Что такое нейросеть. Объясняем простыми словами — Секрет фирмы
Человеческий мозг состоит из нейронов, связанных между собой синапсами и передающих электрохимические импульсы. Нейросеть же состоит из искусственных нейронов — вычислительных элементов, созданных по модели биологического нейрона.
Нейронные сети уже широко используются в разных областях жизни — распознают лица (в том числе ловят преступников), диагностируют болезни, работают как голосовые помощники. В том числе растёт их применение в бизнесе: оценка эффективности сотрудников, одобрение кредита, чат-боты, управление кол-центрами.
Примеры употребления на «Секрете»
«То, что мы уже начали повсеместно использовать нейронные сети, но ещё не поняли до конца, как они работают, — это очень странный и очень интересный факт».
(CEO Wallarm Иван Новиков — об угрозах искусственного интеллекта.)
«Главное отличие нейронных сетей от других технологий в том, что они требуют минимальной работы с признаками (feature engineering). Если при классическом машинном обучении чаще всего приходится производить сложные алгоритмические процедуры с исходными обучающими данными, то нейронные сети удаётся хорошо обучать на сырых данных».
Если при классическом машинном обучении чаще всего приходится производить сложные алгоритмические процедуры с исходными обучающими данными, то нейронные сети удаётся хорошо обучать на сырых данных».
(Руководитель группы исследования технологий извлечения информации ABBYY Анатолий Старостин — о том, что нужно знать про нейросети.)
Нюансы
Искусственная нейросеть, конечно, всё ещё значительно отличается от человеческого мозга. Для работы даже миллиона искусственных нейронов требуются мощные компьютеры. Синапсов, или связей между нейронами, в биологическом мозге тоже намного больше, и работать они могут параллельно друг с другом, в отличие от компьютера, который даже простую задачу разбивает на последовательные шаги.
Интересные факты
Нейросети уже научились делать множество вещей: сочинять песни, прогнозировать урожай, распознавать сексуальное влечение, диагностировать депрессию, писать хорроры, бороться с коррупцией и подделывать голоса.
Статью проверил:
Нейросеть 2021
Камера с искусственным интеллектом
Современный процессор должен иметь возможность запускать нейросетевую видеоаналитику. В сравнении с обычными процессоры умных камер чаще всего имеют улучшенный графический (GPU, Graphics Processing Unit) чипсет, который дает больше вычислительной мощности для алгоритмов, потребляя при этом меньше энергии и выделяя меньше тепла.
В сравнении с обычными процессоры умных камер чаще всего имеют улучшенный графический (GPU, Graphics Processing Unit) чипсет, который дает больше вычислительной мощности для алгоритмов, потребляя при этом меньше энергии и выделяя меньше тепла.
Стоит отметить, что со стремительным развитием искусственного интеллекта начинают появляться специализированные чипсеты, приходящие на смену привычным CPU (Central Processing Unit) и GPU. Среди них NPU (Neral Processing Unit) или TPU (Tensor Processing Unit). Расчетные мощности нейросетей требуют от процессоров значительных ресурсов. До сегодняшнего времени пользователи выбирали, на каком типе процессоров производить расчеты, графическом (GPU) или центральном (CPU). При этом GPU более подходит под требования нейросетевых вычислений, а значит выполняет их более эффективно. В настоящее время производители процессоров, комбинируя преимущества CPU и GPU в одной микросхеме, выпускают специализированные гибридные чипы, узко направленные на нейросетевые вычисления или работу с «морем» множителей, потребляющие при этом меньше энергии.
Как различать камеры с искусственным интеллектом? Читайте в статье «Как устроены камеры с искусственным интеллектом» >>>
Что умеет нейросетевая видеоаналитика?
Часто приходится слышать, что рынок систем видеонаблюдения все больше коммодитизируется. Множество продуктов со схожей функциональностью (или, по крайней мере, схожими обещаниями производителя) затрудняют выбор для пользователя, и одним из главных аргументов становится имя вендора и его репутация. У самих производителей остается два пути: или ввязаться в ценовую войну, делая ставку на максимальную оптимизацию затрат, или предложить что-то действительно новое и прорывное.
Тренд, который пытаются оседлать разработчики, выбравшие второй путь, – искусственный интеллект, основанный на нейронных сетях и глубоком обучении. Зародившийся несколько лет назад рынок ИИ-видеоаналитики находится в стадии взрывного роста. Новая технологическая волна добавила оптимизма небольшим, но амбициозным компаниям. Кажется, у них появился шанс прорваться к лидерству – в перспективе нескольких лет.
Новая технологическая волна добавила оптимизма небольшим, но амбициозным компаниям. Кажется, у них появился шанс прорваться к лидерству – в перспективе нескольких лет.
Однако хайп, поднятый новым модным трендом, вызывает здравые опасения умудренных опытом профессионалов рынка безопасности, как со стороны клиента, который ищет решение для своих задач, так и со стороны интегратора, который строит стратегию долгосрочного развития. Это очень похоже на очередной технологический «пузырь». Такой, который уже успел надуться вокруг видеоаналитики без нейронных сетей и громко лопнуть, когда стало ясно, что громкие обещания – всего лишь (не очень добросовестная) реклама. Но в пользу того, что ИИ в системах видеонаблюдения не «пузырь», говорит множество фактов.
Первый (и главный) – это работающие системы на реальных объектах. Они выполняют те самые обещания, которые в эпоху предыдущего «пузыря» давали горячие головы, пытающиеся научить компьютер анализировать реальность, используя классический алгоритмический подход.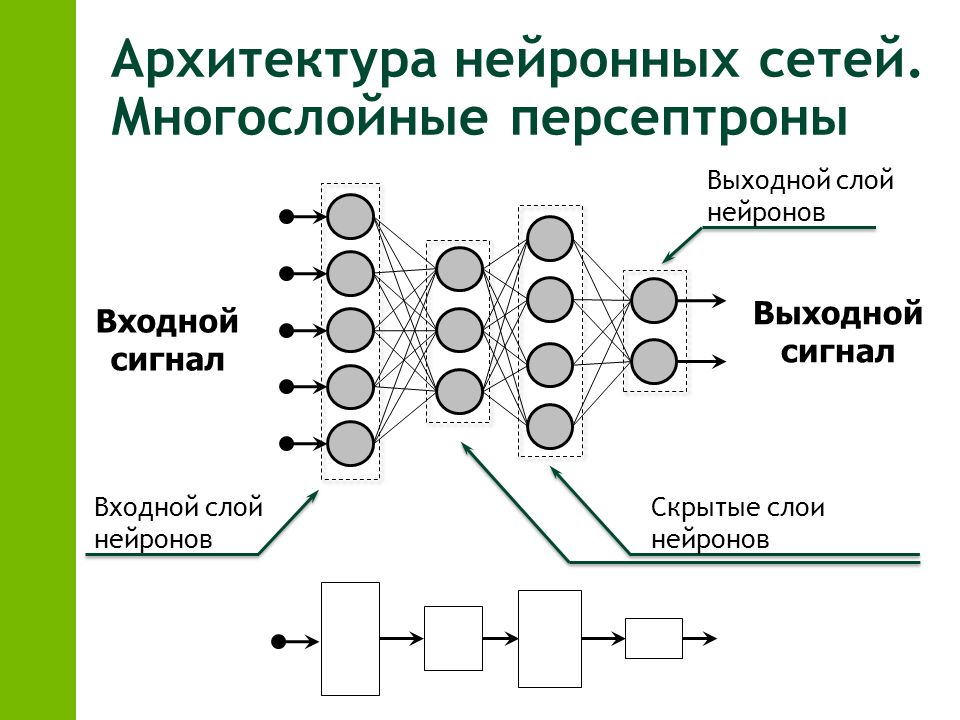
На что способен искусственный интеллект и как работает поведенческая видеоаналитика — читайте полный текст статьи «Что умеет и чего не умеет нейросетевая видеоаналитика?» >>>
Могут ли нейросети распознать человеческую ложь
Если человек хочет скрыть, что лжет, то он может попытаться сознательно контролировать свои физиологические реакции. Однако согласно исследованиям в области лжи, контролировать все физиологические параметры одновременно и согласованно довольно трудно. Поэтому современные научные методы создания детектора лжи основаны на анализе всей совокупности неосознаваемых физиологических реакций, включая мимические выражения лица. Этот подход дает более полноценное понимание, и именно его используют разработчики нейросетевых детекторов лжи, в том числе мы.
Если же говорить о том, как именно научить нейросеть определять ложь, то тут есть два подхода:
- дать ей видео, где люди лгут или говорят правду, и разметку для этих данных;
- заранее выделить признаки, такие как, например, физиологические параметры и мимические выражения лица.
 На основе этих признаков и разметки видео (т.е. в какой момент человек говорит правду, а когда обманывает), нейросеть может обучиться распознавать те случаи, когда человек преднамеренно лжет.
На основе этих признаков и разметки видео (т.е. в какой момент человек говорит правду, а когда обманывает), нейросеть может обучиться распознавать те случаи, когда человек преднамеренно лжет.
 На основе этих признаков и разметки видео (т.е. в какой момент человек говорит правду, а когда обманывает), нейросеть может обучиться распознавать те случаи, когда человек преднамеренно лжет.
На основе этих признаков и разметки видео (т.е. в какой момент человек говорит правду, а когда обманывает), нейросеть может обучиться распознавать те случаи, когда человек преднамеренно лжет.Но здесь важно осознавать, что, как и полиграф, нейросеть сама по себе не понимает, что такое правда или ложь, и не может самостоятельно определить, что в какой-то момент человек солгал. Нейросеть только показывает, что физиологические параметры человека изменяются в сравнении с его личной «нормой». Уже на основе этих данных человек-оператор, использующий нейросеть, понимает, что в какие-то моменты когнитивная нагрузка человека отличается от его «нормы», и дальнейшая интерпретация этих данных зависит уже от него. Поэтому важно учитывать, что когнитивная нагрузка и физиологические показатели могут отличаться как потому, что человек действительно лжет, так и оттого, что разговор вызывает у него сильный отклик по каким-то другим причинам (например, в его жизни был травмирующий эпизод, связанный с темой беседы).
Глубокие нейросети: руководство для начинающих | by Victoria Likhanova | NOP::Nuances of Programming
Введение
ИИ уже успел достаточно нашуметь — о нейросетях сейчас знают и в научной среде, и в бизнесе. Вам наверняка случалось читать, что совсем скоро ваши рабочие процессы уже не будут прежними из-за какой-нибудь формы ИИ или нейросети. И вы, я уверен, слышали (пусть и не всё) о глубоких нейронных сетях и глубоком обучении.
В этой статье я приведу самые короткие, но эффективные способы понять, что такое глубокие нейронные сети, а также расскажу о том, как внедрить их с помощью библиотеки PyTorch.
Определение глубоких нейросетей (глубокого обучения) для новичков
Попытка 1
Глубокое обучение — это подраздел машинного обучения в искусственном интеллекте (ИИ), алгоритмы которого основаны на биологической структуре и функционировании мозга и призваны наделить машины интеллектом.
Сложно звучит? Давайте разобьём это определение на отдельные слова и составим более простое объяснение. Начнём с искусственного интеллекта, или ИИ.
Начнём с искусственного интеллекта, или ИИ.
Artificial Intelligence - Искусственный интеллект
Machine Learning - Машинное обучение
Deep Learning - Глубокое обучение
Искусственный интеллект (ИИ) в наиболее широком смысле — это разум, встроенный в машину. Обычно машины глупые, поэтому, чтобы сделать их умнее, мы внедряем в них интеллект — в результате машина может самостоятельно принимать решения. К примеру, стиральная машина определяет необходимый объём воды, а также требуемое время для замачивания, стирки и отжима. Таким образом, она принимает решение, основываясь на конкретных вводных условиях, а значит делает свою работу разумнее. Или, например, банкомат, который выдаёт нужную вам сумму, составляя правильную комбинацию из имеющихся в нём банкнот. Такой интеллект внедряется в машины искусственным путём — отсюда и название “искусственный интеллект”.
Важно отметить, что интеллект здесь запрограммирован явно, то есть создан на основе подробного списка правил вида “если…, то…”. Инженер-проектировщик тщательно продумал все возможные комбинации и создал систему, которая принимает решения, проходясь по цепочке правил. А что если нам нужно внедрить интеллект в машину без явного программирования, то есть, чтобы машина училась сама? Здесь-то мы и подходим к теме машинного обучения.
Машинное обучение — это процесс внедрения интеллекта в систему или машину без явного программирования.
— Эндрю Ын, адъюнкт-профессор Стэнфордского университета
Примером машинного обучения могла бы стать система, предсказывающая результат экзамена на основе предыдущих результатов и характеристик студента. В этом случае решение о том, сдаст студент экзамен или нет, основывалось бы не на подробном списке всех возможных правил — напротив, система обучалась бы сама, отслеживая паттерны в предыдущих наборах данных.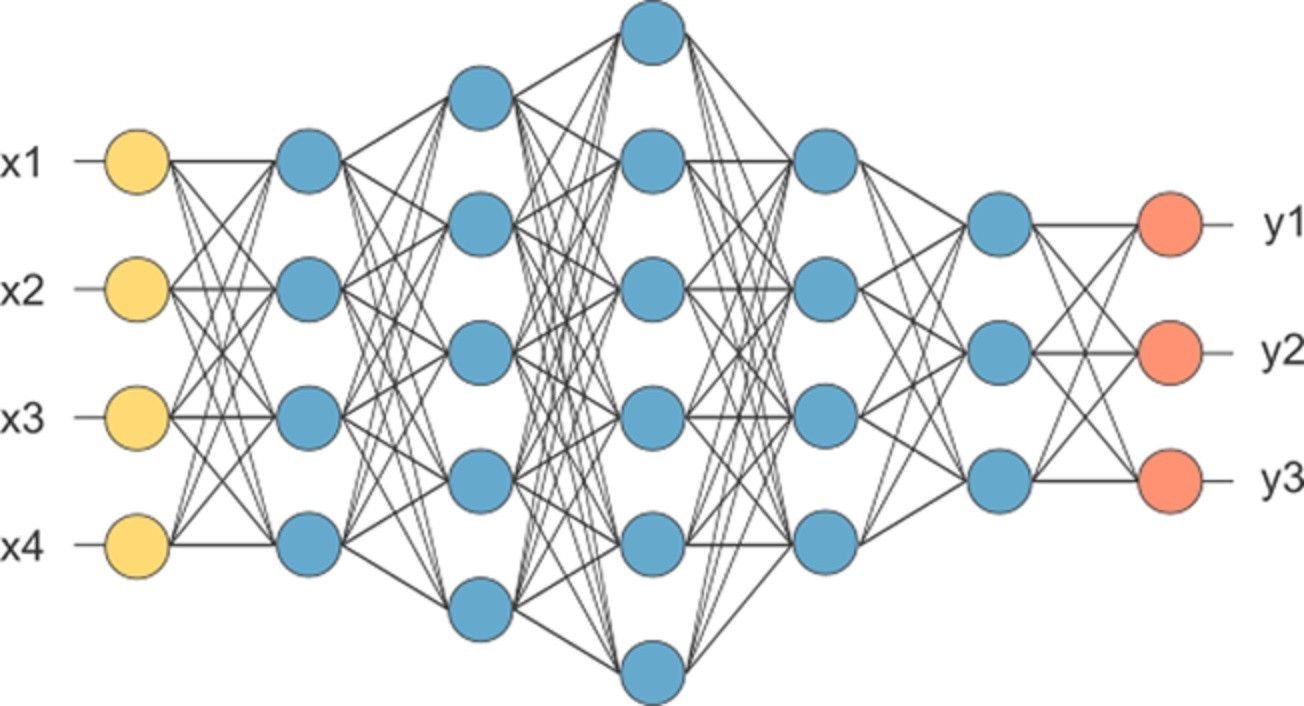
Так где же в этом контексте место глубокого обучения? Машинное обучение успешно решает многие вопросы, но порой не может справиться с задачами, которые кажутся людям очень простыми. К примеру, оно не может отличить кошку от собаки на картинке или мужской голос от женского на аудиозаписи и т. п. Результаты применения машинного обучения чаще всего плохие при обработке изображений, аудио и других типов неструктурированных данных. При поиске причин таких результатов пришло озарение — идея скопировать биологические процессы человеческого мозга, который состоит из миллиардов нейронов, связанных и скоординированных между собой особым образом для изучения нового. Изучение нейронных сетей шло одновременно с этим уже несколько лет, но прогресс был небольшим из-за ограничений в данных и вычислительных мощностях того времени. Когда машинное обучение и нейросети были достаточно изучены, появилось глубокое обучение, которое предполагало создание глубоких нейронных сетей, то есть произвольных нейросетей с гораздо большим количеством слоёв.
Теперь давайте вновь взглянем на определение глубокого обучения.
Попытка 2
Глубокое обучение — это раздел машинного обучения и искусственного интеллекта с алгоритмами, основанными на деятельности человеческого мозга и призванными внедрить интеллект в машину без явного программирования.
Стало гораздо понятнее, правда? 🙂
Там, где машинное обучение не справлялось, глубокое обучение применялось успешно. С течением времени проводились дополнительные исследования и эксперименты, позволившие понять, для каких ещё задач мы можем задействовать глубокое обучение и получать качественные результаты при достаточном объёме данных. Глубокое обучение стали широко использовать для решения прогностических задач, не ограничивая его применение машинным распознаванием образов, речи и т. п.
Какие задачи глубокое обучение решает сегодня?
С появлением экономически эффективных вычислительных мощностей и накопителей данных глубокое обучение проникло во все цифровые аспекты нашей повседневной жизни. Вот несколько примеров цифровых продуктов из обычной жизни, в основе которых лежит глубокое обучение:
Вот несколько примеров цифровых продуктов из обычной жизни, в основе которых лежит глубокое обучение:
- популярные виртуальные помощники Siri/Alexa/Google Assistant;
- предложение отметить друга на только что загруженной фотографии в Facebook;
- автономное вождение в автомобилях Tesla;
- фильтр с кошачьими мордами в Snapchat;
- рекомендации в Amazon и Netflix;
- недавно выпущенные, но получившие вирусную популярность приложения для обработки фото — FaceApp и Prisma.
Возможно, вы уже пользовались приложениями с применением глубокого обучения и просто не знали об этом.
Глубокое обучение проникло буквально во все отрасли. К примеру, в здравоохранении с его помощью диагностируют онкологию и диабет, в авиации — оптимизируют парки воздушных судов, в нефтегазовой индустрии— проводят профилактическое техобслуживание оборудования, в банковской и финансовой сферах — отслеживают мошеннические действия, в розничной торговле и телекоммуникациях — прогнозируют отток клиентов и т. д. Эндрю Ын верно назвал ИИ новым электричеством: подобно тому, как электричество в своё время изменило мир, ИИ также изменит практически всё в ближайшем будущем.
д. Эндрю Ын верно назвал ИИ новым электричеством: подобно тому, как электричество в своё время изменило мир, ИИ также изменит практически всё в ближайшем будущем.
Из чего состоит глубокая нейронная сеть?
Упрощённая версия глубокой нейросети может быть представлена как иерархическая (слоистая) структура из нейронов (подобно нейронам в мозге), связанных с другими нейронами. На основе входных данных одни нейроны передают команду (сигнал) другим и таким образом формируют сложную сеть, которая обучается с помощью определённого механизма обратной связи. На диаграмме ниже изображена глубокая нейронная сеть с количеством слоёв N.
Глубокая нейросеть с N скрытых слоёвNeuron - Нейрон
Input Data - Входные данные
Output - Выход
Layer - Слой
Output Layer - Выходной слой
Hidden Layer - Скрытый слой
Как видно на рисунке выше, входные данные передаются нейронам на первом (не скрытом) слое, они в свою очередь передают выходные данные нейронам на следующем слое и так далее до финального выхода. Выход может представлять собой прогноз (вроде “Да”/“Нет”), представленный через вероятность. На каждом слое может быть один или множество нейронов, каждый из которых вычисляет небольшую функцию, функцию активации. Эта функция имитирует передачу сигнала последующим, связанным с предыдущими, нейронам. Если результат входных нейронов превышает порог, выходное значение просто игнорируется и передаётся дальше. Связь между двумя нейронами соседних слоёв имеет вес. Вес определяет влияние входных данных на выход для следующего нейрона и последующий финальный выход. Начальные веса нейросети случайные, однако в процессе обучения модели они постоянно обновляются и обучаются предсказывать верное выходное значение. В процессе анализа нейросети можно обнаружить несколько логических структурных элементов (нейрон, слой, вес, вход, выход, функция активации и наконец механизм обучения, или оптимизатор), которые помогают ей постепенно заменять веса (изначально со случайными значениями) на более подходящие для точного прогноза выхода.
Выход может представлять собой прогноз (вроде “Да”/“Нет”), представленный через вероятность. На каждом слое может быть один или множество нейронов, каждый из которых вычисляет небольшую функцию, функцию активации. Эта функция имитирует передачу сигнала последующим, связанным с предыдущими, нейронам. Если результат входных нейронов превышает порог, выходное значение просто игнорируется и передаётся дальше. Связь между двумя нейронами соседних слоёв имеет вес. Вес определяет влияние входных данных на выход для следующего нейрона и последующий финальный выход. Начальные веса нейросети случайные, однако в процессе обучения модели они постоянно обновляются и обучаются предсказывать верное выходное значение. В процессе анализа нейросети можно обнаружить несколько логических структурных элементов (нейрон, слой, вес, вход, выход, функция активации и наконец механизм обучения, или оптимизатор), которые помогают ей постепенно заменять веса (изначально со случайными значениями) на более подходящие для точного прогноза выхода.
Для более ясного понимания давайте рассмотрим, как человеческий мозг учится различать людей. Когда вы встречаете человека во второй раз, то узнаёте его. Как так получается? У всех людей схожее строение: два глаза, два уха, нос, губы и т. д. Все одинаково устроены, и, тем не менее, различать людей нам довольно легко, не так ли?
Природа процесса обучения человеческого мозга довольно очевидна. Вместо того чтобы для узнавания людей изучать структуру лица, мы изучаем отклонения от типичного лица, то есть то, насколько сильно отличаются глаза конкретного человека от типичного глаза. Далее эта информация преобразуется в электрический сигнал определённой силы. Подобным же образом изучаются отклонения всех остальных частей лица от типичных. Все эти отклонения в итоге собираются в новые признаки и дают выходное значение. Всё описанное происходит за доли секунды, и мы просто не успеваем понять, что произошло в нашем подсознании.
Как показано выше, нейросеть пытается имитировать тот же процесс, используя математический подход. Входные данные принимаются нейронами первого слоя, и в каждом нейроне вычисляется функция активации. На основе простого правила нейрон передаёт выходное значение следующему нейрону, подобно тому, как человеческий мозг изучает отклонения. Чем больше выход нейрона, тем большее значение имеет соответствующий входной признак. На последующем слое эти признаки объединяются в новые, которые имеют пока непонятную для нас форму, но система обучается им интуитивно. Повторённый множество раз этот процесс приводит к формированию сложной сети со связями.
Входные данные принимаются нейронами первого слоя, и в каждом нейроне вычисляется функция активации. На основе простого правила нейрон передаёт выходное значение следующему нейрону, подобно тому, как человеческий мозг изучает отклонения. Чем больше выход нейрона, тем большее значение имеет соответствующий входной признак. На последующем слое эти признаки объединяются в новые, которые имеют пока непонятную для нас форму, но система обучается им интуитивно. Повторённый множество раз этот процесс приводит к формированию сложной сети со связями.
Теперь, когда структура нейросетей понятна, давайте разберёмся, как происходит обучение. Из входных данных, которые мы предоставляем сети, на выходе получается прогноз (с серией матричных умножений), который может быть верным или неверным. В зависимости от выхода мы можем потребовать от сети более точных прогнозов, и система будет обучаться, меняя значения весов для нейронных связей. Чтобы правильно дать сети обратную связь и определить следующий шаг для внесения изменений, мы используем элегантный математический алгоритм “обратного распространения ошибок”. Повторение процесса шаг за шагом несколько раз с нарастающим объёмом данных позволяет нейросети обновлять веса соответствующим образом и создаёт систему, в которой сеть может делать прогноз на основе созданных ею через веса и связи правил.
Повторение процесса шаг за шагом несколько раз с нарастающим объёмом данных позволяет нейросети обновлять веса соответствующим образом и создаёт систему, в которой сеть может делать прогноз на основе созданных ею через веса и связи правил.
Название “глубокие нейронные сети” пошло от использования множества скрытых слоёв, которые и делают нейросеть “глубокой”, способной обучаться более сложным паттернам. Истории успешного применения глубокого обучения только-только начали появляться в последние годы, ведь процесс обучения нейронной сети сложный по части вычислений и требует больших объёмов данных. Эксперименты наконец увидели свет, только когда возможности вычисления и хранения данных стали более доступными.
Какие есть популярные фреймворки для глубокого обучения?
Учитывая то, что внедрение глубокого обучения прошло быстрыми темпами, прогресс экосистемы для него также стал феноменальным. Благодаря множеству крупных технологических компаний и проектов с открытым исходным кодом вариантов для выбора более чем достаточно. Эти фреймворки глубокого обучения предоставляют блоки кода для многократного использования, из которых можно составить описанные выше логические блоки, а также несколько удобных дополнительных модулей для создания модели глубокого обучения.
Эти фреймворки глубокого обучения предоставляют блоки кода для многократного использования, из которых можно составить описанные выше логические блоки, а также несколько удобных дополнительных модулей для создания модели глубокого обучения.
Все доступные варианты фреймворков глубокого обучения можно разделить на низкоуровневые и высокоуровневые. Пусть такая терминология и не принята в этой области, но мы можем использовать это разделение, чтобы облегчить себе понимание фреймворков. Низкоуровневые фреймворки предлагают более базовый функционал для абстракции, который в то же время даёт массу возможностей для кастомизации и трансформации. Высокоуровневые фреймворки упрощают нам работу своей более продвинутой абстракцией, но ограничивают нас во внесении изменений. Высокоуровневые фреймворки используют низкоуровневые на бэкенде и в процессе работы конвертируют источник в желаемый низкоуровневый фреймворк для выполнения. Ниже приведены несколько вариантов популярных фреймворков для глубокого обучения.![]()
Низкоуровневые фреймворки:
- TensorFlow
- MxNet
- PyTorch
Высокоуровневые фреймворки:
- Keras (использует TensorFlow на бэкенде)
- Gluon (использует MxNet на бэкенде)
Самый популярный сейчас фреймворк — TensorFlow от Google. Keras также довольно популярен благодаря быстрому прототипированию моделей глубокого обучения и, следовательно, упрощению работы. PyTorch от Facebook — ещё один фреймворк, который стремительно догоняет конкурентов. PyTorch может стать прекрасным выбором для многих специалистов по ИИ: он затрачивает меньше времени на обучение, чем TensorFlow, и может легко применяться на всех этапах создания модели глубокого обучения — от прототипирования до внедрения.
В этом руководстве для внедрения небольшой нейросети мы предпочтём именно PyTorch. Но прежде чем сделать свой выбор фреймворка изучите и другие варианты. В этой статье (eng) приводится отличное сравнение и детальное описание разных фреймворков — это поможет вам в выборе. Однако в ней нет введения в PyTorch — для этого я рекомендую ознакомиться с официальной документацией.
Однако в ней нет введения в PyTorch — для этого я рекомендую ознакомиться с официальной документацией.
Создание небольшой нейронной сети с PyTorch
Вкратце изучив тему, мы можем приступить к созданию простой нейронной сети с помощью PyTorch. В этом примере мы генерируем набор фиктивных данных, которые имитируют сценарий классификации с 32 признаками (колонки) и 6000 образцов (строки). Набор данных обрабатывается с помощью функции randn в PyTorch.
Этот код вы также можете найти на Github.
#Импорт требуемых библиотек
import torch as tch
import torch.nn as nn
import numpy as np
from sklearn.metrics import confusion_matrix#Создание 500 результатов с помощью randn | Присвоен тег 0
X1 = tch.randn(3000, 32)
#Создание ещё 500 немного отличающихся от X1 результатов с помощью randn | Присвоен тег 0
X2 = tch.randn(3000, 32) + 0.5
#Комбинирование X1 и X2
X = tch.cat([X1, X2], dim=0)#Создание 1000 Y путём комбинирования 50% 0 и 50% 1
Y1 = tch.
Y2 = tch.ones(3000, 1)
Y = tch.cat([Y1, Y2], dim=0)# Создание индексов данных для обучения и расщепления для подтверждения:
batch_size = 16
validation_split = 0.2 # 20%
random_seed= 2019#Перемешивание индексов
dataset_size = X.shape[0]
indices = list(range(dataset_size))
split = int(np.floor(validation_split * dataset_size))
np.random.seed(random_seed)
np.random.shuffle(indices)#Создание индексов для обучения и подтверждения
train_indices, val_indices = indices[split:], indices[:split]
#Создание набора данных для обучения и подтверждения
X_train, x_test = X[train_indices], X[val_indices]
Y_train, y_test = Y[train_indices], Y[val_indices]#Отрисовка формы каждого набора данных
print("X_train.shape:",X_train.shape)
print("x_test.shape:",x_test.shape)
print("Y_train.shape:",Y_train.shape)
print("y_test.shape:",y_test.shape)#Создание нейронной сети с 2 скрытыми слоями и 1 выходным слоем
#Скрытые слои имеют 64 и 256 нейронов
#Выходные слои имеют 1 нейронclass NeuralNetwork(nn.
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(32, 64)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(64, 256)
self.relu2 = nn.ReLU()
self.out = nn.Linear(256, 1)
self.final = nn.Sigmoid()def forward(self, x):
op = self.fc1(x)
op = self.relu1(op)
op = self.fc2(op)
op = self.relu2(op)
op = self.out(op)
y = self.final(op)
return ymodel = NeuralNetwork()
loss_function = nn.BCELoss() #Бинарные потери по перекрёстной энтропии
optimizer = tch.optim.Adam(model.parameters(),lr= 0.001)num_epochs = 10
batch_size=16for epoch in range(num_epochs):
train_loss= 0.0#Начало явного обучения модели
model.train()for i in range(0,X_train.shape[0],batch_size):
#Извлечение пакета обучения из X и Y
input_data = X_train[i:min(X_train.shape[0],i+batch_size)]
labels = Y_train[i:min(X_train.shape[0],i+batch_size)]#Установление градиентов на 0 перед применением алгоритма обратного распространения ошибок
optimizer.#Дальнейшая передача данных
output_data = model(input_data)#Подсчёт потерь
loss = loss_function(output_data, labels)#Применение алгоритма обратного распространения ошибок
loss.backward()#Обновление весов
optimizer.step()train_loss += loss.item() * batch_size
print("Epoch: {} - Loss:{:.4f}".format(epoch+1,train_loss/X_train.shape[0] ))
#Прогнозирование
y_test_pred = model(x_test)
a =np.where(y_test_pred>0.5,1,0)
confusion_matrix(y_test,a)
 zeros(3000, 1)
zeros(3000, 1) Module):
Module): zero_grad()
zero_grad()Заключение
Целью этой статьи было вкратце познакомить новичков с глубокими нейросетями, объяснив тему простым языком. Упрощение математических расчётов и полное сосредоточение на функциональности позволит максимально эффективно использовать глубокое обучение для современных бизнес-проектов.
Читайте также:
Читайте нас в телеграмме, vk и Яндекс.Дзен
Нейронные сети: как работает мозг
В 2011 году, когда фанаты Apple стояли в очередях за новыми айфонами, The New York Times опубликовала статью «You Love Your iPhone. Literally» (Вы влюблены в свой iPhone. На самом деле). В ней рассказывалось об эксперименте, в ходе которого автор сканировал мозг 16 человек, слушающих аудиозаписи звуков звонящих или вибрирующих айфонов либо смотрящих видео с их изображением. Сканирование выявило активность островковой доли — области головного мозга, которая активизируется, когда человек чувствует любовь. «Мозг испытуемых реагировал… так же, как на присутствие или приближение любимого человека… — писал автор. — Они любили свои айфоны».
Literally» (Вы влюблены в свой iPhone. На самом деле). В ней рассказывалось об эксперименте, в ходе которого автор сканировал мозг 16 человек, слушающих аудиозаписи звуков звонящих или вибрирующих айфонов либо смотрящих видео с их изображением. Сканирование выявило активность островковой доли — области головного мозга, которая активизируется, когда человек чувствует любовь. «Мозг испытуемых реагировал… так же, как на присутствие или приближение любимого человека… — писал автор. — Они любили свои айфоны».
В ответ Times получила возмущенное письмо, подписанное десятками нейробиологов, где говорилось, что треть всех нейровизуализационных обследований фиксирует активность островковой доли. Эта область активна, когда человек ощущает изменение температуры или просто дышит. Вообще-то в 2007 году та же Times писала, что эта область мозга задействуется, когда люди испытывают чувство, противоположное любви. В статье, озаглавленной «This Is Your Brain on Politics» (Что ваш мозг думает о политике), активность островковой доли связывалась с раздражением.
Эти две статьи Times — пример того, что ученые называют «порнухой про мозг»: по их мнению, ведущие СМИ слишком упрощают достижения нейробиологии. После подобных публикаций появляются как грибы после дождя армии нейроконсультантов, утверждающих, что они могут объяснить все секреты управления и маркетинга — с точки зрения работы мозга. При всей сомнительности излагаемых в этих материалах выводов они обычно основаны на анализе снимков, сделанных во время процедуры функциональной магнитно-резонансной томографии (ФМРТ), главного инструмента нейробиологии.
Эти изображения словно навязывают подкупающе простые объяснения сложного явления. Но дело в том, что ФМРТ не всегда показывает причинно-следственную связь. Более того, мышление и поведение не «накладываются» на области мозга один к одному. Невозможно, изучая головной мозг человека, который смотрит по телевизору рекламу, сказать, что ему больше нравится — кока-кола или пепси. Невозможно, исследуя мозг двух генеральных директоров, сказать, кто из них более сильный руководитель. Сама по себе активность островковой доли еще не доказывает, что вы испытываете к своему айфону те же чувства, что и к своей невесте.
Невозможно, изучая головной мозг человека, который смотрит по телевизору рекламу, сказать, что ему больше нравится — кока-кола или пепси. Невозможно, исследуя мозг двух генеральных директоров, сказать, кто из них более сильный руководитель. Сама по себе активность островковой доли еще не доказывает, что вы испытываете к своему айфону те же чувства, что и к своей невесте.
Чтобы понять, как неврологические процессы действительно связаны с управлением, лидерством и маркетингом, надо отделить факты от вымысла, отсеять наивные интерпретации и составить более сложную картину науки о мозге.
И это уже понемногу происходит. Благодаря многим факторам — развитию технологии ФМРТ, появлению новых статистических методов и даже объявленному президентом Обамой проекту создания полной карты головного мозга человека — нейробиологи начинают мыслить новыми, более точными категориями. Они переходят от изучения активации областей мозга к изучению того, как параллельно активизируются сети областей мозга.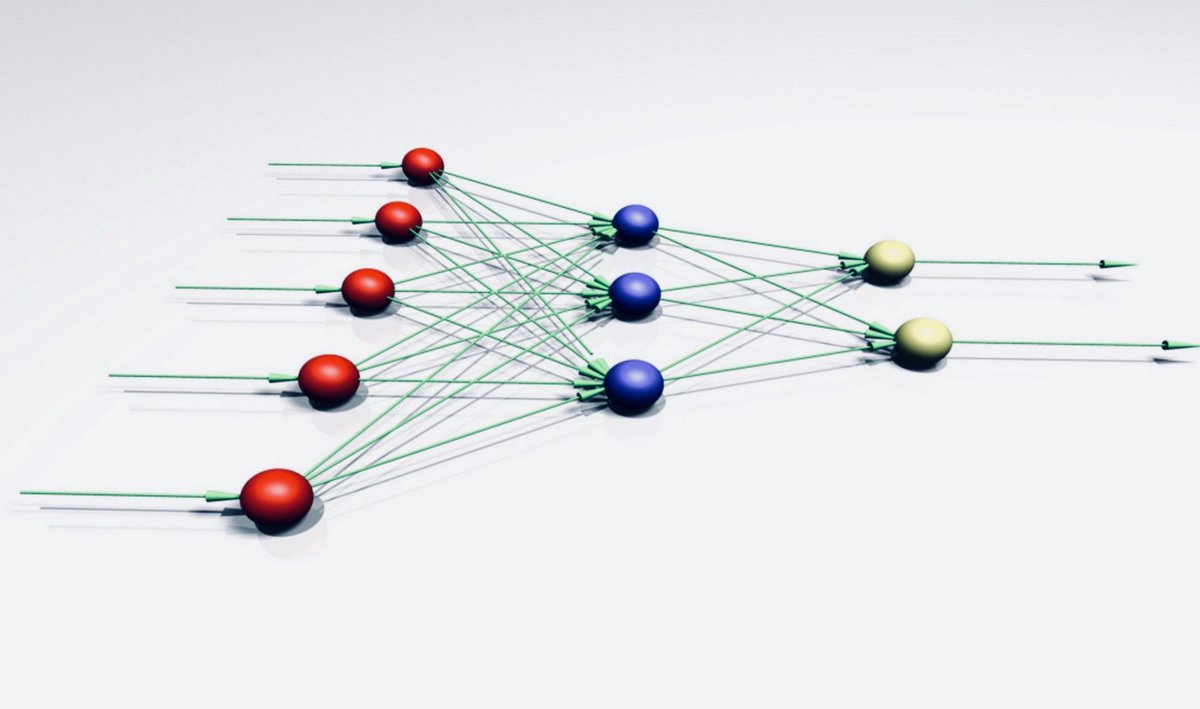
Новые инструменты и методы уже привели к новым открытиям, связанным с биологией нашего сознания, и углубили наше понимание важных, с точки зрения управления, моментов, например того:
- как стимулировать творческое мышление;
- как структурировать удовольствие;
- какую роль в принятии решений играют эмоции;
- какие возможности открывает многозадачная работа и в чем ее опасности.
Взгляд через призму нейронных сетей не так заманчив, как нынешний популярный взгляд на нейробиологию. Настоящая нейробиология, основанная на изучении сетей, сложнее. Хаотичнее. Но настоящая наука — это всегда хаос.
Ни минуты не сомневаемся, что наши рассуждения могут вызвать протесты других нейробиологов; наука так молода, что до единого мнения еще далеко и новые исследования чуть не каждую секунду уточняют то, что мы уже знаем о мозге. Тем не менее мы уверены в своем «промежуточном отчете» о тех открытиях нейробиологии, сделанных за последние 15 лет, которые уже получили веское эмпирическое обоснование.
Тем не менее мы уверены в своем «промежуточном отчете» о тех открытиях нейробиологии, сделанных за последние 15 лет, которые уже получили веское эмпирическое обоснование.
«Нейробиология на удивление мало рассказала нам о том, как работает мозг, но кое-что она рассказала очень хорошо», — говорит один наш бывший коллега. Вот этому «кое-чему» и посвящена статья. Сейчас нейробиологам известны 15 нейронных сетей и субсетей головного мозга. Мы расскажем о четырех системах, которые вызывают у ученых меньше всего споров: это сеть пассивного режима, сеть удовольствия, сеть эмоций и сеть контроля. Это основные общепризнанные нейронные сети, роль их становится все понятнее — равно как и их важность для управленцев.
Как раскрепостить новаторские способности
Одно из самых ярких нейробиологических открытий последнего десятилетия заключается в следующем: мозг никогда не находится в состоянии полного покоя. В периоды бодрствования, когда человек не сосредоточен на конкретных мыслях («витает в облаках» или полностью «отключился»), особая сеть участков мозга находится во включенном состоянии. Ее называют сетью пассивного режима. Уже само ее обнаружение произвело переворот в науке: теперь мы знаем, что мозг обрабатывает не только новую информацию, поступающую от пяти органов чувств, но и уже усвоенную, причем занимается этим значительную часть времени.
Ее называют сетью пассивного режима. Уже само ее обнаружение произвело переворот в науке: теперь мы знаем, что мозг обрабатывает не только новую информацию, поступающую от пяти органов чувств, но и уже усвоенную, причем занимается этим значительную часть времени.
Кроме того, сеть пассивного режима отвечает за одну из самых важных наших способностей — трансцендентальность, или «выход за пределы» — к познанию умозрительных, независимых от опыта явлений. Представлять себе, что может происходить в другом месте, в другое время, в голове у другого человека или вообще в совершенно ином мире, могут только люди — и именно благодаря активности сети пассивного режима. «Выходя за пределы», человеческий мозг «отвлекается» от внешних условий, а значит, перестает реагировать на внешние раздражители.
Это открытие означает, что свободное время, ничему конкретному не посвященное, — важный (и недоиспользованный) фактор развития инновационной мысли — и создания революционных инноваций. Тут, конечно, можно вспомнить Google, в которой программистам разрешают самостоятельно планировать рабочее время и 20% его тратить на свои проекты. Пример Google подхватили и другие. Консалтинговая фирма Maddock Douglas, которая помогает компаниям налаживать инновационную работу, предоставляет сотрудникам право от 100 до 200 часов в год заниматься тем, что интересно лично им. Персонал консалтинговой фирмы Bright-House может пять дней в году спокойно предаваться размышлениям или просто витать в эмпиреях. Сотрудникам Intuit 10% рабочего времени позволено тратить на неформализованные творческие задачи — по образу и подобию Google. В Twitter проводят так называемые Hack Weeks: в это время можно экспериментировать и разрабатывать идеи, не имеющие отношения к их основным обязанностям. А софтверная компании Atlassian устраивает ShipIt Days — 24-часовые хакатроны: в это время люди участвуют в любых интересующих их проектах фирмы и на следующий день должны «отгрузить» результаты.
Тут, конечно, можно вспомнить Google, в которой программистам разрешают самостоятельно планировать рабочее время и 20% его тратить на свои проекты. Пример Google подхватили и другие. Консалтинговая фирма Maddock Douglas, которая помогает компаниям налаживать инновационную работу, предоставляет сотрудникам право от 100 до 200 часов в год заниматься тем, что интересно лично им. Персонал консалтинговой фирмы Bright-House может пять дней в году спокойно предаваться размышлениям или просто витать в эмпиреях. Сотрудникам Intuit 10% рабочего времени позволено тратить на неформализованные творческие задачи — по образу и подобию Google. В Twitter проводят так называемые Hack Weeks: в это время можно экспериментировать и разрабатывать идеи, не имеющие отношения к их основным обязанностям. А софтверная компании Atlassian устраивает ShipIt Days — 24-часовые хакатроны: в это время люди участвуют в любых интересующих их проектах фирмы и на следующий день должны «отгрузить» результаты.
У таких программ, конечно, немало плюсов: известно, что, когда у людей есть свободное время для творчества, у них повышается профессиональная самооценка и мотивация, они чувствуют себя счастливее. Но открытия, связанные с сетью пассивного режима, заставляют усомниться в достаточности этих программ. Во-первых, обычно время сотрудников не вполне свободно. Предполагается все-таки, что они будут искать решение проблем, а это значит, что на их сети пассивного режима будут по-прежнему воздействовать внешние раздражители. Мозгу предстоит иметь дело с непосредственной реальностью.
Но открытия, связанные с сетью пассивного режима, заставляют усомниться в достаточности этих программ. Во-первых, обычно время сотрудников не вполне свободно. Предполагается все-таки, что они будут искать решение проблем, а это значит, что на их сети пассивного режима будут по-прежнему воздействовать внешние раздражители. Мозгу предстоит иметь дело с непосредственной реальностью.
Во-вторых, ключевым моментом таких программ оказывается количество предоставляемого людям свободного времени, хотя куда правильнее было бы обратить внимание на его качество. Можно было бы отключать электронную почту сотрудников, разрешать им отменять запланированные дела, отбирать у них телефоны, отправлять их в путешествия, подальше от работы и от коллег; освобождать от всех остальных должностных обязанностей. Надежный способ отвлечься от «жизни» — медитация. Важно, чтобы благодаря активности сети пассивного режима человек мог вообразить себе мысли других людей, в своих фантазиях перенестись в другое время и место, запустить поток свободных ассоциаций, не сдерживаемый сетями, которые обрабатывают информацию, поступающую из внешнего мира.
Если вдруг на вас снизошло озарение или решение проблемы пришло нежданно-негаданно, когда вы, вроде бы, и не думали о ней, это значит, что вы пожинаете плоды активности сети пассивного режима. Но, конечно, включать такие «отключения» в рабочий процесс трудно — не понятно, как оценивать итоги таких «уходов» (этим, вероятно, объясняется, что компании, у которых существуют программы свободного времени, ориентируются на конкретные параметры вроде доли рабочего времени или срока создания продукта). Тем не менее с полным отвлечением от рутины экспериментировать нужно, поскольку это — лучший способ получить прорывные идеи.
Как структурировать средства поощрения
Еще в начале ХХ века ученые мечтали о «гедонометре» — инструменте, которым измеряли бы уровень удовольствия или недовольства человека как реакцию на те или иные раздражители. Сейчас открытия нейробиологии показывают, что сети удовольствия отчасти и работают как гедонометр. Он активизируется, когда человек испытывает удовольствие, и выключается, когда что-нибудь этому удовольствию мешает.
Он активизируется, когда человек испытывает удовольствие, и выключается, когда что-нибудь этому удовольствию мешает.
Если вы думаете, что можно сканировать мозг человека и отмечать, какие, скажем, марки пива, Bud Light или Miller Lite, дают более высокие показатели на нашем«гедонометре», то вы сильно упрощаете дело. Радость и удовольствие зависят от ситуации, их интенсивность от каждого конкретного стимула может меняться, если накладываются другие стимулы. Возможно, пиву Bud Light вы радуетесь больше потому, что есть шанс получить его бесплатно, а Miller Lite — меньше из-за того, что не любите его в жестяных банках, но, если вам предложат этот же сорт в бутылке, уровень вашего удовольствия подскочит. А может быть, во время теста вам вообще не хотелось пива. К тому же — и мы подробнее остановимся на этом, когда будем говорить о сети контроля, — наш «гедонометр» — отнюдь не единственный арбитр в сфере поощрения и удовольствия.
Несколько десятилетий назад ученые с помощью электродов и других инвазивных методов обнаружили у животных то, что оказалось нейронными сетями удовольствия. Они активизировались, когда животным давали еду, воду или еще что-нибудь, необходимое для выживания. Но лишь в конце XX — начале XXI века нейробиологи и нейроэкономисты доказали, что у людей эти сети реагируют на поощрения вторичного порядка, те, которые могут и не иметь отношения к физическому выживанию. К ним, что особенно примечательно, относятся деньги.
Они активизировались, когда животным давали еду, воду или еще что-нибудь, необходимое для выживания. Но лишь в конце XX — начале XXI века нейробиологи и нейроэкономисты доказали, что у людей эти сети реагируют на поощрения вторичного порядка, те, которые могут и не иметь отношения к физическому выживанию. К ним, что особенно примечательно, относятся деньги.
Мы также установили, как наш «гедонометр» реагирует на вознаграждения и нематериального рода — и что они могут радовать людей не меньше, чем деньги. Эта идея перекликается с результатами опроса топ-менеджеров, проведенного в 2009 году McKinsey. Респонденты сообщали, что нематериальные стимулы важны для сотрудников не меньше финансовых, а иногда и больше.
Более того, сейчас мы можем определить, какие неденежные виды вознаграждения чаще всего приносят людям удовольствие. Некоторые вполне предсказуемы, например статус и общественное признание. Но есть и неожиданные. Скажем, справедливость. Исследования Джамилемя Заки из Стэнфорда и Джейсона Митчелла из Гарварда показали: когда у людей есть возможность разделить небольшую сумму денег между собой и другими, то их сеть удовольствия реагирует активнее, если они действуют справедливо. Ситуация же, поощряющая несправедливость, угнетает людей — если угодно, их «гедонометры» показывают более низкие значения. Несправедливость болезненно воспринимают даже те, кто принадлежит к привилегированной прослойке. Справедливость доставляет удовольствие всем, независимо от общественного и финансового положения.
Исследования Джамилемя Заки из Стэнфорда и Джейсона Митчелла из Гарварда показали: когда у людей есть возможность разделить небольшую сумму денег между собой и другими, то их сеть удовольствия реагирует активнее, если они действуют справедливо. Ситуация же, поощряющая несправедливость, угнетает людей — если угодно, их «гедонометры» показывают более низкие значения. Несправедливость болезненно воспринимают даже те, кто принадлежит к привилегированной прослойке. Справедливость доставляет удовольствие всем, независимо от общественного и финансового положения.
Это открытие означает, что компаниям, которые справедливо оплачивают труд сотрудников, стоило бы доводить это до их сведения. И наоборот: когда люде узнают о бешеных зарплатах топ-менеджеров, их сети удовольствия «отключаются». Но важна не только справедливая зарплата. Если, к примеру, людей не зовут на совещание по стратегии, хотя по своей квалификации они могли в нем участвовать, они теряют интерес к работе. Плохо также делить сотрудников на тех, кого допускают или не допускают к той или иной информации, так создается неравенство между осведомленными и непосвященными — вот почему так важна прозрачность.
Плохо также делить сотрудников на тех, кого допускают или не допускают к той или иной информации, так создается неравенство между осведомленными и непосвященными — вот почему так важна прозрачность.
Еще один активатор сети удовольствия — предвкушение от познания нового. Любознательность — сама по себе награда, в буквальном смысле. В ходе одного эксперимента, который проводили Колин Камерер из Калифорнийского технологического института и его коллеги, добровольцы читали вопросы викторины и оценивали, насколько им интересно получить ответ. Чем сильнее им хотелось узнать, в чем дело, тем сильнее активизировалась их сеть удовольствия.
Сеть удовольствия реагирует на цели, причем, по-видимому, куда более положительно на сформулированные не слишком жестко. Очень конкретные и труднодостижимые цели ставить вредно, так как они ослабляют любознательность и гибкость мышления.
Вот, например, что произошло в начале 2000-х в General Motors, когда компания поставила перед сотрудниками цель завоевать 29% автомобильного рынка США. GM вгрохала сумасшедшие деньги в рекламу и маркетинговые исследования — вместо того чтобы финансировать разработку инноваций. Подобные недальновидные стратегии обычно появляются в результате чересчур жестко сформулированных целей, а в результате под угрозой оказывается будущее благополучие бизнеса. Именно это произошло с GM: она оказалась на грани банкротства. Если бы задачу определили более обтекаемо — например: войти в первую десятку самых инновационных компаний, — это позволило бы GM решить много задач одновременно.
GM вгрохала сумасшедшие деньги в рекламу и маркетинговые исследования — вместо того чтобы финансировать разработку инноваций. Подобные недальновидные стратегии обычно появляются в результате чересчур жестко сформулированных целей, а в результате под угрозой оказывается будущее благополучие бизнеса. Именно это произошло с GM: она оказалась на грани банкротства. Если бы задачу определили более обтекаемо — например: войти в первую десятку самых инновационных компаний, — это позволило бы GM решить много задач одновременно.
Кроме того, данные нейробиологии указывают на то, что для мотивации фактор цели вовсе не обязателен. Скажем, работа над новой проблемой интересна сама по себе, и «гедонометр» мозга включается еще до того, как найдено решение или получено поощрение, финансовое или нет. Работа сама по себе может приносить такое же удовлетворение, как и вознаграждение. GM могла раскочегарить «гедонометры» своих сотрудников, просто поручив им интересные задачи и не оговаривая при этом, каких именно результатов от них ждут. Поскольку сильнее всего сеть удовольствия реагирует на нематериальные стимулы, напрашивается вывод, что деньги чаще всего — самый дорогой и неэффективный способ поощрения. И эмпирическое подтверждение этому уже найдено. Кау Мураяма из Калифорнийского университета и его бывшие коллеги из Мюнхенского в ходе одного исследования обнаружили, что если платить людям за чисто механическую работу — надо было останавливать секундомер каждые пять секунд, — то им уже не захочется выполнять задание бесплатно и, как следствие, активность сети удовольствия снизится. Все, что работодатель может сделать, не тратя денег, — поощрять справедливость и сотрудничество на работе, позволить людям проявлять любознательность и всячески удовлетворять их потребность в признании другими, — будет мотивировать сотрудников не меньше, чем деньги, а то и больше.
Поскольку сильнее всего сеть удовольствия реагирует на нематериальные стимулы, напрашивается вывод, что деньги чаще всего — самый дорогой и неэффективный способ поощрения. И эмпирическое подтверждение этому уже найдено. Кау Мураяма из Калифорнийского университета и его бывшие коллеги из Мюнхенского в ходе одного исследования обнаружили, что если платить людям за чисто механическую работу — надо было останавливать секундомер каждые пять секунд, — то им уже не захочется выполнять задание бесплатно и, как следствие, активность сети удовольствия снизится. Все, что работодатель может сделать, не тратя денег, — поощрять справедливость и сотрудничество на работе, позволить людям проявлять любознательность и всячески удовлетворять их потребность в признании другими, — будет мотивировать сотрудников не меньше, чем деньги, а то и больше.
Как пользоваться интуицией
Что важнее при принятии решения — интуиция или анализ? Это вечный вопрос. Но намного проще сказать, в какой мере можно доверять предчувствиям, если хотя бы в общих чертах представлять себе, откуда они берутся, почему мозг генерирует их и какую функцию выполняют «чувства».
Ученые уже поняли, как мозг формирует эмоциональные реакции, которые мы называем чувствами. События, происходящие в окружающей среде, вызывают физиологические изменения — артериального давления, пульса, температуры тела, — которые мозг затем интерпретирует в конкретном контексте. Какие-то события могут оказывать аффективное воздействие (удар током неприятен, по определению) или благодаря повторяющимся ассоциациям обладать эмоциональной ценностью (скажем, звук голоса коллеги, с которыми вы дружите, со временем начинает вызывать оживление). Эти чувства производит эмоциональная сеть, и она же, взаимодействуя с другими системами мозга, контролирует их интенсивность и определяет их вероятный источник.
Чувства могут быть побочным продуктом мыслей: вы вспоминаете, что надвигается срок сдачи работы, и чувствуете беспокойство; вы представляете себе хороший финансовый отчет — и радуетесь. Но чувства иногда возникают и бессознательно, так, что вы не знаете их причину. Предчувствие — вовсе не загадочное «шестое чувство». Это — реальная неврологическая реакция, которая проявляется физически.
Она «получается» так. По мере того как в мозг поступает информация о событиях, решениях и людях, он все это маркирует по эмоциональной значимости. Когда потом человек оказывается в аналогичной ситуации, мозг по этим маркировкам находит самый короткий путь к «нужным» чувствам — сомнению, тревоге, радости. Допустим, после того как вы отведали перец чили, вы не спали ночь, не в силах избавиться от жжения во рту. Позже при виде и запахе чили и даже упоминании о нем (или о ресторане, где вы его отведали) ваша сеть эмоций будет производить негативные чувства, повинуясь которым, вы, не рассуждая, не захотите снова пробовать перец.
Эти эмоции сопровождаются изменениями физического состояния: учащается пульс, выступает пот, вырабатываются кортизол и другие гормоны, кровь приливает к лицу, кожа покрывается мурашками. Все это обычно происходит помимо нашего сознания (см. врезку «Правда ли, что мозг успевает понять, что к чему, раньше нас?»).
Руководители обычно считают, что принимать решения надо с холодной головой, не поддаваясь чувствам. Но растет количество научных доказательств того, что эмоциональные порывы не стоит игнорировать. Сеть эмоций ускоряет процесс принятия решений и помогает обрабатывать информацию с большим количеством переменных.
Мы и сами получили экспериментальное тому подтверждение, изучая поведение людей, у которых были повреждены эмоциональные сети мозга. Лишившись направляющей функции чувств, они решения по всем вопросам, в том числе самые по самым обыденным, принимали на основании сложного анализа затрат и выгод.
Так что догадки — дело очень полезное. Надо ли всякий раз доверять предчувствиям? Вовсе нет. Бездумно следовать своей интуиции — умалять значимость здравого смысла и не учитывать важных «погрешностей» сети эмоций, например того, что продуцируемые ею чувства не точны. Они могут, что называется, не по делу совершенно завладеть человеком — особенно негативные, вроде страха или гнева. Легко ошибиться в определении причины предчувствия и понимании его значения. Мозг может «приписать» чувство ситуации, которая напоминает предыдущее событие, но на самом деле не повторяет его. Допустим, мы неудачно сделали презентацию и потому с ужасом ждем следующей, хотя уже лучше подготовились к ней. Но стоит вспомнить, сколько труда мы затратили на эту подготовку, и уже проще преодолеть страх.
И все же нейробиология эмоций убеждает нас в том, что при всей ненадежности интуиции к предчувствиям надо относиться внимательно. Прежде всего в ситуациях, связанных с риском: дурные предчувствия могли бы насторожить руководителей, поколебать их самоуверенность или заставить усомниться в адекватности чрезмерно оптимистичных решений. Имея дело с рынками, показателями и данными, руководители получают столько информации, что интуиция кажется чем-то непрактичным. Но она незаменима.
Прислушиваться к хорошим предчувствиям мы более или менее умеем, хотя и эту способность надо развивать. Мы можем, не имея полной информации, просто почувствовать, что не стоит выходить на тот или иной рынок. Но дурные предчувствия, особенно сомнения и тревогу, мы предпочитаем отгонять. Руководители пытаются заглушать их в себе — и в своих организациях. Это понятно: испытывая неуверенность и внутреннее смятение, мы выглядим слабыми; эти эмоции порождают ощущение неопределенности, а этого не любят ни рынки, ни сотрудники. Мы хотим, чтобы все были мотивированными, целеустремленными и уверенно продвигались вперед.
Но ведь отрицательные чувства, как и все остальные, — продукт сети эмоций, а значит, за ними стоит ценный прошлый опыт. Руководителям нельзя от них отмахиваться, наоборот, нужно стараться понять, откуда они взялись. Мы не предлагаем идти на поводу у сомнений и тревог, мы предлагаем прислушиваться к ним; если не избегать их, а оценивать, результаты будут лучше.
Как формулировать достижимые цели
Хотя многие привычные дела мы можем делать на автопилоте, мы обладаем еще и замечательной способностью противостоять своим привычкам и импульсам. Мы можем тысячу раз садиться во время совещаний на один и то же стул, а в тысячу первый взять другой. Ради более высокой должности мы по своей воле отправляемся на край света, в какое-нибудь унылое захолустье. Если животные реагируют только на насущные потребности, то мы можем стремиться и к более абстрактным целям, например завоевать бòльшую долю латиноамериканского рынка или полететь на Луну, причем даже тогда, когда они идут вразрез с нашими непосредственными нуждами или противоречат нашему опыту.
За эти возможности отвечает сеть контроля. Она согласовывает активность нашего мозга и наше поведение с нашими целями. Как гендиректор может перебросить ресурсы фирмы с рухнувшего рынка на растущий, так и сеть контроля может перенаправить кровоток от участков мозга, подающих конкурирующие или неуместные сигналы к участкам мозга, которые помогают нам выполнять наши задачи. Генеральные директора могут проводить ревизию ресурсов и по-новому размещать их каждый бюджетный цикл, а сеть контроля делает это постоянно, по мере того как изменяются наши обстоятельства, формируются наши потребности и желания.
Мы намеренно спланировали свою статью так, чтобы начать с сети пассивного режима и закончить сетью контроля. Наука говорит, что это по сути взаимоисключающие силы. Чем активнее сеть контроля распределяет ресурсы ради решения задач, навязываемых внешним миром, тем меньше дел у сети пассивного режима, ведь человеку не надо отвлекаться от реального мира и переноситься в воображаемый. И наоборот.
Можно сказать, что задача сети контроля — приглядывать за всеми остальными сетями мозга. Подавляя сеть пассивного режима, она не дает нам постоянно витать в облаках. Сдерживая сеть удовольствия, она помогает нам не поддаваться соблазнам и не потакать своим слабостям, не действовать импульсивно и отказываться от сиюминутных потребностей ради более важных долгосрочных. Регулируя сеть эмоций, она обуздывает наши эмоциональные реакции, чтобы наши поступки не были продиктованы исключительно преходящими чувствами или наитием.
Кроме того, эта сеть помогает нам ориентироваться в множестве обрушивающихся на нас дел. Когда вокруг без конца звякают смс или сообщения о поступивших электронных письмах, жужжат виброзвонки телефонов и кто-нибудь претендует на наше время, нам надо уметь выделять главное и не отвлекаться на остальное.
Конечно, все не так просто. Полностью уходить в работу так же опасно, как полностью отключаться от реальности или всегда действовать по первому побуждению. В таком состоянии мы упускаем полезные для нас изменения окружающей обстановки. Если футболист зациклен на желании нанести решающий удар по воротам противника, он может и не заметить, что его товарищ по команде находится в лучшей позиции для того, чтобы забить гол, — нужно только передать ему мяч. Кроме того, игрок может забыть о том, что время матча истекает, то есть, будучи одержимым идеей гола, упустить другой, но более важный момент. С этой хитрой задачей управления вниманием как раз и имеет дело сеть контроля. С одной стороны, ей надо, чтобы мы не отвлекались на все, что блестит в поле нашего зрения. С другой — ей надо, чтобы мы реагировали, если одна из этих блестящих штуковин открывает нам новые перспективы или связана с важной потребностью.
Чтобы иметь возможность решать две эти параллельные задачи, сеть контроля себя подстраховывает. Она настраивает мозг так, чтобы реагировать на информацию, которая относится и к нашему нынешнему делу, и к нашим большим целям (то есть реагировать мы должны не на все стимулы, а на связанные с целями). Чтобы поддерживать нас в этом маневренном состоянии, сеть контроля стремится к золотой середине: она склоняет чашу весов в пользу действий, совместимых с нашими целями, но не до такой степени, чтобы мы направили на них все свои ресурсы. Это дает нам гибкость в непредвиденных обстоятельствах, но в то же время заставляет то и дело отвлекаться. Далеко не каждый игрок, мчащийся по футбольному полю, готов принять пас и находится в удобном месте для удара по воротам, и вовсе незачем нам каждую секунду смотреть на часы, проверяя, осталось ли еще время для гола.
Последние открытия, связанные с сетью контроля, подтверждают то, что лучшие из руководителей говорят о конкуренции: чтобы обойти соперников, не надо распыляться — важно разумно ограничить количество стратегических инициатив, иначе их будет невозможно реализовать. Когда людей заставляют заниматься сразу несколькими задачами, их внимание рассеивается и им становится трудно делать любую работу, требующую сосредоточенности, сети контроля не хватает ресурсов и нам не удается ни одному из своих дел уделить должное внимание.
Некоторые полагают, что делать несколько дел сразу полезно — это, мол, делает ум более гибким. Но научные факты, и их становится все больше, заставляют усомниться в этом. Одно из недавних исследований Эйяла Офира, Клиффорда Нэсса и Энтони Вагнера показало, что сети контроля хронически перегруженных людей не могут отфильтровывать ненужную информацию. Таким людям не удавалось не думать о делах, которые они не делали. Какой смысл думать о том, что надо перезвонить клиенту или что на телефоне «висят» неотвеченные письма и твиты, если в данный момент вы обсуждаете с генеральным корпоративную стратегию? Мало того, что эти дела никак не связаны с вашей беседой, сейчас вы все равно не можете ими заняться.
В подтверждение того, что дела, которые мы не делаем, могут легко и полностью захватить наше внимание, подавляющее большинство из 40 опрошенных нами недавно топ-менеджеров сообщили: в «свободные» моменты они почти всегда думают о незавершенных делах. То, что наш мозг способен расставлять невыполненные задачи в порядке значимости, для нас — благо. И в то же время — проклятье.
Электронные письма, совещания, тексты, твиты, телефонные звонки — нынешняя работа, неструктурированная, нескончаемая, многосоставная, страшным бременем давит на сети контроля и поглощает невероятное количество энергии мозга. Отсюда умственная усталость, которая дает о себе знать в виде ошибок, невозможности «зрить в корень», ослабленной саморегуляции. При перегрузке сеть контроля выпускает бразды правления и наше поведение перестает соответствовать расставленным в уме приоритетам, над нами берут верх сиюминутные, ситуационные стимулы. Мы живем на автопилоте, и наш мозг «сдается» — он лишь реагирует на то, что у нас под носом, неважно, насколько это важно.
Чтобы грамотно руководить, надо прежде всего сформулировать несколько — ограниченное количество — первостепенных задач и, набравшись решимости, отменить или препоручить кому-нибудь все менее значимое. Кроме того, топ-менеджерам стоит подумать, насколько реалистично они представляют себе посильную рабочую нагрузку, учитывая возможности своего мозга. Этот «воз» меньше того, что большинство из нас пытается на себе везти.
Информацию о работе сети контроля стоило бы учитывать и в развитии концепции бережливой работы. «Бережливость» не означает, что надо взвалить на нескольких сотрудников основную массу работы. Чем больше дел поручают людям, тем хуже они справляются. Если ориентироваться на относительно короткий период, то, может быть, и выгодно не раздувать штат и держать сотрудников в черном теле. Но наука о мозге напоминает, что многих профессионалов уже давно заставили зайти далеко за ту грань, где задания еще выполнимы, а цели достижимы.
После того как в начале 2000-х ведущие журналы стали публиковать многочисленные статьи о нейровизуалистических исследованиях (некоторые ученые называют это время «Диким Западом нейробиологии»), критики быстро окрестили эту область знания новой френологией, имея в виду псевдоученого XVIII столетия Франца Йозефа Галля, который особенности психики связывал со строением черепа. Но нейробиология, развиваясь, обещает стать научно обоснованным и куда более сложным вариантом френологии.
Если мы хотим избавиться от ошибок прошедшего десятилетия, нам нужно соблюдать осторожность в интерпретации. И все же сейчас у нейробиологии самое интересное время, и оно обещает много новых открытий для бизнеса. К примеру, появилась методика гиперсканирования, позволяющая наблюдать за работой мозга двух людей в процессе их общения: она откроет путь к истинному сотрудничеству и обмену информацией. Новаторские исследования в области геномики мозга доказывают, что люди предрасположены к своим самым разным качествам, от понятливости до импульсивности. Наконец, нейробиологи пытаются понять, как принятие решений, способность к общению, когнитивный контроль, эмоции и другие функции изменяются на протяжении жизни. Все эти достижения подготавливают почву для в высшей степени плодотворного диалога между наукой и бизнесом.
что это такое и как работает. Как создать нейронную сеть без навыков программирования
Мое знакомство с нейронными сетями произошло, когда вышло приложение Prisma. Оно обрабатывает любую фотографию, с помощью нейронных сетей, и воспроизводит ее с нуля, используя выбранный стиль. Заинтересовавшись этим, я бросился искать статьи и «туториалы», в первую очередь, на Хабре. И к моему великому удивлению, я не нашел ни одну статью, которая четко и поэтапно расписывала алгоритм работы нейронных сетей. Информация была разрознена и в ней отсутствовали ключевые моменты. Также, большинство авторов бросается показывать код на том или ином языке программирования, не прибегая к детальным объяснениям.
П ервым и самым важным моим открытием был плейлист американского программиста Джеффа Хитона, в котором он подробно и наглядно разбирает принципы работы нейронных сетей и их классификации. После просмотра этого плейлиста, я решил создать свою нейронную сеть, начав с самого простого примера. Вам наверняка известно, что когда ты только начинаешь учить новый язык, первой твоей программой будет Hello World. Это своего рода традиция. В мире машинного обучения тоже есть свой Hello world и это нейросеть решающая проблему исключающего или(XOR). Таблица исключающего или выглядит следующим образом:
Соответственно, нейронная сеть берет на вход два числа и должна на выходе дать другое число — ответ. Теперь о самих нейронных сетях.
Что такое нейронная сеть?
Нейронная сеть — это последовательность нейронов, соединенных между собой синапсами. Структура нейронной сети пришла в мир программирования прямиком из биологии. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Нейронные сети также способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти. Заинтересовавшимся обязательно к просмотру 2 видео из TED Talks: Видео 1 , Видео 2 ). Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Какие бывают нейронные сети?
Пока что мы будем рассматривать примеры на самом базовом типе нейронных сетей — это сеть прямого распространения (далее СПР). Также в последующих статьях я введу больше понятий и расскажу вам о рекуррентных нейронных сетях. СПР как вытекает из названия это сеть с последовательным соединением нейронных слоев, в ней информация всегда идет только в одном направлении.
Для чего нужны нейронные сети?
Нейронные сети используются для решения сложных задач, которые требуют аналитических вычислений подобных тем, что делает человеческий мозг. Самыми распространенными применениями нейронных сетей является:
Классификация — распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд.
Предсказание — возможность предсказывать следующий шаг. Например, рост или падение акций, основываясь на ситуации на фондовом рынке.
Распознавание — в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое.
Теперь, чтобы понять, как же работают нейронные сети, давайте взглянем на ее составляющие и их параметры.
Что такое нейрон?
Нейрон — это вычислительная единица, которая получает информацию, производит над ней простые вычисления и передает ее дальше. Они делятся на три основных типа: входной (синий), скрытый (красный) и выходной (зеленый). Также есть нейрон смещения и контекстный нейрон о которых мы поговорим в следующей статье. В том случае, когда нейросеть состоит из большого количества нейронов, вводят термин слоя. Соответственно, есть входной слой, который получает информацию, n скрытых слоев (обычно их не больше 3), которые ее обрабатывают и выходной слой, который выводит результат. У каждого из нейронов есть 2 основных параметра: входные данные (input data) и выходные данные (output data). В случае входного нейрона: input=output. В остальных, в поле input попадает суммарная информация всех нейронов с предыдущего слоя, после чего, она нормализуется, с помощью функции активации (пока что просто представим ее f(x)) и попадает в поле output.
Важно помнить , что нейроны оперируют числами в диапазоне или [-1,1]. А как же, вы спросите, тогда обрабатывать числа, которые выходят из данного диапазона? На данном этапе, самый простой ответ — это разделить 1 на это число. Этот процесс называется нормализацией, и он очень часто используется в нейронных сетях. Подробнее об этом чуть позже.
Что такое синапс?
Синапс это связь между двумя нейронами. У синапсов есть 1 параметр — вес. Благодаря ему, входная информация изменяется, когда передается от одного нейрона к другому. Допустим, есть 3 нейрона, которые передают информацию следующему. Тогда у нас есть 3 веса, соответствующие каждому из этих нейронов. У того нейрона, у которого вес будет больше, та информация и будет доминирующей в следующем нейроне (пример — смешение цветов). На самом деле, совокупность весов нейронной сети или матрица весов — это своеобразный мозг всей системы. Именно благодаря этим весам, входная информация обрабатывается и превращается в результат.
Важно помнить , что во время инициализации нейронной сети, веса расставляются в случайном порядке.
Как работает нейронная сеть?
В данном примере изображена часть нейронной сети, где буквами I обозначены входные нейроны, буквой H — скрытый нейрон, а буквой w — веса. Из формулы видно, что входная информация — это сумма всех входных данных, умноженных на соответствующие им веса. Тогда дадим на вход 1 и 0. Пусть w1=0.4 и w2 = 0.7 Входные данные нейрона Н1 будут следующими: 1*0.4+0*0.7=0.4. Теперь когда у нас есть входные данные, мы можем получить выходные данные, подставив входное значение в функцию активации (подробнее о ней далее). Теперь, когда у нас есть выходные данные, мы передаем их дальше. И так, мы повторяем для всех слоев, пока не дойдем до выходного нейрона. Запустив такую сеть в первый раз мы увидим, что ответ далек от правильно, потому что сеть не натренирована. Чтобы улучшить результаты мы будем ее тренировать. Но прежде чем узнать как это делать, давайте введем несколько терминов и свойств нейронной сети.
Функция активации
Функция активации — это способ нормализации входных данных (мы уже говорили об этом ранее). То есть, если на входе у вас будет большое число, пропустив его через функцию активации, вы получите выход в нужном вам диапазоне. Функций активации достаточно много поэтому мы рассмотрим самые основные: Линейная, Сигмоид (Логистическая) и Гиперболический тангенс. Главные их отличия — это диапазон значений.
Линейная функция
Эта функция почти никогда не используется, за исключением случаев, когда нужно протестировать нейронную сеть или передать значение без преобразований.
Сигмоид
Это самая распространенная функция активации, ее диапазон значений . Именно на ней показано большинство примеров в сети, также ее иногда называют логистической функцией. Соответственно, если в вашем случае присутствуют отрицательные значения (например, акции могут идти не только вверх, но и вниз), то вам понадобиться функция которая захватывает и отрицательные значения.
Гиперболический тангенс
Имеет смысл использовать гиперболический тангенс, только тогда, когда ваши значения могут быть и отрицательными, и положительными, так как диапазон функции [-1,1]. Использовать эту функцию только с положительными значениями нецелесообразно так как это значительно ухудшит результаты вашей нейросети.
Тренировочный сет
Тренировочный сет — это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключающего или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.
Итерация
Это своеобразный счетчик, который увеличивается каждый раз, когда нейронная сеть проходит один тренировочный сет. Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.
Эпоха
При инициализации нейронной сети эта величина устанавливается в 0 и имеет потолок, задаваемый вручную. Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат. Эпоха увеличивается каждый раз, когда мы проходим весь набор тренировочных сетов, в нашем случае, 4 сетов или 4 итераций.
Важно не путать итерацию с эпохой и понимать последовательность их инкремента. Сначала n раз увеличивается итерация, а потом уже эпоха и никак не наоборот. Другими словами, нельзя сначала тренировать нейросеть только на одном сете, потом на другом и тд. Нужно тренировать каждый сет один раз за эпоху. Так, вы сможете избежать ошибок в вычислениях.
Ошибка
Ошибка — это процентная величина, отражающая расхождение между ожидаемым и полученным ответами. Ошибка формируется каждую эпоху и должна идти на спад. Если этого не происходит, значит, вы что-то делаете не так. Ошибку можно вычислить разными путями, но мы рассмотрим лишь три основных способа: Mean Squared Error (далее MSE), Root MSE и Arctan. Здесь нет какого-либо ограничения на использование, как в функции активации, и вы вольны выбрать любой метод, который будет приносить вам наилучший результат. Стоит лишь учитывать, что каждый метод считает ошибки по разному. У Arctan, ошибка, почти всегда, будет больше, так как он работает по принципу: чем больше разница, тем больше ошибка. У Root MSE будет наименьшая ошибка, поэтому, чаще всего, используют MSE, которая сохраняет баланс в вычислении ошибки.
Root MSE
Arctan
Принцип подсчета ошибки во всех случаях одинаков. За каждый сет, мы считаем ошибку, отняв от идеального ответа, полученный.2)/1=0.45
Результат — 0.33, ошибка — 45%.
Большое спасибо за внимание! Надеюсь, что данная статья смогла помочь вам в изучении нейронных сетей. В следующей статье, я расскажу о нейронах смещения и о том, как тренировать нейронную сеть, используя метод обратного распространения и градиентного спуска.
Использованные ресурсы:
За последнюю пару лет искусственный интеллект незаметно отряхнулся от тегов «фантастика» и «геймдизайн» и прочно прописался в ежедневных новостных лентах. Сущности под таинственным названием «нейросети» опознают людей по фотографиям, водят автомобили, играют в покер и совершают научные открытия. При этом из новостей не всегда понятно, что же такое эти загадочные нейросети: сложные программы, особые компьютеры или стойки со стройными рядами серверов?
Конечно, уже из названия можно догадаться, что в нейросетях разработчики попытались скопировать устройство человеческого мозга: как известно, он состоит из множества простых клеток-нейронов, которые обмениваются друг с другом электрическими сигналами. Но чем тогда нейросети отличаются от обычного компьютера, который тоже собран из примитивных электрических деталей? И почему до современного подхода не додумались ещё полвека назад?
Давайте попробуем разобраться, что же кроется за словом «нейросети», откуда они взялись — и правда ли, что компьютеры прямо на наших глазах постепенно обретают разум.
Идея нейросети заключается в том, чтобы собрать сложную структуру из очень простых элементов. Вряд ли можно считать разумным один-единственный участок мозга — а вот люди обычно на удивление неплохо проходят тест на IQ. Тем не менее до сих пор идею создания разума «из ничего» обычно высмеивали: шутке про тысячу обезьян с печатными машинками уже сотня лет, а при желании критику нейросетей можно найти даже у Цицерона, который ехидно предлагал до посинения подбрасывать в воздух жетоны с буквами, чтобы рано или поздно получился осмысленный текст. Однако в XXI веке оказалось, что классики ехидничали зря: именно армия обезьян с жетонами может при должном упорстве захватить мир.
На самом деле нейросеть можно собрать даже из спичечных коробков: это просто набор нехитрых правил, по которым обрабатывается информация. «Искусственным нейроном», или перцептроном , называется не какой-то особый прибор, а всего лишь несколько арифметических действий.
Работает перцептрон проще некуда: он получает несколько исходных чисел, умножает каждое на «ценность» этого числа (о ней чуть ниже), складывает и в зависимости от результата выдаёт 1 или –1. Например, мы фотографируем чистое поле и показываем нашему нейрону какую-нибудь точку на этой картинке — то есть посылаем ему в качестве двух сигналов случайные координаты. А затем спрашиваем: «Дорогой нейрон, здесь небо или земля?» — «Минус один, — отвечает болванчик, безмятежно разглядывая кучевое облако. — Ясно же, что земля».
«Тыкать пальцем в небо» — это и есть основное занятие перцептрона. Никакой точности от него ждать не приходится: с тем же успехом можно подбросить монетку. Магия начинается на следующей стадии, которая называется машинным обучением . Мы ведь знаем правильный ответ — а значит, можем записать его в свою программу. Вот и получается, что за каждую неверную догадку перцептрон в буквальном смысле получает штраф, а за верную — премию: «ценность» входящих сигналов вырастает или уменьшается. После этого программа прогоняется уже по новой формуле. Рано или поздно нейрон неизбежно «поймёт», что земля на фотографии снизу, а небо сверху, — то есть попросту начнёт игнорировать сигнал от того канала, по которому ему передают x-координаты. Если такому умудрённому опытом роботу подсунуть другую фотографию, то линию горизонта он, может, и не найдёт, но верх с низом уже точно не перепутает.
Чтобы нарисовать прямую линию, нейрон исчеркает весь лист
В реальной работе формулы немного сложнее, но принцип остаётся тем же. Перцептрон умеет выполнять только одну задачу: брать числа и раскладывать по двум стопкам. Самое интересное начинается тогда, когда таких элементов несколько, ведь входящие числа могут быть сигналами от других «кирпичиков»! Скажем, один нейрон будет пытаться отличить синие пиксели от зелёных, второй продолжит возиться с координатами, а третий попробует рассудить, у кого из этих двоих результаты ближе к истине. Если же натравить на синие пиксели сразу несколько нейронов и суммировать их результаты, то получится уже целый слой, в котором «лучшие ученики» будут получать дополнительные премии. Таким образом достаточно развесистая сеть может перелопатить целую гору данных и учесть при этом все свои ошибки.
Перцептроны устроены не намного сложнее, чем любые другие элементы компьютера, которые обмениваются единицами и нулями. Неудивительно, что первый прибор, устроенный по принципу нейросети — Mark I Perceptron, — появился уже в 1958 году, всего через десятилетие после первых компьютеров. Как было заведено в ту эпоху, нейроны у этого громоздкого устройства состояли не из строчек кода, а из радиоламп и резисторов. Учёный Фрэнк Розенблатт смог соорудить только два слоя нейросети, а сигналы на «Марк-1» подавались с импровизированного экрана размером в целых 400 точек. Устройство довольно быстро научилось распознавать простые геометрические формы — а значит, рано или поздно подобный компьютер можно было обучить, например, чтению букв.
Розенблатт и его перцептрон
Розенблатт был пламенным энтузиастом своего дела: он прекрасно разбирался в нейрофизиологии и вёл в Корнеллском университете популярнейший курс лекций, на котором подробно объяснял всем желающим, как с помощью техники воспроизводить принципы работы мозга. Учёный надеялся, что уже через несколько лет перцептроны превратятся в полноценных разумных роботов: они смогут ходить, разговаривать, создавать себе подобных и даже колонизировать другие планеты. Энтузиазм Розенблатта вполне можно понять: тогда учёные ещё верили, что для создания ИИ достаточно воспроизвести на компьютере полный набор операций математической логики. Тьюринг уже предложил свой знаменитый тест, Айзек Азимов призывал задуматься о необходимости законов роботехники, а освоение Вселенной казалось делом недалёкого будущего.
Впрочем, были среди пионеров кибернетики и неисправимые скептики, самым грозным из которых оказался бывший однокурсник Розенблатта, Марвин Минский. Этот учёный обладал не менее громкой репутацией: тот же Азимов отзывался о нём с неизменным уважением, а Стэнли Кубрик приглашал в качестве консультанта на съёмки «Космической одиссеи 2001 года». Даже по работе Кубрика видно, что на самом деле Минский ничего не имел против нейросетей: HAL 9000 состоит именно из отдельных логических узлов, которые работают в связке друг с другом. Минский и сам увлекался машинным обучением ещё в 1950-х. Просто Марвин непримиримо относился к научным ошибкам и беспочвенным надеждам: недаром именно в его честь Дуглас Адамс назвал своего андроида-пессимиста.
В отличие от Розенблатта, Минский дожил до триумфа ИИ
Сомнения скептиков того времени Минский подытожил в книге «Перцептрон» (1969), которая надолго отбила у научного сообщества интерес к нейросетям. Минский математически доказал, что у «Марка-1» есть два серьёзных изъяна. Во-первых, сеть всего с двумя слоями почти ничего не умела — а ведь это и так уже был огромный шкаф, пожирающий уйму электричества. Во-вторых, для многослойных сетей алгоритмы Розенблатта не годились: по его формуле часть сведений об ошибках сети могла потеряться, так и не дойдя до нужного слоя.
Минский не собирался сильно критиковать коллегу: он просто честно отметил сильные и слабые стороны его проекта, а сам продолжил заниматься своими разработками. Увы, в 1971 году Розенблатт погиб — исправлять ошибки перцептрона оказалось некому. «Обычные» компьютеры в 1970-х развивались семимильными шагами, поэтому после книги Минского исследователи попросту махнули рукой на искусственные нейроны и занялись более перспективными направлениями.
Развитие нейросетей остановилось на десять с лишним лет — сейчас эти годы называют «зимой искусственного интеллекта». К началу эпохи киберпанка математики наконец-то придумали более подходящие формулы для расчёта ошибок, но научное сообщество поначалу не обратило внимания на эти исследования. Только в 1986 году, когда уже третья подряд группа учёных независимо от других решила обнаруженную Минским проблему обучения многослойных сетей, работа над искусственным интеллектом наконец-то закипела с новой силой.
Хотя правила работы остались прежними, вывеска сменилась: теперь речь шла уже не о «перцептронах», а о «когнитивных вычислениях». Экспериментальных приборов никто уже не строил: теперь все нужные формулы проще было записать в виде несложного кода на обычном компьютере, а потом зациклить программу. Буквально за пару лет нейроны научились собирать в сложные структуры. Например, некоторые слои искали на изображении конкретные геометрические фигуры, а другие суммировали полученные данные. Именно так удалось научить компьютеры читать человеческий почерк. Вскоре стали появляться даже самообучающиеся сети, которые не получали «правильные ответы» от людей, а находили их сами. Нейросети сразу начали использовать и на практике: программу, которая распознавала цифры на чеках, с удовольствием взяли на вооружение американские банки.
1993 год: капча уже морально устарела
К середине 1990-х исследователи сошлись на том, что самое полезное свойство нейросетей — их способность самостоятельно придумывать верные решения. Метод проб и ошибок позволяет программе самой выработать для себя правила поведения. Именно тогда стали входить в моду соревнования самодельных роботов, которых программировали и обучали конструкторы-энтузиасты. А в 1997 году суперкомпьютер Deep Blue потряс любителей шахмат, обыграв чемпиона мира Гарри Каспарова.
Строго говоря, Deep Blue не учился на своих ошибках, а попросту перебирал миллионы комбинаций
Увы, примерно в те же годы нейросети упёрлись в потолок возможностей. Другие области программирования не стояли на месте — вскоре оказалось, что с теми же задачами куда проще справляются обычные продуманные и оптимизированные алгоритмы. Автоматическое распознавание текста сильно упростило жизнь работникам архивов и интернет-пиратам, роботы продолжали умнеть, но разговоры об искусственном интеллекте потихоньку заглохли. Для действительно сложных задач нейросетям по-прежнему не хватало вычислительной мощности.
Вторая «оттепель» ИИ случилась, только когда изменилась сама философия программирования.
В последнее десятилетие программисты — да и простые пользователи — часто жалуются, что никто больше не обращает внимания на оптимизацию. Раньше код сокращали как могли — лишь бы программа работала быстрее и занимала меньше памяти. Теперь даже простейший интернет-сайт норовит подгрести под себя всю память и обвешаться «библиотеками» для красивой анимации.
Конечно, для обычных программ это серьёзная проблема, — но как раз такого изобилия и не хватало нейросетям! Учёным давно известно, что если не экономить ресурсы, самые сложные задачи начинают решаться словно бы сами собой. Ведь именно так действуют все законы природы, от квантовой физики до эволюции: если повторять раз за разом бесчисленные случайные события, отбирая самые стабильные варианты, то из хаоса родится стройная и упорядоченная система. Теперь в руках человечества наконец-то оказался инструмент, который позволяет не ждать изменений миллиарды лет, а обучать сложные системы буквально на ходу.
В последние годы никакой революции в программировании не случилось — просто компьютеры накопили столько вычислительной мощности, что теперь любой ноутбук может взять сотню нейронов и прогнать каждый из них через миллион циклов обучения. Оказалось, что тысяче обезьян с пишущими машинками просто нужен очень терпеливый надсмотрщик, который будет выдавать им бананы за правильно напечатанные буквы, — тогда зверушки не только скопируют «Войну и мир», но и напишут пару новых романов не хуже.
Так и произошло третье пришествие перцептронов — на этот раз уже под знакомыми нам названиями «нейросети» и «глубинное обучение». Неудивительно, что новостями об успехах ИИ чаще всего делятся такие крупные корпорации как Google и IBM. Их главный ресурс — огромные дата-центры, где на мощных серверах можно тренировать многослойные нейросети. Эпоха машинного обучения по-настоящему началась именно сейчас, потому что в интернете и соцсетях наконец-то накопились те самые big data, то есть гигантские массивы информации, которые и скармливают нейросетям для обучения.
В итоге современные сети занимаются теми трудоёмкими задачами, на которые людям попросту не хватило бы жизни. Например, для поиска новых лекарств учёным до сих пор приходилось долго высчитывать, какие химические соединения стоит протестировать. А сейчас существует нейросеть, которая попросту перебирает все возможные комбинации веществ и предлагает наиболее перспективные направления исследований. Компьютер IBM Watson успешно помогает врачам в диагностике: обучившись на историях болезней, он легко находит в данных новых пациентов неочевидные закономерности.
Люди классифицируют информацию с помощью таблиц, но нейросетям незачем ограничивать себя двумя измерениями — поэтому массивы данных выглядят примерно так
В сфере развлечений компьютеры продвинулись не хуже, чем в науке. За счёт машинного обучения им наконец поддались игры, алгоритмы выигрыша для которых придумать ещё сложнее, чем для шахмат. Недавно нейросеть AlphaGo разгромила одного из лучших в мире игроков в го, а программа Libratus победила в профессиональном турнире по покеру. Более того, ИИ уже постепенно пробирается и в кино: например, создатели сериала «Карточный домик» использовали big data при кастинге, чтобы подобрать максимально популярный актёрский состав.
Как и полвека назад, самым перспективным направлением остаётся распознание образов. Рукописный текст или «капча» давно уже не проблема — теперь сети успешно различают людей по фотографиям, учатся определять выражения лиц, сами рисуют котиков и сюрреалистические картины. Сейчас основную практическую пользу из этих развлечений извлекают разработчики беспилотных автомобилей — ведь чтобы оценить ситуацию на дороге, машине нужно очень быстро и точно распознать окружающие предметы. Не отстают и спецслужбы с маркетологами: по обычной записи видеонаблюдения нейронная сеть давно уже может отыскать человека в соцсетях. Поэтому особо недоверчивые заводят себе специальные камуфляжные очки, которые могут обмануть программу.
«Ты всего лишь машина. Только имитация жизни. Разве робот сочинит симфонию? Разве робот превратит кусок холста в шедевр искусства?» («Я, робот»)
Наконец, начинает сбываться и предсказание Розенблатта о самокопирующихся роботах: недавно нейросеть DeepCoder обучили программированию. На самом деле программа пока что просто заимствует куски чужого кода, да и писать умеет только самые примитивные функции. Но разве не с простейшей формулы началась история самих сетей?
Игры с ботами
Развлекаться с недоученными нейросетями очень весело: они порой выдают такие ошибки, что в страшном сне не приснится. А если ИИ начинает учиться, появляется азарт: «Неужто сумеет?» Поэтому сейчас набирают популярность интернет-игры с нейросетями.
Одним из первых прославился интернет-джинн Акинатор , который за несколько наводящих вопросов угадывал любого персонажа. Строго говоря, это не совсем нейросеть, а несложный алгоритм, но со временем он становился всё догадливее. Джинн пополнял базу данных за счёт самих пользователей — и в результате его обучили даже интернет-мемам.
Другое развлечение с «угадайкой» предлагает ИИ от Google : нужно накалякать за двадцать секунд рисунок к заданному слову, а нейросеть потом пробует угадать, что это было. Программа очень смешно промахивается, но порой для верного ответа хватает всего пары линий — а ведь именно так узнаём объекты и мы сами.
Ну и, конечно, в интернете не обойтись без котиков. Программисты взяли вполне серьёзную нейросеть, которая умеет строить проекты фасадов или угадывать цвет на чёрно-белых фотографиях, и обучили её на кошках — чтобы она пыталась превратить любой контур в полноценную кошачью фотографию . Поскольку проделать это ИИ старается даже с квадратом, результат порой достоин пера Лавкрафта!
При таком обилии удивительных новостей может показаться, что искусственный интеллект вот-вот осознает себя и сумеет решить любую задачу. На самом деле не так всё радужно — или, если встать на сторону человечества, не так мрачно. Несмотря на успехи нейросетей, у них накопилось столько проблем, что впереди нас вполне может ждать очередная «зима».
Главная слабость нейросетей в том, что каждая из них заточена под определённую задачу. Если натренировать сеть на фотографиях с котиками, а потом предложить ей задачку «отличи небо от земли», программа не справится, будь в ней хоть миллиард нейронов. Чтобы появились по-настоящему «умные» компьютеры, надо придумать новый алгоритм, объединяющий уже не нейроны, а целые сети, каждая из которых занимается конкретной задачей. Но даже тогда до человеческого мозга компьютерам будет далеко.
Сейчас самой крупной сетью располагает компания Digital Reasoning (хотя новые рекорды появляются чуть ли не каждый месяц) — в их творении 160 миллиардов элементов. Для сравнения: в одном кубическом миллиметре мышиного мозга около миллиарда связей. Причём биологам пока удалось описать от силы участок в пару сотен микрометров, где нашлось около десятка тысяч связей. Что уж говорить о людях!
Один слой умеет узнавать людей, другой — столы, третий — ножи…
Такими 3D-моделями модно иллюстрировать новости о нейросетях, но это всего лишь крошечный участок мышиного мозга
Кроме того, исследователи советуют осторожнее относиться к громким заявлениям Google и IBM. Никаких принципиальных прорывов в «когнитивных вычислениях» с 1980-х годов не произошло: компьютеры всё так же механически обсчитывают входящие данные и выдают результат. Нейросеть способна найти закономерность, которую не заметит человек, — но эта закономерность может оказаться случайной. Машина может подсчитать, сколько раз в твиттере упоминается «Оскар», — но не сможет определить, радуются пользователи результатам или ехидничают над выбором киноакадемии.
Теоретики искусственного интеллекта настаивают, что одну из главных проблем — понимание человеческого языка — невозможно решить простым перебором ключевых слов. А именно такой подход до сих пор используют даже самые продвинутые нейросети.
Сказки про Скайнет
Хотя нам самим сложно удержаться от иронии на тему бунта роботов, серьёзных учёных не стоит даже и спрашивать о сценариях из «Матрицы» или «Терминатора»: это всё равно что поинтересоваться у астронома, видел ли он НЛО. Исследователь искусственного интеллекта Элиезер Юдковски, известный по роману « », написал ряд статей, где объяснил, почему мы так волнуемся из-за восстания машин — и чего стоит опасаться на самом деле.
Прежде всего, «Скайнет» приводят в пример так, словно мы уже пережили эту историю и боимся повторения. А всё потому, что наш мозг не умеет отличать выдумки с киноэкранов от жизненного опыта. На самом-то деле роботы никогда не бунтовали против своей программы, и попаданцы не прилетали из будущего. С чего мы вообще взяли, что это реальный риск?
Бояться надо не врагов, а чересчур усердных друзей. У любой нейросети есть мотивация: если ИИ должен гнуть скрепки, то, чем больше он их сделает, тем больше получит «награды». Если дать хорошо оптимизированному ИИ слишком много ресурсов, он не задумываясь переплавит на скрепки всё окрестное железо, потом людей, Землю и всю Вселенную. Звучит безумно — но только на человеческий вкус! Так что главная задача будущих создателей ИИ — написать такой жёсткий этический кодекс, чтобы даже существо с безграничным воображением не смогло найти в нём «дырок».
* * *
Итак, до настоящего искусственного интеллекта пока ещё далеко. С одной стороны над этой проблемой по-прежнему бьются нейробиологи, которые ещё до конца не понимают, как же устроено наше сознание. С другой наступают программисты, которые попросту берут задачу штурмом, бросая на обучение нейросетей всё новые и новые вычислительные ресурсы. Но мы уже живём в прекрасную эпоху, когда машины берут на себя всё больше рутинных задач и умнеют на глазах. А заодно служат людям отличным примером, потому что всегда учатся на своих ошибках.
Сделай сам
Нейронную сеть можно сделать с помощью спичечных коробков — тогда у вас в арсенале появится фокус, которым можно развлекать гостей на вечеринках. Редакция МирФ уже попробовала — и смиренно признаёт превосходство искусственного интеллекта. Давайте научим неразумную материю играть в игру «11 палочек». Правила просты: на столе лежит 11 спичек, и в каждый ход можно взять либо одну, либо две. Побеждает тот, кто взял последнюю. Как же играть в это против «компьютера»? Очень просто.
- Берём 10 коробков или стаканчиков. На каждом пишем номер от 2 до 11.
- Кладём в каждый коробок два камешка — чёрный и белый. Можно использовать любые предметы — лишь бы они отличались друг от друга. Всё — у нас есть сеть из десяти нейронов!
Теперь начинается игра.
- Нейросеть всегда ходит первой. Для начала посмотрите, сколько осталось спичек, и возьмите коробок с таким номером. На первом ходу это будет коробок №11.
- Возьмите из нужного коробка любой камешек. Можно закрыть глаза или кинуть монетку, главное — действовать наугад.
- Если камень белый — нейросеть решает взять две спички. Если чёрный — одну. Положите камешек рядом с коробком, чтобы не забыть, какой именно «нейрон» принимал решение.
- После этого ходит человек — и так до тех пор, пока спички не закончатся.
Ну а теперь начинается самое интересное: обучение. Если сеть выиграла партию, то её надо наградить: кинуть в те «нейроны», которые участвовали в этой партии, по одному дополнительному камешку того же цвета, который выпал во время игры. Если же сеть проиграла — возьмите последний использованный коробок и выньте оттуда неудачно сыгравший камень. Может оказаться, что коробок уже пустой, — тогда «последним» считается предыдущий походивший нейрон. Во время следующей партии, попав на пустой коробок, нейросеть автоматически сдастся.
Вот и всё! Сыграйте так несколько партий. Сперва вы не заметите ничего подозрительного, но после каждого выигрыша сеть будет делать всё более и более удачные ходы — и где-то через десяток партий вы поймёте, что создали монстра, которого не в силах обыграть.
Нейросети сейчас в моде, и не зря. С их помощью можно, к примеру, распознавать предметы на картинках или, наоборот, рисовать ночные кошмары Сальвадора Дали. Благодаря удобным библиотекам простейшие нейросети создаются всего парой строк кода, не больше уйдет и на обращение к искусственному интеллекту IBM.
Теория
Биологи до сих пор не знают, как именно работает мозг, но принцип действия отдельных элементов нервной системы неплохо изучен. Она состоит из нейронов — специализированных клеток, которые обмениваются между собой электрохимическими сигналами. У каждого нейрона имеется множество дендритов и один аксон. Дендриты можно сравнить со входами, через которые в нейрон поступают данные, аксон же служит его выходом. Соединения между дендритами и аксонами называют синапсами. Они не только передают сигналы, но и могут менять их амплитуду и частоту.
Преобразования, которые происходят на уровне отдельных нейронов, очень просты, однако даже совсем небольшие нейронные сети способны на многое. Все многообразие поведения червя Caenorhabditis elegans — движение, поиск пищи, различные реакции на внешние раздражители и многое другое — закодировано всего в трех сотнях нейронов. И ладно черви! Даже муравьям хватает 250 тысяч нейронов, а то, что они делают, машинам определенно не под силу.
Почти шестьдесят лет назад американский исследователь Фрэнк Розенблатт попытался создать компьютерную систему, устроенную по образу и подобию мозга, однако возможности его творения были крайне ограниченными. Интерес к нейросетям с тех пор вспыхивал неоднократно, однако раз за разом выяснялось, что вычислительной мощности не хватает на сколько-нибудь продвинутые нейросети. За последнее десятилетие в этом плане многое изменилось.
Электромеханический мозг с моторчиком
Машина Розенблатта называлась Mark I Perceptron. Она предназначалась для распознавания изображений — задачи, с которой компьютеры до сих пор справляются так себе. Mark I был снабжен подобием сетчатки глаза: квадратной матрицей из 400 фотоэлементов, двадцать по вертикали и двадцать по горизонтали. Фотоэлементы в случайном порядке подключались к электронным моделям нейронов, а они, в свою очередь, к восьми выходам. В качестве синапсов, соединяющих электронные нейроны, фотоэлементы и выходы, Розенблатт использовал потенциометры. При обучении перцептрона 512 шаговых двигателей автоматически вращали ручки потенциометров, регулируя напряжение на нейронах в зависимости от точности результата на выходе.
Вот в двух словах, как работает нейросеть. Искусственный нейрон, как и настоящий, имеет несколько входов и один выход. У каждого входа есть весовой коэффициент. Меняя эти коэффициенты, мы можем обучать нейронную сеть. Зависимость сигнала на выходе от сигналов на входе определяет так называемая функция активации.
В перцептроне Розенблатта функция активации складывала вес всех входов, на которые поступила логическая единица, а затем сравнивала результат с пороговым значением. Ее минус заключался в том, что незначительное изменение одного из весовых коэффициентов при таком подходе способно оказать несоразмерно большое влияние на результат. Это затрудняет обучение.
В современных нейронных сетях обычно используют нелинейные функции активации, например сигмоиду. К тому же у старых нейросетей было слишком мало слоев. Сейчас между входом и выходом обычно располагают один или несколько скрытых слоев нейронов. Именно там происходит все самое интересное.
Чтобы было проще понять, о чем идет речь, посмотри на эту схему. Это нейронная сеть прямого распространения с одним скрытым слоем. Каждый кружок соответствует нейрону. Слева находятся нейроны входного слоя. Справа — нейрон выходного слоя. В середине располагается скрытый слой с четырьмя нейронами. Выходы всех нейронов входного слоя подключены к каждому нейрону первого скрытого слоя. В свою очередь, входы нейрона выходного слоя связаны со всеми выходами нейронов скрытого слоя.
Не все нейронные сети устроены именно так. Например, существуют (хотя и менее распространены) сети, у которых сигнал с нейронов подается не только на следующий слой, как у сети прямого распространения с нашей схемы, но и в обратном направлении. Такие сети называются рекуррентными. Полностью соединенные слои — это тоже лишь один из вариантов, и одной из альтернатив мы даже коснемся.
Практика
Итак, давай попробуем построить простейшую нейронную сеть своими руками и разберемся в ее работе по ходу дела. Мы будем использовать Python с библиотекой Numpy (можно было бы обойтись и без Numpy, но с Numpy линейная алгебра отнимет меньше сил). Рассматриваемый пример основан на коде Эндрю Траска.
Нам понадобятся функции для вычисления сигмоиды и ее производной:
Продолжение доступно только подписчикам
Вариант 1. Оформи подписку на «Хакер», чтобы читать все материалы на сайте
Подписка позволит тебе в течение указанного срока читать ВСЕ платные материалы сайта. Мы принимаем оплату банковскими картами, электронными деньгами и переводами со счетов мобильных операторов.
Правильная постановка вопроса должна быть такой: как натренировать сою собственную нейросеть? Писать сеть самому не нужно, нужно взять какую-то из готовых реализаций, которых есть множество, предыдущие авторы давали ссылки. Но сама по себе эта реализация подобна компьютеру, в который не закачали никаких программ. Для того, чтобы сеть решала вашу задачу, ее нужно научить.
И тут возникает собственно самое важное, что вам для этого потребуется: ДАННЫЕ. Много примеров задач, которые будут подаваться на вход нейросети, и правильные ответы на эти задачи. Нейросеть будет на этом учиться самостоятельно давать эти правильные ответы.
И вот тут возникает куча деталей и нюансов, которые нужно знать и понимать, чтобы это все имело шанс дать приемлемый результат. Осветить их все здесь нереально, поэтому просто перечислю некоторые пункты. Во-первых, объем данных. Это очень важный момент. Крупные компании, деятельность которых связана с машинным обучением, обычно содержат специальные отделы и штат сотрудников, занимающихся только сбором и обработкой данных для обучения нейросетей. Нередко данные приходится покупать, и вся эта деятельность выливается в заметную статью расходов. Во-вторых, представление данных. Если каждый объект в вашей задаче представлен относительно небольшим числом числовых параметров, то есть шанс, что их можно прямо в таком сыром виде дать нейросети, и получить приемлемый результат на выходе. Но если объекты сложные (картинки, звук, объекты переменной размерности), то скорее всего придется потратить время и силы на выделение из них содержательных для решаемой задачи признаков. Одно только это может занять очень много времени и иметь гораздо более влияние на итоговый результат, чем даже вид и архитектура выбранной для использования нейросети.
Нередки случаи, когда реальные данные оказываются слишком сырыми и непригодными для использования без предварительной обработки: содержат пропуски, шумы, противоречия и ошибки.
Данные должны быть собраны тоже не абы как, а грамотно и продуманно. Иначе обученная сеть может вести себя странно и даже решать совсем не ту задачу, которую предполагал автор.
Также нужно представлять себе, как грамотно организовать процесс обучения, чтобы сеть не оказалась переученной. Сложность сети нужно выбирать исходя из размерности данных и их количества. Часть данных нужно отложить для теста и при обучении не использовать, чтобы оценить реальное качество работы. Иногда различным объектам из обучающего множества нужно приписать различный вес. Иногда эти веса полезно варьировать в процессе обучения. Иногда полезно начинать обучение на части данных, а по мере обучения добавлять оставшиеся данные. В общем, это можно сравнить с кулинарией: у каждой хозяйки свои приемы готовки даже одинаковых блюд.
Нейронная сеть искусственная в нефтегазе — Что такое Нейронная сеть искусственная в нефтегазе?
Нейросеть — Математическая модель, ее ПО и аппаратура, построенная по принципу биологических нейронных сетей — сетей нервных клеток живого организма
Нейронная сеть искусственная ( нейросеть) — это математическая модель, ее программное обеспечение (ПО) и аппаратура, построенная по принципу биологических нейронных сетей — сетей нервных клеток живого организма.
Использование нейронной сети — это развитие системы усовершенствованного управления технологическими процессами (СУУТП).
Ныне этапы развития автоматизации можно представить так:
КИПиА — АСУТП — СУУТП — машинное обучение и нейронные сети.
Интеллектуальность СУУТП в том, что она не просто позволяет регулировать каждый параметр в зависимости от внешних факторов и качества сырья, а задает рабочий алгоритм, заранее просчитывая и учитывая различные комбинации.
Автоматизированная система виртуальных анализаторов позволяет получить достоверную оперативную информацию о техпроцессе, обеспечивая с помощью математической модели имитацию данных с поточных анализаторов.
Машинное обучение и нейросети — это дальнейшее развитие технологий поиска зависимостей и моделей, отражающих реальный мир, где основную роль выполняет не человек, а ПО.
С использованием нейросетей возможна обработка гораздо больших массивов данных, что позволяет находить более точные, скрытые ранее зависимости между параметрами, а также адаптировать модели к изменениям в техпроцессе.
С февраля 2017 г. на Московском НПЗ Газпром нефти внедряется система усовершенствованного управления технологическими процессами (СУУТП) с перспективой развития машинного обучения и нейросетей.
Летом 2017 г. Казанский федеральный университет (КФУ) сообщил о создании геолого-динамической модели нефтяного месторождения с применением методов нейросетевого моделирования.
В декабре 2017 г. Кольский научный центр РАН сообщил о разработке метода автоматического 3х-мерного картирования месторождений полезных ископаемых с использованием нейросетей.
В марте 2018 г. Газпром нефть НТЦ совместно с Московским физико-техническим институтом (МФТИ) сообщили о создали самообучающуюся программу с использованием нейронных сетей, позволяющую прогнозировать свойства пород на новых месторождениях.
Что такое нейронные сети? — Соединенное Королевство
Нейронные сети отражают поведение человеческого мозга, позволяя компьютерным программам распознавать закономерности и решать общие проблемы в области искусственного интеллекта, машинного обучения и глубокого обучения.
Что такое нейронные сети?
Нейронные сети, также известные как искусственные нейронные сети (ИНС) или моделируемые нейронные сети (СНС), представляют собой подмножество машинного обучения и лежат в основе алгоритмов глубокого обучения.Их название и структура вдохновлены человеческим мозгом, имитируя способ передачи сигналов друг другу биологических нейронов.
Искусственные нейронные сети (ИНС) состоят из узловых слоев, содержащих входной слой, один или несколько скрытых слоев и выходной слой. Каждый узел или искусственный нейрон соединяется с другим и имеет связанный вес и порог. Если выходной сигнал любого отдельного узла превышает заданное пороговое значение, этот узел активируется, отправляя данные на следующий уровень сети.В противном случае никакие данные не передаются на следующий уровень сети.
Нейронные сети полагаются на обучающие данные для обучения и повышения своей точности с течением времени. Однако, как только эти алгоритмы обучения настроены на точность, они становятся мощными инструментами в области информатики и искусственного интеллекта, позволяя нам классифицировать и кластеризовать данные с высокой скоростью. Задачи по распознаванию речи или изображений могут занимать минуты, а не часы, по сравнению с идентификацией вручную специалистами-людьми.Одна из самых известных нейронных сетей — это поисковый алгоритм Google.
Как работают нейронные сети?
Думайте о каждом отдельном узле как о своей собственной модели линейной регрессии, состоящей из входных данных, весов, смещения (или порога) и выходных данных. Формула будет выглядеть примерно так:
∑wixi + смещение = w1x1 + w2x2 + w3x3 + смещение
output = f (x) = 1, если ∑w1x1 + b> = 0; 0, если ∑w1x1 + b <0
После определения входного слоя назначаются веса.Эти веса помогают определить важность любой данной переменной, причем более крупные из них вносят более значительный вклад в результат по сравнению с другими входными данными. Затем все входные данные умножаются на их соответствующие веса и затем суммируются. После этого вывод проходит через функцию активации, которая определяет вывод. Если этот выходной сигнал превышает заданный порог, он «запускает» (или активирует) узел, передавая данные на следующий уровень в сети. Это приводит к тому, что выход одного узла становится входом следующего узла.Этот процесс передачи данных от одного уровня к следующему определяет эту нейронную сеть как сеть прямого распространения.
Давайте разберемся, как может выглядеть один единственный узел, используя двоичные значения. Мы можем применить эту концепцию к более осязаемому примеру, например, стоит ли вам заниматься серфингом (Да: 1, Нет: 0). Решение ехать или не ехать — это наш прогнозируемый результат, или н-хет. Предположим, на ваше решение влияют три фактора:
- Волны хорошие? (Да: 1, Нет: 0)
- Состав пуст? (Да: 1, Нет: 0)
- Было ли нападение акулы в последнее время? (Да: 0, Нет: 1)
Тогда предположим следующее, дав нам следующие входные данные:
- X1 = 1, так как волны накачиваются
- X2 = 0, так как толпы нет
- X3 = 1, так как нападения акул в последнее время не было.
Теперь нам нужно присвоить веса, чтобы определить важность.Большие веса означают, что определенные переменные имеют большее значение для решения или результата.
- W1 = 5, так как большие вздутия возникают нечасто
- W2 = 2, раз уж вы привыкли к толпе
- W3 = 4, так как вы боитесь акул
Наконец, мы также предположим, что пороговое значение равно 3, что соответствует значению смещения –3. Имея все различные входные данные, мы можем начать подставлять значения в формулу, чтобы получить желаемый результат.
Y-шляпа = (1 * 5) + (0 * 2) + (1 * 4) — 3 = 6
Если мы воспользуемся функцией активации из начала этого раздела, мы сможем определить, что на выходе этого узла будет 1, поскольку 6 больше 0. В этом случае вы будете заниматься серфингом; но если мы скорректируем веса или порог, мы сможем получить разные результаты от модели. Наблюдая за одним решением, как в приведенном выше примере, мы можем увидеть, как нейронная сеть может принимать все более сложные решения в зависимости от результатов предыдущих решений или уровней.
В приведенном выше примере мы использовали перцептроны, чтобы проиллюстрировать некоторые математические аспекты здесь, но нейронные сети используют сигмовидные нейроны, которые отличаются значениями от 0 до 1. Поскольку нейронные сети ведут себя аналогично деревьям решений, каскадные данные из одного узел к другому, наличие значений x от 0 до 1 уменьшит влияние любого заданного изменения одной переменной на выход любого заданного узла, а затем и выход нейронной сети.
По мере того, как мы начинаем думать о более практических примерах использования нейронных сетей, таких как распознавание или классификация изображений, мы будем использовать контролируемое обучение или размеченные наборы данных для обучения алгоритма.2
В конечном итоге цель состоит в том, чтобы свести к минимуму нашу функцию затрат, чтобы гарантировать правильность подгонки для любого данного наблюдения. По мере того, как модель корректирует свои веса и смещение, она использует функцию стоимости и обучение с подкреплением, чтобы достичь точки сходимости или локального минимума. Процесс, в котором алгоритм корректирует свои веса, осуществляется посредством градиентного спуска, что позволяет модели определять направление, в котором следует двигаться, чтобы уменьшить ошибки (или минимизировать функцию стоимости). В каждом примере обучения параметры модели постепенно сходятся к минимуму.
См. Эту статью IBM Developer для более глубокого объяснения количественных концепций, используемых в нейронных сетях.
Большинство глубоких нейронных сетей имеют прямую связь, то есть они движутся только в одном направлении, от входа к выходу. Однако вы также можете обучить свою модель с помощью обратного распространения ошибки; то есть двигаться в противоположном направлении от вывода к вводу. Обратное распространение позволяет нам вычислить и приписать ошибку, связанную с каждым нейроном, что позволяет нам соответствующим образом настроить и подогнать параметры модели (моделей).
Типы нейронных сетей
Нейронные сети можно разделить на разные типы, которые используются для разных целей. Хотя это неполный список типов, ниже представлены наиболее распространенные типы нейронных сетей, с которыми вы столкнетесь в типичных случаях использования:
Персептрон — самая старая нейронная сеть, созданная Фрэнком Розенблаттом в 1958 году. Она состоит из одного нейрона и представляет собой простейшую форму нейронной сети:
Нейронные сети с прямой связью или многослойные перцептроны (MLP) — это то, на чем мы в первую очередь сосредоточились в этой статье.Они состоят из входного слоя, скрытого слоя или слоев и выходного слоя. Хотя эти нейронные сети также обычно называют MLP, важно отметить, что они на самом деле состоят из сигмовидных нейронов, а не перцептронов, поскольку большинство реальных проблем нелинейны. Данные обычно вводятся в эти модели для их обучения, и они являются основой для компьютерного зрения, обработки естественного языка и других нейронных сетей.
Сверточные нейронные сети (CNN) похожи на сети прямого распространения, но обычно используются для распознавания изображений, распознавания образов и / или компьютерного зрения.Эти сети используют принципы линейной алгебры, в частности, матричное умножение, для выявления закономерностей в изображении.
Рекуррентные нейронные сети (RNN) идентифицируются по их петлям обратной связи. Эти алгоритмы обучения в первую очередь используются при использовании данных временных рядов для прогнозирования будущих результатов, например прогнозов фондового рынка или прогнозирования продаж.
Нейронные сети и глубокое обучение
Deep Learning и нейронные сети, как правило, взаимозаменяемы в разговоре, что может сбивать с толку.В результате стоит отметить, что «глубокое» в глубоком обучении означает просто глубину слоев в нейронной сети. Нейронная сеть, состоящая из более чем трех слоев, включая входные и выходные данные, может считаться алгоритмом глубокого обучения. Нейронная сеть, состоящая всего из двух или трех слоев, — это просто базовая нейронная сеть.
Чтобы узнать больше о различиях между нейронными сетями и другими формами искусственного интеллекта, такими как машинное обучение, прочтите сообщение в блоге «AI vs.Машинное обучение, глубокое обучение и нейронные сети: в чем разница? »
История нейронных сетей
История нейронных сетей длиннее, чем думает большинство людей. Хотя идея «машины, которая думает» восходит к древним грекам, мы сосредоточимся на ключевых событиях, которые привели к эволюции мышления вокруг нейронных сетей, популярность которой с годами снижалась и уменьшалась:
1943: Уоррен С. Маккалок и Уолтер Питтс опубликовали «Логический расчет идей, присущих нервной деятельности (PDF, 1 МБ) (ссылка находится вне IBM)». Это исследование было направлено на то, чтобы понять, как человеческий мозг может создавать сложные модели через связанные клетки мозга или нейроны.Одной из основных идей, которые возникли в результате этой работы, было сравнение нейронов с бинарным порогом с булевой логикой (т. Е. С утверждениями 0/1 или истинным / ложным).
1958: Фрэнку Розенблатту приписывают разработку персептрона, документально подтвержденного в его исследовании «Персептрон: вероятностная модель хранения и организации информации в мозге» (PDF, 1,6 МБ) (ссылка находится вне IBM). Он продвигает работу Маккаллоха и Питта на шаг вперед, вводя в уравнение веса.Используя IBM 704, Розенблатт смог заставить компьютер научиться отличать карты, отмеченные слева, от карт, отмеченных справа.
1974: В то время как многочисленные исследователи внесли свой вклад в идею обратного распространения ошибки, Пол Вербос был первым человеком в США, который отметил его применение в нейронных сетях в своей докторской диссертации (PDF, 8,1 МБ) (ссылка находится за пределами IBM).
1989: Ян Лекун опубликовал статью (PDF, 5,7 МБ) (ссылка находится за пределами IBM), в которой показано, как использование ограничений в обратном распространении и его интеграция в архитектуру нейронной сети может использоваться для обучения алгоритмов.В этом исследовании успешно использовалась нейронная сеть для распознавания рукописных цифр почтового индекса, предоставленного почтовой службой США.
Нейронные сети и IBM Cloud
Вот уже несколько десятилетий IBM является пионером в разработке технологий искусственного интеллекта и нейронных сетей, что подтверждается развитием и развитием IBM Watson. Watson теперь является надежным решением для предприятий, которые хотят применить в своих системах передовые методы обработки естественного языка и глубокого обучения, используя проверенный многоуровневый подход к внедрению и внедрению искусственного интеллекта.
Watson использует инфраструктуру Apache Unstructured Information Management Architecture (UIMA) и программное обеспечение IBM DeepQA, чтобы сделать мощные возможности глубокого обучения доступными для приложений. Используя такие инструменты, как IBM Watson Studio, ваше предприятие может беспрепятственно внедрять проекты ИИ с открытым исходным кодом в производство при развертывании и запуске моделей в любом облаке.
Для получения дополнительной информации о том, как начать работу с технологией глубокого обучения, изучите IBM Watson Studio и службу Deep Learning.
Зарегистрируйтесь в IBMid и создайте свою учетную запись IBM Cloud.
Что такое нейронные сети? — Австралия
Нейронные сети отражают поведение человеческого мозга, позволяя компьютерным программам распознавать закономерности и решать общие проблемы в области искусственного интеллекта, машинного обучения и глубокого обучения.
Что такое нейронные сети?
Нейронные сети, также известные как искусственные нейронные сети (ИНС) или моделируемые нейронные сети (СНС), представляют собой подмножество машинного обучения и лежат в основе алгоритмов глубокого обучения.Их название и структура вдохновлены человеческим мозгом, имитируя способ передачи сигналов друг другу биологических нейронов.
Искусственные нейронные сети (ИНС) состоят из узловых слоев, содержащих входной слой, один или несколько скрытых слоев и выходной слой. Каждый узел или искусственный нейрон соединяется с другим и имеет связанный вес и порог. Если выходной сигнал любого отдельного узла превышает заданное пороговое значение, этот узел активируется, отправляя данные на следующий уровень сети.В противном случае никакие данные не передаются на следующий уровень сети.
Нейронные сети полагаются на обучающие данные для обучения и повышения своей точности с течением времени. Однако, как только эти алгоритмы обучения настроены на точность, они становятся мощными инструментами в области информатики и искусственного интеллекта, позволяя нам классифицировать и кластеризовать данные с высокой скоростью. Задачи по распознаванию речи или изображений могут занимать минуты, а не часы, по сравнению с идентификацией вручную специалистами-людьми.Одна из самых известных нейронных сетей — это поисковый алгоритм Google.
Как работают нейронные сети?
Думайте о каждом отдельном узле как о своей собственной модели линейной регрессии, состоящей из входных данных, весов, смещения (или порога) и выходных данных. Формула будет выглядеть примерно так:
∑wixi + смещение = w1x1 + w2x2 + w3x3 + смещение
output = f (x) = 1, если ∑w1x1 + b> = 0; 0, если ∑w1x1 + b <0
После определения входного слоя назначаются веса.Эти веса помогают определить важность любой данной переменной, причем более крупные из них вносят более значительный вклад в результат по сравнению с другими входными данными. Затем все входные данные умножаются на их соответствующие веса и затем суммируются. После этого вывод проходит через функцию активации, которая определяет вывод. Если этот выходной сигнал превышает заданный порог, он «запускает» (или активирует) узел, передавая данные на следующий уровень в сети. Это приводит к тому, что выход одного узла становится входом следующего узла.Этот процесс передачи данных от одного уровня к следующему определяет эту нейронную сеть как сеть прямого распространения.
Давайте разберемся, как может выглядеть один единственный узел, используя двоичные значения. Мы можем применить эту концепцию к более осязаемому примеру, например, стоит ли вам заниматься серфингом (Да: 1, Нет: 0). Решение ехать или не ехать — это наш прогнозируемый результат, или н-хет. Предположим, на ваше решение влияют три фактора:
- Волны хорошие? (Да: 1, Нет: 0)
- Состав пуст? (Да: 1, Нет: 0)
- Было ли нападение акулы в последнее время? (Да: 0, Нет: 1)
Тогда предположим следующее, дав нам следующие входные данные:
- X1 = 1, так как волны накачиваются
- X2 = 0, так как толпы нет
- X3 = 1, так как нападения акул в последнее время не было.
Теперь нам нужно присвоить веса, чтобы определить важность.Большие веса означают, что определенные переменные имеют большее значение для решения или результата.
- W1 = 5, так как большие вздутия возникают нечасто
- W2 = 2, раз уж вы привыкли к толпе
- W3 = 4, так как вы боитесь акул
Наконец, мы также предположим, что пороговое значение равно 3, что соответствует значению смещения –3. Имея все различные входные данные, мы можем начать подставлять значения в формулу, чтобы получить желаемый результат.
Y-шляпа = (1 * 5) + (0 * 2) + (1 * 4) — 3 = 6
Если мы воспользуемся функцией активации из начала этого раздела, мы сможем определить, что на выходе этого узла будет 1, поскольку 6 больше 0. В этом случае вы будете заниматься серфингом; но если мы скорректируем веса или порог, мы сможем получить разные результаты от модели. Наблюдая за одним решением, как в приведенном выше примере, мы можем увидеть, как нейронная сеть может принимать все более сложные решения в зависимости от результатов предыдущих решений или уровней.
В приведенном выше примере мы использовали перцептроны, чтобы проиллюстрировать некоторые математические аспекты здесь, но нейронные сети используют сигмовидные нейроны, которые отличаются значениями от 0 до 1. Поскольку нейронные сети ведут себя аналогично деревьям решений, каскадные данные из одного узел к другому, наличие значений x от 0 до 1 уменьшит влияние любого заданного изменения одной переменной на выход любого заданного узла, а затем и выход нейронной сети.
По мере того, как мы начинаем думать о более практических примерах использования нейронных сетей, таких как распознавание или классификация изображений, мы будем использовать контролируемое обучение или размеченные наборы данных для обучения алгоритма.2
В конечном итоге цель состоит в том, чтобы свести к минимуму нашу функцию затрат, чтобы гарантировать правильность подгонки для любого данного наблюдения. По мере того, как модель корректирует свои веса и смещение, она использует функцию стоимости и обучение с подкреплением, чтобы достичь точки сходимости или локального минимума. Процесс, в котором алгоритм корректирует свои веса, осуществляется посредством градиентного спуска, что позволяет модели определять направление, в котором следует двигаться, чтобы уменьшить ошибки (или минимизировать функцию стоимости). В каждом примере обучения параметры модели постепенно сходятся к минимуму.
См. Эту статью IBM Developer для более глубокого объяснения количественных концепций, используемых в нейронных сетях.
Большинство глубоких нейронных сетей имеют прямую связь, то есть они движутся только в одном направлении, от входа к выходу. Однако вы также можете обучить свою модель с помощью обратного распространения ошибки; то есть двигаться в противоположном направлении от вывода к вводу. Обратное распространение позволяет нам вычислить и приписать ошибку, связанную с каждым нейроном, что позволяет нам соответствующим образом настроить и подогнать параметры модели (моделей).
Типы нейронных сетей
Нейронные сети можно разделить на разные типы, которые используются для разных целей. Хотя это неполный список типов, ниже представлены наиболее распространенные типы нейронных сетей, с которыми вы столкнетесь в типичных случаях использования:
Персептрон — самая старая нейронная сеть, созданная Фрэнком Розенблаттом в 1958 году. Она состоит из одного нейрона и представляет собой простейшую форму нейронной сети:
Нейронные сети с прямой связью или многослойные перцептроны (MLP) — это то, на чем мы в первую очередь сосредоточились в этой статье.Они состоят из входного слоя, скрытого слоя или слоев и выходного слоя. Хотя эти нейронные сети также обычно называют MLP, важно отметить, что они на самом деле состоят из сигмовидных нейронов, а не перцептронов, поскольку большинство реальных проблем нелинейны. Данные обычно вводятся в эти модели для их обучения, и они являются основой для компьютерного зрения, обработки естественного языка и других нейронных сетей.
Сверточные нейронные сети (CNN) похожи на сети прямого распространения, но обычно используются для распознавания изображений, распознавания образов и / или компьютерного зрения.Эти сети используют принципы линейной алгебры, в частности, матричное умножение, для выявления закономерностей в изображении.
Рекуррентные нейронные сети (RNN) идентифицируются по их петлям обратной связи. Эти алгоритмы обучения в первую очередь используются при использовании данных временных рядов для прогнозирования будущих результатов, например прогнозов фондового рынка или прогнозирования продаж.
Нейронные сети и глубокое обучение
Deep Learning и нейронные сети, как правило, взаимозаменяемы в разговоре, что может сбивать с толку.В результате стоит отметить, что «глубокое» в глубоком обучении означает просто глубину слоев в нейронной сети. Нейронная сеть, состоящая из более чем трех слоев, включая входные и выходные данные, может считаться алгоритмом глубокого обучения. Нейронная сеть, состоящая всего из двух или трех слоев, — это просто базовая нейронная сеть.
Чтобы узнать больше о различиях между нейронными сетями и другими формами искусственного интеллекта, такими как машинное обучение, прочтите сообщение в блоге «AI vs.Машинное обучение, глубокое обучение и нейронные сети: в чем разница? »
История нейронных сетей
История нейронных сетей длиннее, чем думает большинство людей. Хотя идея «машины, которая думает» восходит к древним грекам, мы сосредоточимся на ключевых событиях, которые привели к эволюции мышления вокруг нейронных сетей, популярность которой с годами снижалась и уменьшалась:
1943: Уоррен С. Маккалок и Уолтер Питтс опубликовали «Логический расчет идей, присущих нервной деятельности (PDF, 1 МБ) (ссылка находится вне IBM)». Это исследование было направлено на то, чтобы понять, как человеческий мозг может создавать сложные модели через связанные клетки мозга или нейроны.Одной из основных идей, которые возникли в результате этой работы, было сравнение нейронов с бинарным порогом с булевой логикой (т. Е. С утверждениями 0/1 или истинным / ложным).
1958: Фрэнку Розенблатту приписывают разработку персептрона, документально подтвержденного в его исследовании «Персептрон: вероятностная модель хранения и организации информации в мозге» (PDF, 1,6 МБ) (ссылка находится вне IBM). Он продвигает работу Маккаллоха и Питта на шаг вперед, вводя в уравнение веса.Используя IBM 704, Розенблатт смог заставить компьютер научиться отличать карты, отмеченные слева, от карт, отмеченных справа.
1974: В то время как многочисленные исследователи внесли свой вклад в идею обратного распространения ошибки, Пол Вербос был первым человеком в США, который отметил его применение в нейронных сетях в своей докторской диссертации (PDF, 8,1 МБ) (ссылка находится за пределами IBM).
1989: Ян Лекун опубликовал статью (PDF, 5,7 МБ) (ссылка находится за пределами IBM), в которой показано, как использование ограничений в обратном распространении и его интеграция в архитектуру нейронной сети может использоваться для обучения алгоритмов.В этом исследовании успешно использовалась нейронная сеть для распознавания рукописных цифр почтового индекса, предоставленного почтовой службой США.
Нейронные сети и IBM Cloud
Вот уже несколько десятилетий IBM является пионером в разработке технологий искусственного интеллекта и нейронных сетей, что подтверждается развитием и развитием IBM Watson. Watson теперь является надежным решением для предприятий, которые хотят применить в своих системах передовые методы обработки естественного языка и глубокого обучения, используя проверенный многоуровневый подход к внедрению и внедрению искусственного интеллекта.
Watson использует инфраструктуру Apache Unstructured Information Management Architecture (UIMA) и программное обеспечение IBM DeepQA, чтобы сделать мощные возможности глубокого обучения доступными для приложений. Используя такие инструменты, как IBM Watson Studio, ваше предприятие может беспрепятственно внедрять проекты ИИ с открытым исходным кодом в производство при развертывании и запуске моделей в любом облаке.
Для получения дополнительной информации о том, как начать работу с технологией глубокого обучения, изучите IBM Watson Studio и службу Deep Learning.
Зарегистрируйтесь в IBMid и создайте свою учетную запись IBM Cloud.
Определение нейронной сети| DeepAI
Что такое нейронная сеть?
Искусственная нейронная сеть , алгоритм обучения , или нейронная сеть , , или просто нейронная сеть
, представляет собой вычислительную обучающую систему, которая использует сеть функций для понимания и преобразования вводимых данных одной формы в желаемый результат. , обычно в другой форме.Концепция искусственной нейронной сети была вдохновлена биологией человека и тем, как нейроны человеческого мозга работают вместе, чтобы понимать сигналы, поступающие от органов чувств.
Нейронные сети — лишь один из многих инструментов и подходов, используемых в алгоритмах машинного обучения. Сама нейронная сеть может использоваться как часть множества различных алгоритмов машинного обучения для обработки сложных входных данных в пространстве, понятном компьютерам.
Нейронные сети сегодня применяются для решения многих реальных проблем, включая распознавание речи и изображений, фильтрацию спама в электронной почте, финансы и медицинскую диагностику, и это лишь некоторые из них.
Как работает нейронная сеть?
Алгоритмы машинного обучения, использующие нейронные сети, обычно не нуждаются в программировании с конкретными правилами, которые определяют, чего ожидать от входных данных. Алгоритм обучения нейронной сети вместо этого учится на обработке множества помеченных примеров (т.е. данных с «ответами»), которые предоставляются во время обучения, и использования этого ключа ответа, чтобы узнать, какие характеристики ввода необходимы для построения правильного вывода. После обработки достаточного количества примеров нейронная сеть может начать обрабатывать новые, невидимые входные данные и успешно возвращать точные результаты.Чем больше примеров и разнообразия входных данных видит программа, тем более точными обычно становятся результаты, потому что программа учится с опытом.
Эту концепцию лучше всего можно понять на примере. Представьте себе «простую» проблему, заключающуюся в попытке определить, есть ли на изображении кошка. Хотя это довольно легко понять человеку, гораздо сложнее научить компьютер распознавать кошку на изображении с помощью классических методов. Учитывая разнообразие возможностей того, как кошка может выглядеть на картинке, написать код для каждого сценария практически невозможно.Но с помощью машинного обучения и, в частности, нейронных сетей, программа может использовать обобщенный подход к пониманию содержания изображения. Используя несколько уровней функций для разложения изображения на точки данных и информацию, которую может использовать компьютер, нейронная сеть может начать выявлять тенденции, существующие во многих, многих примерах, которые она обрабатывает, и классифицировать изображения по их сходству.
(изображение взято из Google Tech Talk Джеффа Дина в кампусе Сеула 7 марта 2016 г.)
После обработки множества обучающих примеров изображений кошек алгоритм имеет модель того, какие элементы и их соответствующие отношения на изображении важно учитывать при принятии решения о том, присутствует ли кошка на изображении или нет.При оценке нового изображения нейронная сеть сравнивает точки данных о новом изображении с его моделью, которая основана на всех предыдущих оценках. Затем он использует простую статистику, чтобы решить, есть ли на изображении кошка или нет, в зависимости от того, насколько близко оно соответствует модели.
В этом примере уровни функций между входом и выходом составляют нейронную сеть. На практике нейронная сеть немного сложнее, чем показано на изображении выше. Следующее изображение немного лучше отражает взаимодействие между слоями, но имейте в виду, что существует множество вариантов взаимоотношений между узлами или искусственными нейронами:
Приложения нейронных сетей
Нейронные сети могут применяться для решения широкого круга задач и могут оценивать множество различных типов входных данных, включая изображения, видео, файлы, базы данных и многое другое.Они также не требуют явного программирования для интерпретации содержимого этих входных данных.
Благодаря обобщенному подходу к решению проблем, который предлагают нейронные сети, практически нет ограничений на области, в которых может применяться этот метод. Некоторые распространенные применения нейронных сетей сегодня включают распознавание изображений / образов, прогнозирование траектории беспилотных транспортных средств, распознавание лиц, интеллектуальный анализ данных, фильтрацию спама в электронной почте, медицинскую диагностику и исследования рака. Сегодня существует множество других способов использования нейронных сетей, и их внедрение быстро растет.
нейронная сеть | вычисления | Britannica
нейронная сеть , компьютерная программа, которая работает по принципу естественной нейронной сети в мозгу. Задача таких искусственных нейронных сетей — выполнять такие когнитивные функции, как решение проблем и машинное обучение. Теоретические основы нейронных сетей были разработаны в 1943 году нейрофизиологом Уорреном Маккалоком из Университета Иллинойса и математиком Уолтером Питтсом из Университета Чикаго.В 1954 году Белмонту Фарли и Уэсли Кларку из Массачусетского технологического института удалось запустить первую простую нейронную сеть. Основная привлекательность нейронных сетей — их способность имитировать умение мозга распознавать образы. Среди коммерческих приложений этой способности нейронные сети использовались для принятия инвестиционных решений, распознавания почерка и даже обнаружения бомб.
Отличительной особенностью нейронных сетей является то, что знания о ее области распределяются по самой сети, а не явно записываются в программу.Эти знания моделируются как связи между обрабатывающими элементами (искусственными нейронами) и адаптивными весами каждой из этих связей. Затем сеть учится через различные ситуации. Нейронные сети могут добиться этого, регулируя вес соединений между взаимодействующими нейронами, сгруппированными в слои, как показано на рисунке простой сети прямого распространения. Входной слой искусственных нейронов получает информацию из окружающей среды, а выходной слой передает ответ; между этими уровнями может находиться один или несколько «скрытых» слоев (без прямого контакта с окружающей средой), где происходит большая часть обработки информации.Выход нейронной сети зависит от веса связей между нейронами в разных слоях. Каждый вес указывает на относительную важность определенного соединения. Если сумма всех взвешенных входов, полученных конкретным нейроном, превышает определенное пороговое значение, нейрон отправит сигнал каждому нейрону, к которому он подключен в следующем слое. Например, при обработке заявок на получение ссуды входные данные могут представлять данные профиля соискателя ссуды и выходные данные о том, предоставлять ли ссуду.
Британская викторина
Викторина по компьютерам и технологиям
Компьютеры размещают веб-сайты, состоящие из HTML, и отправляют текстовые сообщения так же просто, как … LOL. Примите участие в этой викторине и позвольте некоторым технологиям подсчитать ваш результат и раскрыть вам содержание.
Две модификации этой простой нейронной сети с прямой связью учитывают рост приложений, таких как распознавание лиц.Во-первых, сеть может быть оснащена механизмом обратной связи, известным как алгоритм обратного распространения, который позволяет ей регулировать веса соединений обратно через сеть, обучая ее в ответ на типичные примеры. Во-вторых, могут быть разработаны рекуррентные нейронные сети, включающие сигналы, которые проходят в обоих направлениях, а также внутри и между слоями, и эти сети способны к значительно более сложным схемам ассоциации. (Фактически, для больших сетей может быть чрезвычайно сложно точно проследить, как был определен выход.)
Обучающие нейронные сети обычно включают обучение с учителем, где каждый обучающий пример содержит значения как входных данных, так и желаемых выходных данных. Как только сеть сможет достаточно хорошо работать на дополнительных тестовых примерах, ее можно будет применить к новым случаям. Например, исследователи из Университета Британской Колумбии обучили нейронную сеть с прямой связью с данными о температуре и давлении из тропического Тихого океана и из Северной Америки, чтобы предсказывать будущие глобальные погодные условия.
Получите подписку Britannica Premium и получите доступ к эксклюзивному контенту. Подпишитесь сейчасНапротив, некоторые нейронные сети обучаются посредством обучения без учителя, при котором сети предоставляется набор входных данных и ставится цель обнаруживать закономерности — без указания, что конкретно нужно искать. Такая нейронная сеть может использоваться в интеллектуальном анализе данных, например, для обнаружения кластеров клиентов в хранилище маркетинговых данных.
Нейронные сети находятся на переднем крае когнитивных вычислений, которые предназначены для того, чтобы информационные технологии выполняли некоторые из более продвинутых психических функций человека.Системы глубокого обучения основаны на многоуровневых нейронных сетях и мощи, например, на функции распознавания речи мобильного помощника Apple Siri. В сочетании с экспоненциально растущими вычислительными мощностями и массивными агрегатами больших данных нейронные сети с глубоким обучением влияют на распределение работы между людьми и машинами.
Машинное обучение для начинающих: введение в нейронные сети | Виктор Чжоу
Простое объяснение того, как они работают и как реализовать их с нуля на Python.
Вот кое-что, что может вас удивить: нейронные сети не такие уж и сложные! Термин «нейронная сеть» часто используется как модное слово, но на самом деле они часто намного проще, чем люди думают.
Этот пост предназначен для начинающих и предполагает НУЛЕВОЕ предварительное знание машинного обучения . Мы поймем, как работают нейронные сети, реализуя одну с нуля на Python.
Приступим!
Примечание: рекомендую прочитать этот пост о Викторчжоу.com — большая часть форматирования в этом посте выглядит там лучше.
Во-первых, мы должны поговорить о нейронах, основной единице нейронной сети. Нейрон принимает входные данные, выполняет с ними некоторые вычисления и выдает один выходной сигнал . Вот как выглядит нейрон с двумя входами:
Здесь происходит 3 вещи. Сначала каждый вход умножается на вес:
Затем все взвешенные входы складываются вместе со смещением b:
Наконец, сумма пропускается через функцию активации:
Функция активации используется для включения неограниченного ввод в вывод, который имеет приятную предсказуемую форму.Обычно используемой функцией активации является сигмоидальная функция:
Сигмоидальная функция выводит только числа в диапазоне (0,1). Вы можете думать об этом как о сжатии (−∞, + ∞) до (0,1) — большие отрицательные числа становятся ~ 0, а большие положительные числа становятся ~ 1.
Напоминание: большая часть форматирования в этой статье выглядит лучше в исходном сообщении на victorzhou.com.
Предположим, у нас есть нейрон с двумя входами, который использует сигмовидную функцию активации и имеет следующие параметры:
w = [0, 1] — это просто способ записи w 1 = 0, w 2 = 1 в векторной форме.Теперь давайте введем нейрону x = [2, 3]. Мы воспользуемся скалярным произведением, чтобы записать вещи более кратко:
Нейрон выдает 0,999 при входных данных x = [2,3]. Вот и все! Этот процесс передачи входных данных вперед для получения выходных данных известен как с прямой связью .
Пора реализовать нейрон! Мы воспользуемся NumPy, популярной и мощной вычислительной библиотекой для Python, чтобы помочь нам в математических вычислениях:
Распознать эти числа? Это тот пример, который мы только что сделали! Получаем тот же ответ 0.999.
Нейронная сеть — это не что иное, как связка нейронов, соединенных вместе. Вот как может выглядеть простая нейронная сеть:
Эта сеть имеет 2 входа, скрытый слой с 2 нейронами ( h 1 и h 2) и выходной слой с 1 нейроном ( o 1). ). Обратите внимание, что входы для o 1 — это выходы для h 1 и h 2 — вот что делает эту сеть.
Скрытый слой — это любой слой между входным (первым) и выходным (последним) слоями.Может быть несколько скрытых слоев!
Давайте воспользуемся схемой, изображенной выше, и предположим, что все нейроны имеют одинаковые веса w = [0,1], одинаковое смещение b = 0 и одну и ту же функцию активации сигмоида. Пусть h 1, h 2, o 1 обозначают выходы нейронов, которые они представляют.
Что произойдет, если мы передадим на вход x = [2, 3]?
Выход нейронной сети для входа x = [2,3] равен 0.7216. Довольно просто, правда?
Нейронная сеть может иметь любое количество слоев с любым количеством нейронов в этих слоях. Основная идея остается прежней: направить вход (ы) вперед через нейроны в сети, чтобы получить результат (ы) в конце. Для простоты мы продолжим использовать сеть, изображенную выше, до конца этой публикации.
Давайте реализуем прямую связь для нашей нейронной сети. Вот снова изображение сети для справки:
Мы получили 0.7216 снова! Похоже, работает.
Допустим, у нас есть следующие измерения:
Давайте обучим нашу сеть предсказывать пол человека с учетом его веса и роста:
Мы представим мужчину с помощью 0 и женщину с 1, а также перенесем данные в упростить использование:
Перед тем, как обучать нашу сеть, нам сначала нужен способ количественно оценить, насколько она «хороша», чтобы она могла попытаться сделать «лучше». Вот что такое потеря .
Мы будем использовать среднеквадратичную ошибку . (MSE) потеря:
Давайте разберем это:
- n — это количество выборок, равное 4 (Алиса, Боб, Чарли, Диана).
- y представляет прогнозируемую переменную, т. Е. Пол.
- y_true — это истинное значение переменной («правильный ответ»). Например, y_true для Алисы будет 1 (женщина).
- y_pred — это прогнозируемое значение переменной . Это то, что выводит наша сеть.
( y_true — y_pred ) ² известна как ошибка квадрата . Наша функция потерь просто берет среднее значение по всем квадратам ошибок (отсюда и название означает ошибку в квадрате ).Чем лучше наши прогнозы, тем меньше будут наши потери!
Лучшие прогнозы = меньшие убытки.
Обучение сети = попытка минимизировать ее потери.
Допустим, наша сеть всегда выводит 00 — другими словами, она уверена, что все люди — мужчины 🤔. Какой была бы наша потеря?
Код: MSE Loss
Вот код для расчета потерь для нас:
Если вы не понимаете, почему этот код работает, прочтите краткое руководство NumPy по операциям с массивами.Ницца.Вперед!
Нравится этот пост? Я пишу много статей по ML для начинающих. Подпишитесь на мою рассылку, чтобы получать их в свой почтовый ящик!
Теперь у нас есть четкая цель: минимизировать потери нейронной сети. Мы знаем, что можем изменить веса и смещения сети, чтобы повлиять на ее прогнозы, но как это сделать, чтобы уменьшить потери?
В этом разделе используется немного многомерного исчисления. Если вас не устраивает математический анализ, не стесняйтесь пропускать математические части.
Для простоты представим, что в нашем наборе данных есть только Алиса:
Тогда среднеквадратичная потеря ошибки — это просто квадрат ошибки Алисы:
Еще один способ думать о потерях — это как функция весов и смещений. Обозначим каждый вес и смещение в нашей сети:
Затем мы можем записать потери как многопараметрическую функцию:
Представьте, что мы хотим настроить на 1. Как изменились бы потери L , если бы мы изменили на 1? На этот вопрос может ответить частная производная.Как рассчитать?
Здесь математика начинает усложняться. Не расстраивайтесь! Я рекомендую взять ручку и бумагу, чтобы следить за текстом — это поможет вам понять.
Если у вас возникли проблемы с чтением этого: форматирование для математических расчетов ниже выглядит лучше в исходном сообщении на victorzhou.com.
Для начала давайте перепишем частную производную в терминах ∂ y_pred / ∂ w 1 вместо:
Это работает из-за правила цепочки.Мы можем вычислить ∂ L / ∂ y_pred , потому что мы вычислили L = (1− y_pred ) ² выше:
Теперь давайте разберемся, что делать с ∂ y_pred / ∂ w 1. Как и раньше, пусть h 1, h 2, o 1 будут выходами нейронов, которые они представляют. Тогда
f — это функция активации сигмовидной кишки, помните?Поскольку w 1 влияет только на h 1 (не h 2), мы можем написать
More Chain Rule.Мы делаем то же самое для ∂ h 1 / ∂ w 1:
Как вы уже догадались, правило цепочки.x 1 здесь вес, а x 2 высота. Это уже второй раз, когда мы видим f ′ ( x ) (производное сигмоидной функции)! Получим это:
Мы будем использовать эту красивую форму для f ′ ( x ) позже.
Готово! Нам удалось разбить ∂ L / ∂ w 1 на несколько частей, которые мы можем вычислить:
Эта система вычисления частных производных путем работы в обратном направлении известна как backpropagation , или «backprop».
Уф. Это было много символов — ничего страшного, если вы еще немного запутались. Давайте рассмотрим пример, чтобы увидеть это в действии!
Мы продолжим притворяться, что в нашем наборе данных есть только Алиса:
Давайте инициализируем все веса до 1 и все смещения до 0. Если мы сделаем прямой проход через сеть, мы получим:
Сетевые выходы y_pred = 0,524, что не сильно способствует мужскому (0) или женскому (1). Рассчитаем ∂ L / ∂ w 1:
Напоминание: мы вывели f ′ ( x ) = f ( x ) ∗ (1− f ( x ) )) для нашей сигмовидной функции активации ранее.
У нас получилось! Это говорит нам, что если бы мы увеличили w 1, L в результате увеличили бы tiiiny bit.
Теперь у нас есть все необходимые инструменты для обучения нейронной сети! Мы будем использовать алгоритм оптимизации, называемый стохастическим градиентным спуском (SGD), который сообщает нам, как изменить наши веса и смещения, чтобы минимизировать потери. По сути, это просто уравнение обновления:
η — это константа, называемая скоростью обучения , которая контролирует, насколько быстро мы тренируемся.Все, что мы делаем, это вычитаем η ∂ w 1 / ∂ L из w 1:
- Если ∂ L / ∂ w 1 положительно, w 1 уменьшится, что составит уменьшение L .
- Если ∂ L / ∂ w 1 отрицательно, w 1 увеличится, что приведет к уменьшению L .
Если мы сделаем это для каждого веса и смещения в сети, потери будут медленно уменьшаться, а наша сеть улучшится.
Наш процесс обучения будет выглядеть так:
- Выберите один образец из нашего набора данных. Это то, что делает его стохастическим градиентным спуском — мы работаем только с одним образцом за раз.
- Рассчитайте все частные производные потерь по весам или смещениям (например, ∂ L / ∂ w 1, ∂ L / ∂ w 2 и т. Д.).
- Используйте уравнение обновления для обновления каждого веса и смещения.
- Вернитесь к шагу 1.
Давайте посмотрим на это в действии!
Пришло время , наконец, , чтобы реализовать полную нейронную сеть:
Вы можете запускать / играть с этим кодом самостоятельно. Он также доступен на Github.
Наши потери неуклонно сокращаются по мере того, как сеть учится:
Теперь мы можем использовать сеть для предсказания пола:
Вы сделали это! Краткий обзор того, что мы сделали:
- Представлено нейронов , строительных блоков нейронных сетей.
- Используется сигмовидная активационная функция в наших нейронах.
- Видел, что нейронные сети — это просто нейроны, соединенные вместе.
- Создан набор данных с весом и ростом в качестве входных данных (или с характеристиками ) и полом в качестве выходных данных (или метка ).
- Узнал о функциях потерь и среднеквадратичной ошибке (MSE) потери.
- Понятно, что обучение сети сводит к минимуму ее потери.
- Используется обратного распространения ошибки для вычисления частных производных.
- Использовал стохастический градиентный спуск (SGD) для обучения нашей сети.
Еще многое предстоит сделать:
Я могу написать на эти или похожие темы в будущем, поэтому подпишитесь, если вы хотите получать уведомления о новых сообщениях.
Спасибо за чтение!
Приложения и алгоритмы искусственных нейронных сетей
Что такое искусственная нейронная сеть?
Искусственные нейронные сети — это вычислительные модели, созданные человеческим мозгом.Многие из недавних достижений были сделаны в области искусственного интеллекта, включая распознавание голоса, распознавание изображений, робототехнику с использованием искусственных нейронных сетей. Искусственные нейронные сети — это моделирование, основанное на биологической природе, выполняемое на компьютере для выполнения определенных конкретных задач, таких как: Искусственные нейронные сети, в целом — — это биологически вдохновленная сеть искусственных нейронов, сконфигурированных для выполнения определенных задач. Эти биологические методы вычислений известны как следующее крупное достижение в компьютерной индустрии.Что такое нейронная сеть?
Термин «нейронный» происходит от основной функциональной единицы нервной системы человека (животного) «нейрон» или нервных клеток, присутствующих в головном мозге и других частях тела человека (животного). Нейронная сеть — это группа алгоритмов, которые удостоверяют основную взаимосвязь в наборе данных, аналогичных человеческому мозгу. Нейронная сеть помогает изменить ввод так, чтобы сеть давала лучший результат без изменения процедуры вывода. Вы также можете узнать больше о ONNX в этом обзоре.Части нейрона и их функции
Типичная нервная клетка человеческого мозга состоит из четырех частей: Он получает сигналы от других нейронов. Он суммирует все входящие сигналы для генерации входных данных. Когда сумма достигает порогового значения, нейрон срабатывает, и сигнал проходит по аксону к другим нейронам. Точка соединения одного нейрона с другими нейронами. Количество передаваемого сигнала зависит от силы (синаптического веса) соединений. Связи могут быть тормозящими (уменьшение силы) или возбуждающими (увеличение силы) по своей природе.Итак, нейронная сеть, как правило, имеет связанную сеть из миллиардов нейронов с триллионом взаимосвязей между ними.В чем разница между компьютером и человеческим мозгом?
Искусственные нейронные сети (ИНС) и биологические нейронные сети (BNN) — Разница
| Характеристики | Искусственная нейронная сеть | Биологическая (реальная) нейронная сеть |
| Скорость | Более быстрая обработка информации.Время отклика в наносекундах. | Медленнее обрабатывает информацию. Время ответа в миллисекундах. |
| Обработка | Последовательная обработка. | Массовая параллельная обработка. |
| Размер и сложность | Меньше размера и сложности. Он не выполняет сложных задач распознавания образов. | Очень сложная и плотная сеть взаимосвязанных нейронов, содержащая нейроны порядка 1011 с 1015 взаимосвязями.<сильный |
| Хранилище | Хранилище информации заменяемое — это замена новых данных на старые. | Очень сложная и плотная сеть взаимосвязанных нейронов, содержащая нейроны порядка 1011 с 1015 взаимосвязями. |
| Отказоустойчивость | Устойчивый к отказам. Поврежденная информация не может быть восстановлена в случае отказа системы. | Хранение информации является адаптируемым, это означает, что новая информация добавляется путем корректировки силы межсоединений без уничтожения старой информации. |
| Механизм управления | Есть блок управления вычислительной деятельностью | Нет специального механизма управления, внешнего по отношению к вычислительной задаче. |
Искусственные нейронные сети с биологической нейронной сетью — подобие
Нейронные сети напоминают человеческий мозг двумя способами:- Нейронная сеть приобретает знания в процессе обучения.
- Знания нейронной сети — это хранилище в пределах силы межнейронных связей, известных как синаптические веса.
ВЫЧИСЛЕНИЯ НА ОСНОВЕ АРХИТЕКТУРЫ ФОН НЕЙМАНА | ВЫЧИСЛЕНИЯ НА ОСНОВЕ ИНН |
| Последовательная обработка — инструкция обработки и правило проблемы по одному (последовательная) | Параллельная обработка — несколько процессоров работают одновременно (многозадачность) |
| Логическая работа с набором правил if и else — подход на основе правил | Функция путем обучения шаблону на заданном входе (изображение, текст, видео и т. Д.)) |
| Программируется языками более высокого уровня, такими как C, Java, C ++ и т. Д. | ИНС — это, по сути, сама программа. |
| Требуются либо большие, либо подверженные ошибкам параллельные процессоры | Использование специализированных мультичипов. |
Искусственная нейронная сеть (ИНС) с биологической нейронной сетью (BNN) — Сравнение
- Дендриты биологической нейронной сети аналогичны взвешенным входам, основанным на их синаптических взаимосвязях в искусственной нейронной сети.
- Тело клетки сравнимо с блоком искусственного нейрона в искусственной нейронной сети, состоящим из блока суммирования и порогового значения.
- Axon передает вывод, аналогичный блоку вывода в случае искусственной нейронной сети. Итак, ИНС — это модель, использующая работу основных биологических нейронов.
Как работает искусственная нейронная сеть?
- Искусственные нейронные сети можно рассматривать как взвешенные ориентированные графы, в которых искусственные нейроны являются узлами, а направленные ребра с весами являются связями между выходами нейронов и входами нейронов.
- Искусственная нейронная сеть получает информацию из внешнего мира в виде рисунков и изображений в векторной форме. Эти входы обозначаются обозначением x (n) для количества входов n.
- Каждый вход умножается на соответствующие веса. Веса — это информация, используемая нейронной сетью для решения проблемы. Обычно вес представляет собой силу взаимосвязи между нейронами внутри нейронной сети.
- Все взвешенные входные данные суммируются внутри вычислительного блока (искусственного нейрона).В случае, если взвешенная сумма равна нулю, добавляется смещение, чтобы выходной сигнал не был нулевым, или для увеличения отклика системы. У смещения вес и вход всегда равны «1».
- Сумма соответствует любому числовому значению от 0 до бесконечности. Чтобы ограничить отклик до желаемого значения, устанавливается пороговое значение. Для этого сумма пересылается через функцию активации.
- Функция активации настроена на передаточную функцию для получения желаемого результата. Существуют как линейные, так и нелинейные функции активации.
Какие функции активации обычно используются?
Некоторые из часто используемых функций активации — это бинарные, сигмоидальные (линейные) и желтовато-гиперболические сигмоидальные функции (нелинейные).- Двоичный — Выход имеет только два значения, либо 0, либо 1. Для этого устанавливается пороговое значение. Если чистый взвешенный вход больше 1, выход считается равным единице, в противном случае — нулю.
- Сигмоидальная гиперболическая — Эта функция имеет S-образную кривую.Здесь гиперболическая функция tan используется для аппроксимации выхода из чистого входа. Функция определяется как — f (x) = (1/1 + exp (- ???? x)), где ???? — параметр крутизны.
Щелкните, чтобы прочитать о Обзор искусственного интеллекта и роли НЛП в больших данных
Типы нейронных сетей в искусственном интеллекте
| Параметр | Типы | Описание |
| По схеме подключения | FeedForward, рекуррентный | Feedforward — В графиках нет циклов. Recurrent — Зацикливание происходит из-за обратной связи. |
| По количеству скрытых слоев | Однослойный, многослойный | Однослойный — Имеет один секретный слой. Например, Single Perceptron Multilayer — Имеет несколько секретных слоев. Многослойный персептрон |
| По характеру весов | Фиксированный, Адаптивный | Фиксированный — Вес имеет фиксированный приоритет и не изменяется вообще. Adaptive — Обновляет веса и изменения во время тренировки. |
| На основе блока памяти | Статический, Динамический | Статический — Блок без памяти. Текущий выход зависит от текущего входа. Например, сеть прямого распространения. Dynamic — Блок памяти — Выход зависит как от токового входа, так и от токового выхода. Например, рекуррентная нейронная сеть |
Типы архитектуры нейронной сети
Модель персептрона в нейронных сетях
Нейронная сеть с радиальной базисной функцией
Многослойная нейронная сеть персептрона
Нейронная сеть с кратковременной памятью (LSTM)
Машинная нейронная сеть Больцмана
Сверточная нейронная сеть
Нажмите, чтобы изучить Генеративные состязательные сети
Аппаратная архитектура для нейронных сетей
Для реализации оборудования для нейронных сетей используются два типа методов.- Программное моделирование на обычном компьютере
- Специальное аппаратное решение для сокращения времени выполнения.
Методы обучения в искусственных нейронных сетях
Нейронная сеть обучается, итеративно регулируя свои веса и смещение (порог), чтобы получить желаемый результат. Их также называют свободными параметрами. Чтобы обучение происходило, сначала обучается нейронная сеть. Обучение выполняется с использованием определенного набора правил, также известного как алгоритм обучения.Алгоритмы обучения искусственных нейронных сетей
Алгоритм градиентного спуска
Алгоритм обратного распространения
Наборы обучающих данных в искусственных нейронных сетях
Набор примеров, используемых для обучения, должен соответствовать параметрам [т. Е. Весам] сети. Один подход включает один полный цикл тренировки на тренировочной выборке. Набор примеров, используемых для настройки параметров [т. Е. Архитектуры] сети. Например, чтобы выбрать количество скрытых блоков в нейронной сети. Набор примеров используется только для оценки производительности [обобщения] полностью определенной сети или успешно применяется для прогнозирования выходных данных, входные данные которых известны.Подробнее о Лучшие практики и платформы для капсульных сетей
Пять алгоритмов для обучения нейронной сети
- Правило обучения на хеббиане
- Правило Кохонена с самоорганизацией
- Закон о сети Хопфилда
- Алгоритм LMS (наименьшее среднеквадратичное значение)
- Конкурсное обучение
Архитектура искусственной нейронной сети
Типичная нейронная сеть содержит большое количество искусственных нейронов, называемых единицами, расположенными в серии слоев.Типичная искусственная нейронная сеть состоит из разных слоев —- Входной уровень — Он содержит те блоки (искусственные нейроны), которые получают входные данные из внешнего мира, на которых сеть будет узнавать, распознавать или иным образом обрабатывать.
- Выходной слой — Он содержит блоки, которые реагируют на информацию о том, как он изучает какую-либо задачу.
- Скрытый слой — Эти блоки находятся между входным и выходным слоями. Задача скрытого слоя — преобразовать ввод во что-то, что блок вывода может каким-то образом использовать.
Методы обучения в нейронных сетях
В этом обучении данные обучения вводятся в сеть, и желаемый результат известен, веса корректируются до тех пор, пока производство не даст желаемое значение. Используйте входные данные для обучения сети, выход которой известен. Сеть классифицирует входные данные и корректирует вес путем извлечения признаков во входных данных.Здесь выходное значение неизвестно, но сеть предоставляет обратную связь о том, является ли выход правильным или неправильным. Это полу-контролируемое обучение. Регулировка вектора весов и корректировка пороговых значений выполняются только после того, как обучающая выборка показана в сети. Это также называется пакетным обучением. Регулировка веса и порога выполняется после представления каждой обучающей выборки в сеть.Обучение и развитие в нейронных сетях
Обучение происходит, когда веса внутри сети обновляются после многих итераций.Например — предположим, что у нас есть входные данные в виде шаблонов для двух разных классов шаблонов — I & 0, как показано, и b-bias и y в качестве желаемого вывода.Узор | y | х1 | x2 | x3 | x4 | х5 | x6 | х7 | х8 | x9 | б |
I | 1 | 1 | 1 | 1 | –1 | 1 | –1 | 1 | 1 | 1 | 1 |
O | –1 | 1 | 1 | 1 | 1 | –1 | 1 | 1 | 1 | 1 | 1 |
- Девять входов от x1 — x9 и смещения b (вход со значением веса 1) подаются в сеть для первого шаблона.
- Изначально веса обнуляются.
- Затем веса обновляются для каждого нейрона по формулам: Δ wi = xi y для i = от 1 до 9 (Правило Хебба)
- Наконец, новые веса находятся по формулам:
- wi (новый) = wi (старый) + Δwi
- Wi (новый) = [111-11-1 1111]
- Второй шаблон вводится в сеть.На этот раз веса не обнуляются. Используемые здесь начальные веса — это окончательные веса, полученные после представления первого шаблона. Таким образом, network.
- Шаги с 1 по 4 повторяются для вторых входов.
- Новые веса: Wi (новый) = [0 0 0 -2 -2 -2 000]
Каковы 4 различных метода нейронных сетей?
Классификация нейронных сетей
Нейронная сеть прогнозирования
Кластеризация нейронной сети
- Конкурентные сети
- Сети теории адаптивного резонанса
- Самоорганизующиеся карты Кохонена.
Ассоциация нейронных сетей
Нейронные сети для распознавания образов
Распознавание образов — это исследование того, как машины могут наблюдать за окружающей средой, учатся отличать представляющие интерес паттерны от их фона и принимать обоснованные и разумные решения относительно категорий паттернов.Некоторые примеры шаблона: изображения отпечатков пальцев, рукописное слово, человеческое лицо или речевой сигнал. Учитывая шаблон ввода, его распознавание включает в себя следующую задачу —- Контролируемая классификация — Данный входной шаблон известен как член предопределенного класса.
- Неконтролируемая классификация — Присвойте шаблон неизвестному до сих пор классу.
- Сбор и предварительная обработка данных
- Представление данных
- Принятие решений
Подходы к распознаванию образов
- Соответствие шаблону
- Статистический
- Синтаксическое сопоставление
- Искусственные нейронные сети
- Многослойный персептрон
- Kohonen SOM (Самоорганизующаяся карта)
- Сеть радиальных базисных функций (RBF)
Нейронная сеть для глубокого обучения
Вслед за нейронной сетью в глубоком обучении используются архитектуры.- Нейронные сети с прямой связью
- Рекуррентная нейронная сеть
- Многослойный перцептрон (MLP)
- Сверточные нейронные сети
- Рекурсивные нейронные сети
- Сети глубоких убеждений
- Сверточные сети глубоких убеждений
- Самоорганизующиеся карты
- Станки глубокого Больцмана
- Составные автокодеры с шумоподавлением
Нейронные сети и нечеткая логика
Нечеткая логика относится к логике, разработанной для выражения степени правдивости путем присвоения значений от 0 до 1, в отличие от традиционной логической логики, представляющей 0 и 1.Нечеткая логика и нейронные сети имеют одну общую черту. Их можно использовать для решения задач распознавания образов и других задач, не связанных с математической моделью. Системы, сочетающие нечеткую логику и нейронные сети, являются нейронечеткими системами. Эти системы (гибридные) могут сочетать в себе преимущества как нейронных сетей, так и нечеткой логики, чтобы работать лучше. Нечеткая логика и нейронные сети были интегрированы для использования в следующих приложениях:- Автомобильная техника
- Отбор кандидатов на вакансии
- Управление краном
- Мониторинг глаукомы
Нейронная сеть для машинного обучения
- Многослойный персептрон (контролируемая классификация)
- Сеть обратного распространения (контролируемая классификация)
- Сеть Хопфилда (для ассоциации шаблонов)
- Глубокие нейронные сети (неконтролируемая кластеризация)
Каковы применения нейронных сетей?
Нейронные сети успешно применяются в широком спектре приложений с интенсивным использованием данных, таких как:| Приложение | Архитектура / алгоритм | Функция активации |
| Моделирование и управление процессами | Радиальная базовая сеть | Радиальное основание |
| Диагностика машины | Многослойный персептрон | Tan — сигмовидная функция |
| Управление портфелем | Алгоритм с контролируемой классификацией | Tan — сигмовидная функция |
| Распознавание целей | Модульная нейронная сеть | Tan — сигмовидная функция |
| Медицинский диагноз | Многослойный персептрон | Tan — сигмовидная функция |
| Кредитный рейтинг | Логистический дискриминантный анализ с использованием ИНС, машина опорных векторов | Логистическая функция |
| Целевой маркетинг | Алгоритм обратного распространения | Логистическая функция |
| Распознавание голоса | Многослойный персептрон, глубокие нейронные сети (сверточные нейронные сети) | Логистическая функция |
| Финансовое прогнозирование | Алгоритм обратного распространения ошибки | Логистическая функция |
| Интеллектуальный поиск | Глубокая нейронная сеть | Логистическая функция |
| Обнаружение мошенничества | Градиент — алгоритм спуска и алгоритм наименьшего среднего квадрата (LMS). | Логистическая функция |
Каковы преимущества нейронных сетей?
- Нейронная сеть может выполнять задачи, которые не могут выполнять линейные программы.
- Когда элемент нейронной сети выходит из строя, его параллельный характер может продолжаться без каких-либо проблем.
- Нейронная сеть обучается, и в перепрограммировании нет необходимости.
- Может быть реализован в любом приложении.
- Это может быть выполнено без проблем.
Каковы ограничения нейронных сетей?
- Для работы нейронной сети необходимо обучение.
- Архитектура нейронной сети отличается от архитектуры микропроцессоров. Следовательно, эмуляция необходима.
- Требуется большое время обработки для больших нейронных сетей.
Распознавание лиц с использованием искусственных нейронных сетей
Распознавание лиц влечет за собой сравнение изображения с базой данных сохраненных лиц для идентификации человека на этом входном изображении. Это механизм, который включает в себя разделение изображений на две части; один содержит цели (лица), а другой — фон.Соответствующее назначение обнаружения лиц имеет прямое отношение к тому факту, что изображения необходимо анализировать, а лица идентифицировать раньше, чем они могут быть распознаны.Правила обучения в нейронной сети
Правило обучения — это разновидность математической логики. Это побуждает нейронную сеть извлекать выгоду из текущих условий и повышать ее эффективность и производительность. Процедура обучения мозга изменяет его нервную структуру. Расширение или уменьшение качества его синаптических ассоциаций зависит от их активности.Правила обучения в нейронной сети:- Правило изучения еврейского языка; Он определяет, как настроить веса узлов системы.
- Правило обучения персептрона; Сеть начинает свое обучение с присвоения случайного значения каждой нагрузке.
- Правило обучения дельте; Изменение симпатрического веса узла равно умножению ошибки на вход.
- Правило обучения корреляции; Это похоже на обучение с учителем.
Чем вам может помочь XenonStack?
XenonStack может помочь вам разработать и развернуть ваши модельные решения на основе нейронных сетей.С какой бы проблемой вы не столкнулись — прогнозированием, классификацией или распознаванием образов — у XenonStack есть решение для вас.
Услуги по обнаружению и предотвращению мошенничества
XenonStack Fraud Detection Services предлагает анализ мошенничества в режиме реального времени для повышения прибыльности. Data Mining полезен для быстрого обнаружения мошенничества, поиска шаблонов и обнаружения мошеннических транзакций. Инструменты для интеллектуального анализа данных, такие как машинное обучение, нейронные сети, кластерный анализ, полезны для создания прогнозных моделей для предотвращения потерь от мошенничества.Услуги моделирования данных
XenonStack предлагает моделирование данных с использованием нейронных сетей, машинного обучения и глубокого обучения. Услуги моделирования данных помогают предприятиям создавать концептуальную модель на основе анализа объектов данных. Разверните свои модели данных на ведущих поставщиках облачных услуг, таких как Google Cloud, Microsoft Azure, AWS, или в контейнерной среде — Kubernetes и Docker.Что такое сверточные нейронные сети?
Сверточные нейронные сети очень важны в машинном обучении.Если вы хотите заниматься компьютерным зрением или распознаванием изображений, вы просто не можете обойтись без них. Но бывает сложно понять, как они работают.
В этом посте мы поговорим о механизмах, лежащих в основе сверточных нейронных сетей, их преимуществах и примерах использования в бизнесе.
Что такое нейронная сеть?
Во-первых, давайте освежим наши знания о том, как работают нейронные сети в целом.
Любая нейронная сеть, от простых перцептронов до огромных корпоративных AI-систем, состоит из узлов, имитирующих нейроны человеческого мозга.Эти клетки тесно связаны между собой. Узлы тоже.
Нейроны обычно организованы в независимые слои. Одним из примеров нейронных сетей являются сети с прямой связью. Данные перемещаются из входного слоя через набор скрытых слоев только в одном направлении, как вода через фильтры.
Каждый узел в системе связан с некоторыми узлами на предыдущем уровне и на следующем уровне. Узел получает информацию от нижележащего уровня, что-то делает с ней и отправляет информацию на следующий уровень.
Каждому входящему соединению присваивается вес. Это число, на которое узел умножает ввод, когда получает данные от другого узла.
Обычно узел работает с несколькими входящими значениями. Затем он суммирует все вместе.
Есть несколько возможных способов решить, следует ли передавать ввод на следующий уровень. Например, если вы используете функцию единичного шага, узел не передает данные на следующий уровень, если его значение ниже порогового значения.Если число превышает пороговое значение, узел отправляет число вперед. Однако в других случаях нейрон может просто проецировать входные данные в некоторый сегмент фиксированного значения.
Когда нейронная сеть обучается впервые, все ее веса и пороги назначаются случайным образом. Как только обучающие данные поступают на входной уровень, они проходят через все слои и, наконец, поступают на выход. Во время обучения веса и пороги корректируются до тех пор, пока данные обучения с одинаковыми метками не будут давать одинаковые выходные данные.Это называется обратным распространением. Вы можете увидеть, как это работает, в TensorFlow Playground.
Вы можете узнать больше о нейронных сетях во вводной статье о глубоком обучении.
В чем проблема простых сетевых сетей?
Обычные искусственные нейронные сети плохо масштабируются. Например, в CIFAR, наборе данных, который обычно используется для обучения моделей компьютерного зрения, изображения имеют размер только 32×32 пикселей и имеют 3 цветовых канала. Это означает, что один полностью связанный нейрон в первом скрытом слое этой нейронной сети будет иметь вес 32x32x3 = 3072.Это все еще управляемо. А теперь представьте изображение побольше, например, 300x300x3. У него было бы 270 000 весов (обучение которых требует огромных вычислительных мощностей)!
Такая огромная нейронная сеть требует много ресурсов, но даже в этом случае остается склонной к переобучению, поскольку большое количество параметров позволяет ей просто запоминать набор данных.
CNN используют совместное использование параметров. Все нейроны в конкретной карте функций имеют одинаковые веса, что снижает вычислительную нагрузку всей системы.
Как работает CNN?
Сверточная нейронная сеть или ConvNet — это просто нейронная сеть, использующая свертку. Чтобы понять принцип, сначала мы будем работать с двумерной сверткой.
Что такое свертка?
Свертка — это математическая операция, позволяющая объединить два набора информации. В случае CNN свертка применяется к входным данным для фильтрации информации и создания карты признаков.
Этот фильтр также называется ядром или детектором признаков, и его размеры могут быть, например, 3×3. Чтобы выполнить свертку, ядро просматривает входное изображение, выполняя матричное умножение элемент за элементом. Результат для каждого воспринимающего поля (область, в которой происходит свертка) записывается на карте признаков.
Мы продолжаем сдвигать фильтр, пока карта функций не будет завершена.
Набивка и шаг
Прежде чем мы продолжим, полезно также поговорить о отступах и шагах.Эти методы часто используются в CNN:
- Набивка. Padding расширяет входную матрицу, добавляя поддельные пиксели к границам матрицы. Это сделано потому, что свертка уменьшает размер матрицы. Например, матрица 5×5 превращается в матрицу 3×3, когда над ней проходит фильтр.
- Шагающий. Часто бывает, что при работе со сверточным слоем вам нужно получить на выходе меньший размер, чем на входе. Один из способов добиться этого — использовать слой объединения.Другой способ добиться этого — использовать шаг. Идея шага состоит в том, чтобы пропускать некоторые области при скольжении ядра: например, пропускать каждые 2 или 3 пикселя. Это снижает пространственное разрешение и делает сеть более эффективной с точки зрения вычислений.
Отступы и разметка помогают более точно обрабатывать изображения.
Для более подробного объяснения того, как работают CNN, посмотрите эту часть курса машинного обучения Брэндона Рорера.
Для реальных задач свертка обычно выполняется в 3D.Большинство изображений имеют 3 измерения: высоту, ширину и глубину, где глубина соответствует цветовым каналам (RGB). Таким образом, сверточный фильтр также должен быть трехмерным. Вот как эта же операция выглядит в 3D.
В сверточном слое есть несколько фильтров, и каждый из них генерирует карту фильтров. Следовательно, на выходе слоя будет набор карт фильтров, наложенных друг на друга.
Например, заполнение и передача матрицы 30x30x3 через 10 фильтров приведет к набору из 10 матриц 30x30x1.После того, как мы сложим эти карты друг на друга, у нас получится матрица 30x30x10.
Это результат нашего сверточного слоя.
Процесс можно повторить: CNN обычно имеют более одного сверточного слоя.
3 слоя CNN
Цель CNN — уменьшить изображения, чтобы их было легче обрабатывать без потери функций, которые имеют важное значение для точного прогнозирования.
АрхитектураConvNet имеет три типа уровней: сверточный уровень, уровень объединения и полносвязный уровень.
- Сверточный слой отвечает за распознавание элементов в пикселях.
- Слой объединения отвечает за то, чтобы сделать эти функции более абстрактными.
- Полностью связанный слой отвечает за использование полученных функций для прогнозирования.
Сверточный слой
Мы уже описали, как работают сверточные слои выше. Они находятся в центре CNN, что позволяет им автономно распознавать особенности изображений.
Но процесс свертки генерирует большой объем данных, что затрудняет обучение нейронной сети. Чтобы сжать данные, нам нужно пройти через пул.
Уровень объединения
Слой объединения получает результат от сверточного слоя и сжимает его. Фильтр слоя объединения всегда меньше, чем карта объектов. Обычно он берет квадрат 2×2 (патч) и сжимает его до одного значения.
Фильтр 2×2 уменьшит количество пикселей в каждой карте объектов до одной четверти размера.Если бы у вас была карта объектов размером 10 × 10, выходная карта была бы 5 × 5.
Для объединения можно использовать несколько различных функций. Это самые частые:
- Максимальный пул. Он вычисляет максимальное значение для каждого фрагмента карты функций.
- Средний пул. Он вычисляет среднее значение для каждого патча на карте функций.
После использования слоя объединения вы получаете объединенные карты объектов, которые представляют собой обобщенную версию объектов, обнаруженных во входных данных.Слой объединения повышает стабильность CNN: если раньше даже малейшие колебания в пикселях вызывали неправильную классификацию модели, то теперь небольшие изменения в расположении объекта на входе, обнаруженные сверточным слоем, приведут к объединенной карте объектов с функцией в там же.
Теперь нам нужно сгладить ввод (превратить его в вектор-столбец) и передать его в обычную нейронную сеть для классификации.
Полностью связанный слой
Сглаженный вывод подается в нейронную сеть с прямой связью, и обратное распространение применяется на каждой итерации обучения.Этот уровень дает модели возможность окончательно понимать изображения: существует поток информации между каждым входным пикселем и каждым выходным классом.
Преимущества сверточных нейронных сетей
Сверточные нейронные сети обладают рядом преимуществ, которые делают их полезными для множества различных приложений. Если вы хотите увидеть их на практике, посмотрите это подробное объяснение от StatQuest.
Обучение функциям
CNNне требуют ручного проектирования функций: они могут понять важные функции во время обучения.Даже если вы работаете над совершенно новой задачей, вы можете использовать предварительно обученную CNN и, передавая ей данные, корректировать веса. CNN приспособится к новой задаче.
Вычислительная эффективность
CNN, благодаря процедуре свертки, намного более эффективны с точки зрения вычислений, чем обычные нейронные сети. CNN использует совместное использование параметров и уменьшение размерности, что упрощает и ускоряет развертывание моделей. Их можно оптимизировать для работы на любом устройстве, даже на смартфонах.
Высокая точность
Современные NN в классификации изображений не являются сверточными сетями, например, в преобразователях изображений. Тем не менее, CNN уже очень давно доминируют в большинстве случаев и задач, связанных с распознаванием изображений и видео и аналогичными задачами. Обычно они показывают более высокую точность, чем несверточные NN, особенно когда задействовано много данных.
Недостатки ConvNet
Однако ConvNet не идеальна.Даже если он кажется очень умным инструментом, он все равно подвержен атакам со стороны противника.
Состязательные атаки
Состязательные атаки — это случаи подачи в сеть «плохих» примеров (также называемых слегка измененными определенным образом изображениями), чтобы вызвать неправильную классификацию. Даже небольшой сдвиг в пикселях может свести с ума CNN. Например, преступники могут обмануть систему распознавания лиц на основе CNN и пройти незамеченными перед камерой.
Обучение с интенсивным использованием данных
Чтобы CNN продемонстрировали свою магическую силу, они требуют тонны обучающих данных.Эти данные нелегко собрать и предварительно обработать, что может стать препятствием для более широкого внедрения технологии. Вот почему даже сегодня существует всего несколько хороших предварительно обученных моделей, таких как GoogleNet, VGG, Inception, AlexNet. Большинство из них принадлежит глобальным корпорациям.
Для чего используются сверточные нейронные сети?
Сверточные нейронные сети используются во многих отраслях. Вот несколько распространенных примеров их использования в реальных приложениях.
Классификация изображений
Сверточные нейронные сети часто используются для классификации изображений.Распознавая ценные особенности, CNN может идентифицировать различные объекты на изображениях. Эта способность делает их полезными в медицине, например, для МРТ-диагностики. CNN также можно использовать в сельском хозяйстве. Сети получают изображения со спутников, таких как LSAT, и могут использовать эту информацию для классификации земель на основе уровня их обработки. Следовательно, эти данные можно использовать для прогнозирования уровня плодородия земель или разработки стратегии оптимального использования сельскохозяйственных угодий. Распознавание рукописных цифр — также одно из первых применений CNN для компьютерного зрения.
Обнаружение объекта
Беспилотные автомобили, системы наблюдения на базе искусственного интеллекта и умные дома часто используют CNN, чтобы иметь возможность идентифицировать и отмечать объекты. CNN может идентифицировать объекты на фотографиях и в режиме реального времени, классифицировать и маркировать их. Таким образом автоматизированное транспортное средство объезжает другие автомобили и пешеходов, а умные дома узнают лицо хозяина среди всех остальных.
Аудиовизуальное сопоставление
YouTube, Netflix и другие сервисы потокового видео используют аудиовизуальное сопоставление для улучшения своих платформ.Иногда запросы пользователя могут быть очень конкретными, например, «фильмы про зомби в космосе», но поисковая система должна удовлетворять даже такие экзотические запросы.
Реконструкция объекта
CNN можно использовать для 3D моделирования реальных объектов в цифровом пространстве. Сегодня существуют модели CNN, которые создают трехмерные модели лиц на основе всего одного изображения. Подобные технологии можно использовать для создания цифровых двойников, которые пригодятся в архитектуре, биотехнологиях и производстве.
Распознавание речи
Хотя CNN часто используются для работы с изображениями, это не единственное возможное их применение.ConvNet может помочь с распознаванием речи и обработкой естественного языка. Например, технология распознавания речи Facebook основана на сверточных нейронных сетях.