрузки.
Есть несколько важных изменений с прыжком Ампера от Вольты. Начиная с внешней стороны, основным интерфейсом является PCI-Express 4.0, который имеет вдвое большую пропускную способность интерфейса PCI-Express 3.0, используемого с Volta, при дуплексном режиме 128 ГБ / с (64 ГБ / с в каждую сторону на слоте x16 с шестнадцатью полосами, как следует из названия).
Это не единственный способ установить и отключить Ampere GPU. Также есть порты NVLink. С графическими процессорами Pascal PA100 NVLink 1.0 работал со скоростью 20 Гбит / с, и каждый из четырех портов на устройствах обеспечивал пропускную способность 40 ГБ / с (20 ГБ / с в каждом направлении). С чипами Volta Nvidia увеличила количество сигналов до 25.8 Гб / сек для NVLink 2.0, что после кодирования обеспечило пропускную способность 25 Гб / сек на каждую пару сигналов, всего 50 Гб / сек в каждую сторону и через шесть портов, что дало вам в совокупности 300 Гбайт / сек пропускной способности в и из микросхемы Volta GV100. Мы думаем, что с Ampere Nvidia добавляет PAM-4, который добавляет два бита на сигнал и при 25 ГГц дает каждой полосе NVLink 3.0 такую же двунаправленную полосу пропускания 25 ГБ / с, что и NVLink 2.0, но для этого требуется только половина количества сигналов. пар, как NVLink 2.0, чтобы обеспечить такую же пропускную способность 50 ГБ / с на порт.Итак, теперь у чипа Ampere может быть дюжина портов NVLink, которые по-прежнему соответствуют пропускной способности агрегирования портов NVSwitch в 300 ГБ / сек, что означает, что есть еще несколько интересных топологических вещей, которые можно сделать для соединения графических процессоров. (Мы рассмотрим их отдельно в следующем рассказе.)
На передней панели основной памяти имеется дюжина контроллеров памяти HBM2, которые подаются на шесть банков стековой памяти HBM2 на микросхеме GA100. Один десяток контроллеров и пять из этих банков задействованы, что дает ускорителю Tesla A100 емкость 40 ГБ и совокупную пропускную способность памяти 1555 ГБ / с при частоте памяти 1215 МГц.Чип Volta, выпущенный с памятью HBM2, работающей на частоте 877,5 МГц, изначально имел только 16 ГБ емкости и 900 ГБ / с пропускной способности. Объем памяти был увеличен вдвое примерно через год, но пропускная способность осталась прежней, и в ноябре прошлого года на конференции по суперкомпьютерам SC19 в ноябре прошлого года Nvidia очень тихо представила Tesla V100S только с версией PCI-Express 3.0 и частотой 1106 МГц. Память HBM2, которая увеличила пропускную способность памяти на микросхеме Volta до 1134 ГБ / сек. Чтобы достичь достигнутой производительности, V100S мог бы достичь этого, запустив оставшиеся четыре SM для полного набора 84 SM, что повысило производительность по всем направлениям на 4.7 процентов. Но, как оказалось, у него 80 SM, работающих на 1601 МГц, что на 4,6 процента больше. Этот чип мог быть полезен в начале 2019 года, и ясно, что какой-то центр гипермасштабирования или HPC нуждался в временном промежутке и получил его. Tesla A100 наступит на это довольно тяжело.
Если вы сравните блок-схемы GV100 и GA100, вы увидите, что кэш L2 на микросхеме Ampere разбит на два сегмента, а не на один кэш L2 в основе микросхемы Volta. Кэш L2 был увеличен до 40 МБ, что в 6 раз больше.7-кратное увеличение по сравнению с микросхемой Volta. Это большое изменение, и мы думаем, что в сочетании с новой секционированной перекрестной структурой, которая имеет в 2,3 раза большую пропускную способность чтения кэша L2 по сравнению с кешем L2 на микросхеме Volta, это является доминирующим фактором в необработанных улучшениях производительности, которые Ampere будет демонстрировать по сравнению с Чип Volta показывает чистую производительность на аналогичных модулях FP32, FP64 и INT8 — без разреженного ускорения или новых, более эффективных числовых форматов в различных модулях на кристалле. И, более точно, мы говорим, что мы думаем, что реальные приложения покажут большее улучшение, чем выражено в пиках на рисунках для этих базовых модулей, а затем получат еще большую производительность, поскольку они используют другие числовые форматы и перемещают работу из Модули FP32 или FP64 для тензорных ядер и еще больше ускоряются.
Для реальных рабочих нагрузок мы должны предположить, что архитекторы графических процессоров Nvidia посчитали, что у них недостаточно кэша L1 и L2, чтобы скрыть задержки в чипе GV100, и они смогут выжать больше присущей производительности устройств в конструкции Volta. путем настройки иерархии памяти и расширения ее для Ampere. Мы думаем, что независимый путь, использованный для создания MIG-срезов для логического вывода и виртуальных графических процессоров для виртуальных рабочих столов, также был благом, создав гораздо более сбалансированный движок для обучения ИИ и высокопроизводительных вычислений.Есть много других функций, которые увеличивают производительность, например, асинхронное копирование, которое загружает данные из глобальной памяти HBM2 в кэш-память SM L1 без необходимости просматривать файлы регистров.
Время и результаты покажут. Это просто внутреннее ощущение, которое у нас есть.
Еще одно замечание. Тактовые частоты микросхем Ampere на самом деле ниже, чем у микросхем Volta, даже при значительном сокращении процесса с 12 до 7 нанометров. У нас нет базовой тактовой частоты, но мы знаем, что тактовая частота GPU Boost на GV100 была равна 1.53 ГГц, когда он был объявлен три года назад, и 1,41 ГГц с GA100 сегодня. Таким образом, увеличение пропускной способности базового графического процессора за счет этих дополнительных 28 небольших SM требует 7,8% тактовой частоты. Это не удивительно. Повышение тактовой частоты влечет за собой слишком большие затраты на электроэнергию, а добавление большего количества параллелизма — лучшее использование этой мощности во всех типах устройств, включая процессоры и FPGA.
Даже с учетом тактовой частоты GA100, ускоритель V100 весил 300 Вт, а A100 — 400 Вт, то есть 33.Увеличение на 3 процента. Частично это связано с памятью HBM2 на устройстве, но мы думаем, что сам чип GA100 немного горячее, чем чип GV100, но это трудно доказать.
Вот как GA100 сочетается с графическими процессорами Pascal, Volta и Turing, используемыми в ускорителях Tesla, с точки зрения функций и производительности в расширяющемся массиве (каламбур) числовых форматов, которые поддерживает Nvidia для увеличения пропускной способности рабочих нагрузок AI. количество графических процессоров:
У нас есть таблица большего размера, которая включает сравнения с ускорителями Tesla поколений Kepler и Maxwell, но эта таблица слишком велика для отображения.(Вы можете просмотреть это здесь в отдельном окне.) FP16 с форматами FP16 или FP32 накопления, bfloat16 (BF16) и Tensor Float32 (TF32), используемые в новых модулях Tensor Core, демонстрируют производительность без поддержки разреженной матрицы и 2X улучшение с включенным. Поддержка разреженных матриц также ускоряет обработку вывода INT4 и INT8 на тензорных ядрах в 2 раза, когда она активирована. Он недоступен для обработки FP64 на тензорных ядрах, но реализация 64-битной математической математики тензорным ядром может обеспечить в 2 раза большую пропускную способность для математических вычислений FP64 по сравнению с модулями FP64 на GA100 и 2.В 5 раз больше, чем у GV100, у которого были только простые блоки FP64. (Мы уже сравнивали и сравнивали форматы BF16 и TF32 с другими здесь.)
Базовая производительность базовых блоков FP64 является иллюстративной при сравнении микросхемы GA100 с микросхемой GV100. Он увеличился всего на 25 процентов, с 7,8 терафлопс до 9,7 терафлопс, и это примерно правильное соотношение, учитывая 35-процентное расширение подсчета SM и снижение тактовой частоты на 7,8 процента. Это на 24,4% разницы в необработанных тактовых частотах для всех SP на каждом устройстве.(То, что мы называем Raw Oomph, когда говорим о процессорах.) Но если вы хотите увеличить производительность вдвое, вы можете запустить математические вычисления матрицы FP64 через более толстый модуль тензорного ядра на каждом SP, и теперь вы получаете 19,5 терафлопс на графическом процессоре GA100. со 108 ее SM и 432 тензорными ядрами. Прирост производительности дался нелегко.
«Это может быть неочевидно из документации, но является ли это нетривиальным упражнением, чтобы получить еще 2X производительности SM с тензорными ядрами», — говорит Албен The Next Platform .«Мы продвинули это так далеко, как мы думали, что мы можем в Вольте, чтобы эта вещь не загорелась, но с большим трудом мы выяснили, как получить еще 2X из системы, и мы смогли сделать это и получить даже лучшее использование, чем у поколения Volta. Мы определенно гордимся результатами ».
Между прочим, вот чего стоит ожидать: эти дополнительные 20 процентов пропускной способности памяти и объема памяти будут разблокированы, а также оставшиеся 18,5 процента скрытой производительности, воплощенные в 20 темных модулях SM для увеличения производительности. на фишках.Это больший блок скрытой емкости в устройстве Ampere, чем в устройстве Volta.
Далее мы собираемся провести тщательный анализ соотношения цена / производительность и производительность на ватт графических ускорителей семейства Tesla, от Kepler до Ampere. Именно здесь начинается самое интересное, потому что нельзя говорить о технологиях, не говоря о деньгах.
NVIDIA поднимает планку производительности с помощью графического процессора Volta
Автор: Майкл Фельдман
На волне ажиотажа в области искусственного интеллекта NVIDIA выпустила графический процессор Volta.Обновленная архитектура устанавливает новый стандарт производительности вычислений в высокопроизводительных вычислениях, глубоком обучении и ускоренных базах данных. Новую платформу представил генеральный директор NVIDIA Дженсен Хуанг на конференции GPU Technology Conference (GTC) в среду утром.
Источник: NVIDIA
Первым продуктом Volta будет Tesla V100, высокопроизводительный ускоритель NVIDIA, предназначенный для работы в центрах обработки данных. Он состоит из 21,1 миллиарда транзисторов и построен с использованием 12-нм технологии FinFET TSMC.Топовый чип мощностью 300 Вт обеспечивает производительность 7,5 терафлопс с плавающей запятой двойной точности (FP64) и 15 терафлопс при однократной прецессии (FP32). Это на 50 процентов выше производительности по сравнению с существующим графическим процессором P100 Tesla. V100 также обеспечивает 120 терафлопс производительности «глубокого обучения» благодаря 640 тензорным ядрам, разработанным специально для ускорения обработки нейронных сетей. Подробнее об этой функции позже.
NVLink, настраиваемое межпроцессорное соединение NVIDIA, было модернизировано до 300 ГБ / с, что почти вдвое превышает скорость передачи данных 160 ГБ / с по сравнению с исходным NVLink, установленным в графическом процессоре P100 Tesla.Это достигается за счет увеличения количества ссылок с четырех до шести и повышения скорости передачи данных на ссылку до 25 ГБ / с. Новое межсоединение будет особенно ценным для будущих клиентов IBM, поскольку обновленный NVLink будет поддерживать управление процессором и согласованность кеш-памяти — возможности, которые будут использоваться новым процессором IBM Power 9.
Возможно, наименее впечатляющим компонентом V100 является его 3D-память, модуль памяти с высокой пропускной способностью (HBM2), интегрированный в корпус. Благодаря использованию новейших компонентов, поставляемых Samsung, пропускная способность модуля HBM2 на 16 ГБ улучшилась незначительно — с 732 ГБ / с на P100 до 900 ГБ / с на V100.Однако NVIDIA включила в Volta новый контроллер памяти, который, по их словам, увеличивает полезную пропускную способность на 50 процентов. Это, по крайней мере, идет в ногу с 50-процентным увеличением чистой производительности операций с плавающей запятой. Подробное сравнение V100 с P100 и предыдущими графическими процессорами Tesla приведено ниже.
Источник: NVIDIA
300-ваттный Tesla V100 предназначен для суперкомпьютеров и небольших кластеров или устройств, предназначенных для обучения нейронных сетей, высокопроизводительных вычислений и ускорения баз данных.Общая идея здесь — максимизировать производительность на сервере. Вы также можете делать выводы из глубокого обучения с помощью этой верхней части, но обычно она не используется таким образом, поскольку NVIDIA также предложит версию на 150 Вт, которая лучше соответствует типу инфраструктуры, используемой для этой задачи.
NVIDIA заявляет, что 150-ваттный Tesla V100 обеспечивает 80 процентов производительности 300-ваттного компонента. Он использует точно такой же графический процессор; только тактовая частота была уменьшена для повышения энергоэффективности.Аудитория здесь — поставщики облачных услуг, которым нужна часть с меньшим энергопотреблением, которую можно было бы массово развернуть в гипермасштабируемом центре обработки данных либо для логического вывода нейронной сети, либо для обучения (или и того, и другого). 150 Вт — это в значительной степени верхний предел для ускорителя в гипермасштабируемой среде, но инженеры NVIDIA здесь, в GTC, предложили дополнительно снизить мощность для клиентов с более ограниченными требованиями к мощности.
Хотя NVIDIA не говорила о маломощном V100 для высокопроизводительных вычислений, нет причин, по которым его нельзя было бы использовать для такой работы.Конечно, для центров обработки данных HPC с ограниченным энергопотреблением снижение мощности на 50 процентов для 80 процентов производительности может показаться привлекательным компромиссом, особенно если учесть, что на 150 Вт у вас может быть графический процессор, который немного быстрее, чем самые быстрые на сегодняшний день 250 Вт. ватт P100. В зависимости от того, как NVIDIA оценивает маломощный V100, он может оказаться довольно популярным ускорителем для традиционных HPC.
Архитектурные улучшения в Volta многочисленны и разнообразны. Наиболее важным является добавление вышеупомянутых тензорных ядер, которые обеспечивают 120 тензорных терафлопс для обучения и вывода нейронных сетей.Это в 12 раз быстрее, чем P100 для операций FP32, используемых для обучения, и в 6 раз быстрее, чем P100 для FP16, используемых для вывода.
Вкратце, тензорные ядра обеспечивают операции обработки матриц, которые хорошо согласуются как с обучением глубокому обучению, так и с логическими выводами, которые включают в себя умножение больших матриц данных и весов, связанных с нейронными сетями. В частности, каждое из 640 тензорных ядер выполняет операции с плавающей запятой смешанной точности с массивом 4x4x4. За один такт каждое ядро может выполнять 64 операции FMA (плавное умножение-сложение).Каждая FMA умножает две матрицы FP16 и добавляет матрицу FP16 или FP32, а результат сохраняется в матрице FP16 или FP32.
Другие обновления Volta включают в себя гораздо более быстрый кэш L1, оптимизированный набор инструкций для более быстрого декодирования и уменьшения задержек, блоки FP32 и INT32, которые теперь могут работать параллельно, и операции FMA, которые могут выполняться за четыре тактовых цикла вместо шести, требуемых в архитектура Паскаля. Volta также поддерживает независимое планирование потоков, что позволяет разработчикам проявлять больше творчества в своем коде и обеспечивает более мелкозернистый параллелизм.Более подробное описание всех этих функций можно увидеть на веб-странице NVIDIA Volta.
Первые детали Tesla V100 будут доступны в третьем квартале 2017 года. Amazon уже обязалась создавать новые экземпляры с новыми графическими процессорами, как только они смогут закупить их в большом количестве. Министерство энергетики также имеет дело с некоторыми из самых ранних устройств, поскольку они являются ускорителем, который будет питать суперкомпьютеры агентства Summit и Sierra. Ожидается, что строительство обеих систем начнется до конца года.Среди других первых клиентов V100 — Baidu, Facebook, Microsoft и Tencent.
Nvidia Volta против Pascal: сравнение характеристик с ценой
Volta — это новая графическая архитектура, выпущенная Nvidia. Новую архитектуру еще предстоит сделать доступной для потребительского рынка в целом. Volta — это то, что заменяет архитектуру Pascal Graphics. Какие изменения это принесет с собой? Nvidia Volta будет поставляться с поддержкой DirectX 12 и настроена для предоставления расширенных возможностей асинхронной обработки.Мы проверим обе архитектуры ( Nvidia Volta против Pascal ) и сравним их, чтобы прийти к тому, чего мы могли ожидать.
Nvidia Volta против Pascal — Сравнение спецификаций
Nvidia недавно выпустила новейшую архитектуру Volta Graphic в качестве преемника архитектуры Pascal. Архитектура будет использоваться для управления производительностью их видеокарт. Фактически, будучи новейшей графической архитектурой, она действительно принесет более значительные улучшения и усовершенствования при ее развертывании.
И Nvidia Volta, и Nvidia Pascal являются вариантами графической архитектуры, очевидно, от Nvidia и предназначены для повышения производительности компьютера. Мы проверим обе эти архитектуры на предмет их функций, а затем сравним их на основе их функций и возможностей.
Графическая архитектура Nvidia Pascal — ОбзорPascal — это современная графическая архитектура от Nvidia. Архитектура Pascal используется в линейке игровых видеокарт GeForce и других видеокартах WorkStation, таких как P Series.
Графические карты, работающие на Паскале, будут работать на производственных системах FinFET 14нм / 16нм. Графическая архитектура Pascal поддерживает память GDDR5, GDDR5X и HBM2. Для тех, кто не знает, память GDDR5 используется для бюджетных и средних видеокарт, в то время как GDDR5X будет памятью, поддерживаемой на видеокартах на основе архитектуры высокого класса. HBM2 — это память, используемая в видеокартах для рабочих станций высокого класса.
Некоторые из функций, которые вы можете найти в архитектуре Pascal: —
- Архитектура поддерживает VR (потребление и разработка)
- Графические карты для рабочих станций предлагают функциональность NVLink.
- Вы найдете поддержку DirectX 12, OpenGL 4.5 и Vulkan.
- Архитектура Pascal поддерживает технологию Multi-GPU SLI, как и их потребительские видеокарты GeForce.
- Он имеет ядра CUDA.
Volta оказалась последней в серии графических архитектур от Nvidia. Доминирующая особенность, которая могла бы сделать его одним из лучших вариантов, — это мощность, в которой он заключен. Разработанная, чтобы прийти на смену графической архитектуре Pascal, которую мы только что описали выше, Volta Graphics Architecture использует ядра Tensor в дополнение к ядрам CUDA.
Графическая архитектура Volta — это то, что поддерживает Architectural Intelligence. Это сделало бы их пригодными для машинного обучения и других подобных высокопроизводительных программ. Он будет работать на высокотехнологичных 12-нанометровых производственных процессах. Графическая архитектура Volta будет работать с памятью HBM 2 . Вы можете быть уверены в отличной производительности компьютера.
Некоторые характерные особенности графической архитектуры Volta можно резюмировать как —
- Она работает на тензорных ядрах и поддерживает искусственный интеллект и машинное обучение.
- Поддержка NVLink 2.0 обеспечит более высокую пропускную способность.
- Архитектура поддерживает высокопроизводительные видеокарты.
- Увеличение количества ядер CUDA должно означать повышение производительности.
Табличная компиляция функций предоставит вам отличный вариант для идеального сравнения двух графических архитектур. Здесь мы представляем сравнение в виде диаграммы —
| Особенности / особенности | Pascal [amazon_link asins = ‘B01JLKP3IS’ template = ‘PriceLink’ store = ‘foi04-20’ marketplace = ‘US’ link_id = ‘8f4215ca-6bb7-11e8-b8cb-79f432177e02 ′] | Volta [amazon_link asins =’ B078G1VHYN ‘template =’ PriceLink ‘store =’ foi04- ‘link67’ marketplace = ‘US_67idb =’ US_IDB9 6bb7-11e8-be58-0315f3f369b0 ′] | |||
| Производитель | Nvidia | Nvidia | |||
| Поддерживаемые графические карты | GeForce 10 series, Titan XP 9010 серии 9010, рабочая станция 9010 Van | ||||
| Поддерживаемые типы памяти | GDDR5, GDDR5X, HBM2 | HBM2 | |||
| Производственный процесс | 14 нм или 16 нм | 12 нм | |||
| Поддержка VR | Да | ||||
| Поддерживаемая версия DirectX | Да, 12 | Да, 12 | |||
| Поддержка Open GL | Да | Да | |||
| Поддержка нескольких графических процессоров | Да, всего несколько карт, NVLink, SLI | NVLink 2 | |||
| Приложения поддержки | Игровая или рабочая станция | Игры / рабочая станция / искусственный интеллект, машинное обучение и игры | |||
| Энергопотребление | 250 Вт | 250 Вт | Размер матрицы 471 кв.мм | 815 кв. мм | |
| Количество транзисторов | 12 миллиардов | 21 миллиард | |||
| Количество ядер CUDA | 3840 | 5120 | |||
| 9010 | Nensor Cores|||||
| SMMS или SMXs | 30 | 40 | |||
| Тактовые ядра графического процессора | 1405 МГц | 1200 МГц | |||
| Шина памяти | 384 бит | Полоса пропускания | 3072 бит ГБ в секунду | 653 ГБ в секунду |
Что ж, Volta действительно намного лучше Паскаля.Хотя мы никоим образом не умаляем Паскаль, Volta намерена внести новые изменения в функциональность архитектуры с некоторыми собственными улучшениями.
Некоторые из них можно суммировать как —
- Усовершенствованная базовая архитектура на Volta должна работать в направлении повышения производительности сама по себе.
- Volta представляет новые тензорные ядра. Это улучшит совместимость с искусственным интеллектом.
- Увеличено количество ядер CUDA, поскольку Volta поставляется с 5210 ядрами по сравнению с 3840 на Pascal.
- 3072-битный интерфейс значительно улучшен по сравнению с самым высоким 384-битным интерфейсом GDDR5X.
Помимо вышеуказанных улучшений, мы также заметили несколько минусов. Тактовая частота была снижена по сравнению с Паскалем. Мы также не сочли бы это исключительно колоссальным разочарованием.
Ожидается, что сервис и архитектура будут развиваться и дальше. Мы ожидаем (или, лучше сказать, догадываемся), что новые версии архитектуры Volta Graphics действительно принесут более современные усовершенствования для поддержки будущих технологий.
В заключениеУчитывая улучшения производительности и необходимость в улучшенных архитектурных оптимизациях, следует ожидать появления более мощных графических процессоров в будущем.