Нейронные сети для начинающих. Часть 1 / Хабр
Привет всем читателям Habrahabr, в этой статье я хочу поделиться с Вами моим опытом в изучении нейронных сетей и, как следствие, их реализации, с помощью языка программирования Java, на платформе Android. Мое знакомство с нейронными сетями произошло, когда вышло приложение Prisma. Оно обрабатывает любую фотографию, с помощью нейронных сетей, и воспроизводит ее с нуля, используя выбранный стиль. Заинтересовавшись этим, я бросился искать статьи и «туториалы», в первую очередь, на Хабре. И к моему великому удивлению, я не нашел ни одну статью, которая четко и поэтапно расписывала алгоритм работы нейронных сетей. Информация была разрознена и в ней отсутствовали ключевые моменты. Также, большинство авторов бросается показывать код на том или ином языке программирования, не прибегая к детальным объяснениям.
Поэтому сейчас, когда я достаточно хорошо освоил нейронные сети и нашел огромное количество информации с разных иностранных порталов, я хотел бы поделиться этим с людьми в серии публикаций, где я соберу всю информацию, которая потребуется вам, если вы только начинаете знакомство с нейронными сетями.
Первым и самым важным моим открытием был плейлист американского программиста Джеффа Хитона, в котором он подробно и наглядно разбирает принципы работы нейронных сетей и их классификации. После просмотра этого плейлиста, я решил создать свою нейронную сеть, начав с самого простого примера. Вам наверняка известно, что когда ты только начинаешь учить новый язык, первой твоей программой будет Hello World. Это своего рода традиция. В мире машинного обучения тоже есть свой Hello world и это нейросеть решающая проблему исключающего или(XOR).
| a | b | c |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Соответственно, нейронная сеть берет на вход два числа и должна на выходе дать другое число — ответ. Теперь о самих нейронных сетях.
Что такое нейронная сеть?
Нейронная сеть — это последовательность нейронов, соединенных между собой синапсами. Структура нейронной сети пришла в мир программирования прямиком из биологии. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Нейронные сети также способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти. Заинтересовавшимся обязательно к просмотру 2 видео из TED Talks: Видео 1, Видео 2). Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Какие бывают нейронные сети?
Пока что мы будем рассматривать примеры на самом базовом типе нейронных сетей — это сеть прямого распространения (далее СПР). Также в последующих статьях я введу больше понятий и расскажу вам о рекуррентных нейронных сетях. СПР как вытекает из названия это сеть с последовательным соединением нейронных слоев, в ней информация всегда идет только в одном направлении.
Для чего нужны нейронные сети?
Нейронные сети используются для решения сложных задач, которые требуют аналитических вычислений подобных тем, что делает человеческий мозг. Самыми распространенными применениями нейронных сетей является:
Классификация — распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд.
Предсказание
Распознавание — в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое.
Теперь, чтобы понять, как же работают нейронные сети, давайте взглянем на ее составляющие и их параметры.
Что такое нейрон?
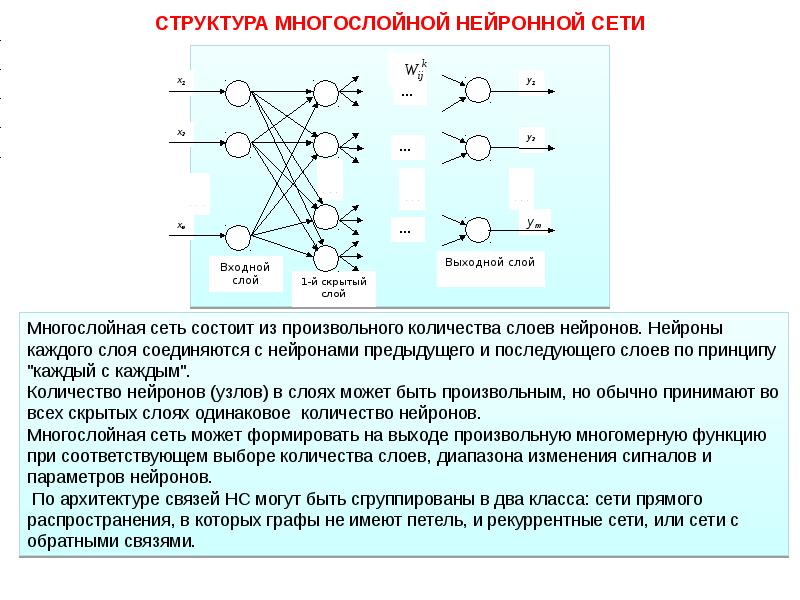
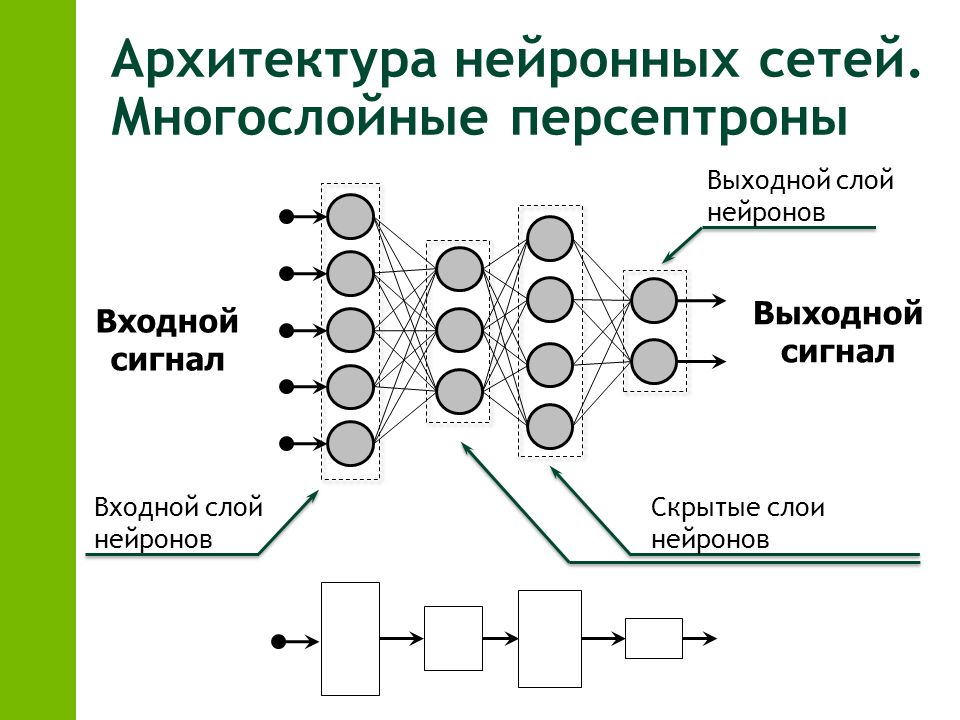
Нейрон — это вычислительная единица, которая получает информацию, производит над ней простые вычисления и передает ее дальше. Они делятся на три основных типа: входной (синий), скрытый (красный) и выходной (зеленый). Также есть нейрон смещения и контекстный нейрон о которых мы поговорим в следующей статье. В том случае, когда нейросеть состоит из большого количества нейронов, вводят термин слоя. Соответственно, есть входной слой, который получает информацию, n скрытых слоев (обычно их не больше 3), которые ее обрабатывают и выходной слой, который выводит результат.
Важно помнить
, что нейроны оперируют числами в диапазоне [0,1] или [-1,1]. А как же, вы спросите, тогда обрабатывать числа, которые выходят из данного диапазона? На данном этапе, самый простой ответ — это разделить 1 на это число. Этот процесс называется нормализацией, и он очень часто используется в нейронных сетях. Подробнее об этом чуть позже.
Что такое синапс?
Синапс это связь между двумя нейронами. У синапсов есть 1 параметр — вес. Благодаря ему, входная информация изменяется, когда передается от одного нейрона к другому. Допустим, есть 3 нейрона, которые передают информацию следующему. Тогда у нас есть 3 веса, соответствующие каждому из этих нейронов.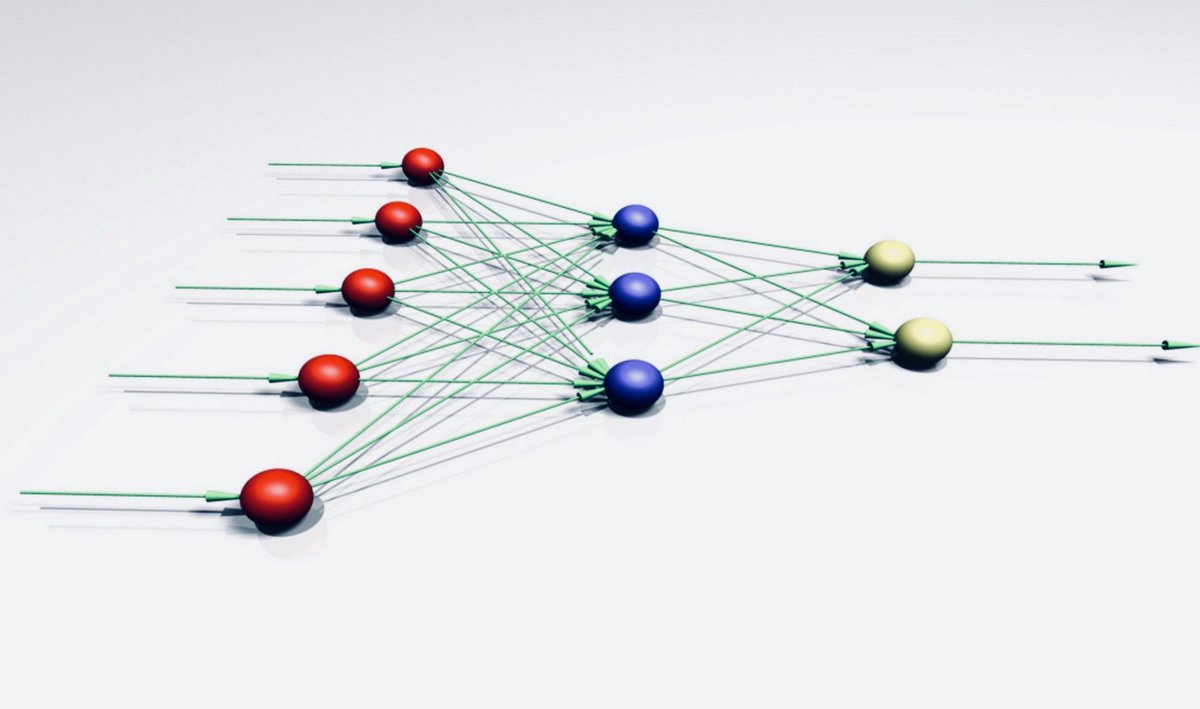
Важно помнить, что во время инициализации нейронной сети, веса расставляются в случайном порядке.
Как работает нейронная сеть?
В данном примере изображена часть нейронной сети, где буквами I обозначены входные нейроны, буквой H — скрытый нейрон, а буквой w — веса. Из формулы видно, что входная информация — это сумма всех входных данных, умноженных на соответствующие им веса. Тогда дадим на вход 1 и 0. Пусть w1=0.4 и w2 = 0.7 Входные данные нейрона Н1 будут следующими: 1*0.4+0*0.7=0.4. Теперь когда у нас есть входные данные, мы можем получить выходные данные, подставив входное значение в функцию активации (подробнее о ней далее). Теперь, когда у нас есть выходные данные, мы передаем их дальше.
Функция активации
Функция активации — это способ нормализации входных данных (мы уже говорили об этом ранее). То есть, если на входе у вас будет большое число, пропустив его через функцию активации, вы получите выход в нужном вам диапазоне. Функций активации достаточно много поэтому мы рассмотрим самые основные: Линейная, Сигмоид (Логистическая) и Гиперболический тангенс. Главные их отличия — это диапазон значений.
Линейная функция
Эта функция почти никогда не используется, за исключением случаев, когда нужно протестировать нейронную сеть или передать значение без преобразований.
Сигмоид
Это самая распространенная функция активации, ее диапазон значений [0,1]. Именно на ней показано большинство примеров в сети, также ее иногда называют логистической функцией. Соответственно, если в вашем случае присутствуют отрицательные значения (например, акции могут идти не только вверх, но и вниз), то вам понадобиться функция которая захватывает и отрицательные значения.
Именно на ней показано большинство примеров в сети, также ее иногда называют логистической функцией. Соответственно, если в вашем случае присутствуют отрицательные значения (например, акции могут идти не только вверх, но и вниз), то вам понадобиться функция которая захватывает и отрицательные значения.
Гиперболический тангенс
Имеет смысл использовать гиперболический тангенс, только тогда, когда ваши значения могут быть и отрицательными, и положительными, так как диапазон функции [-1,1]. Использовать эту функцию только с положительными значениями нецелесообразно так как это значительно ухудшит результаты вашей нейросети.
Тренировочный сет
Тренировочный сет — это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключающего или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.
Итерация
Это своеобразный счетчик, который увеличивается каждый раз, когда нейронная сеть проходит один тренировочный сет. Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.
Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.
Эпоха
При инициализации нейронной сети эта величина устанавливается в 0 и имеет потолок, задаваемый вручную. Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат. Эпоха увеличивается каждый раз, когда мы проходим весь набор тренировочных сетов, в нашем случае, 4 сетов или 4 итераций.
Важно
не путать итерацию с эпохой и понимать последовательность их инкремента. Сначала n
раз увеличивается итерация, а потом уже эпоха и никак не наоборот. Другими словами, нельзя сначала тренировать нейросеть только на одном сете, потом на другом и тд. Нужно тренировать каждый сет один раз за эпоху. Так, вы сможете избежать ошибок в вычислениях.
Ошибка
Ошибка — это процентная величина, отражающая расхождение между ожидаемым и полученным ответами. Ошибка формируется каждую эпоху и должна идти на спад. Если этого не происходит, значит, вы что-то делаете не так. Ошибку можно вычислить разными путями, но мы рассмотрим лишь три основных способа: Mean Squared Error (далее MSE), Root MSE и Arctan. Здесь нет какого-либо ограничения на использование, как в функции активации, и вы вольны выбрать любой метод, который будет приносить вам наилучший результат. Стоит лишь учитывать, что каждый метод считает ошибки по разному. У Arctan, ошибка, почти всегда, будет больше, так как он работает по принципу: чем больше разница, тем больше ошибка. У Root MSE будет наименьшая ошибка, поэтому, чаще всего, используют MSE, которая сохраняет баланс в вычислении ошибки.
Ошибку можно вычислить разными путями, но мы рассмотрим лишь три основных способа: Mean Squared Error (далее MSE), Root MSE и Arctan. Здесь нет какого-либо ограничения на использование, как в функции активации, и вы вольны выбрать любой метод, который будет приносить вам наилучший результат. Стоит лишь учитывать, что каждый метод считает ошибки по разному. У Arctan, ошибка, почти всегда, будет больше, так как он работает по принципу: чем больше разница, тем больше ошибка. У Root MSE будет наименьшая ошибка, поэтому, чаще всего, используют MSE, которая сохраняет баланс в вычислении ошибки.
MSE
Root MSE
Arctan
Принцип подсчета ошибки во всех случаях одинаков. За каждый сет, мы считаем ошибку, отняв от идеального ответа, полученный. Далее, либо возводим в квадрат, либо вычисляем квадратный тангенс из этой разности, после чего полученное число делим на количество сетов.
Задача
Теперь, чтобы проверить себя, подсчитайте результат, данной нейронной сети, используя сигмоид, и ее ошибку, используя MSE. 2)/1=0.45
2)/1=0.45
Результат — 0.33, ошибка — 45%.
Большое спасибо за внимание! Надеюсь, что данная статья смогла помочь вам в изучении нейронных сетей. В следующей статье, я расскажу о нейронах смещения и о том, как тренировать нейронную сеть, используя метод обратного распространения и градиентного спуска.
Использованные ресурсы:
— Раз
— Два
— Три
Что такое нейронные сети? — Российская Федерация
Нейронные сети имитируют работу человеческого мозга, позволяя компьютерным программам находить закономерности и решать стандартные задачи в области искусственного интеллекта (ИИ), машинного и глубокого обучения.
Что такое нейронные сети?
Нейронные сети, известные также как искусственные нейронные сети (ANN) или смоделированные нейронные сети (SNN), являются подмножеством алгоритмов машинного обучения и служат основой для алгоритмов глубокого обучения. Понятие «нейронные сети» возникло при попытке смоделировать процессы, происходящие в человеческом мозге при передаче сигналов между биологическими нейронами.
Искусственные нейронные сети (ANN) состоят из образующих слои узлов: слой входных данных, один или несколько скрытых слоев и слой выходных данных. Каждый узел (искусственный нейрон) связан с другими узлами с определенным весом и пороговым значением. Если вывод какого-либо узла превышает пороговое значение, то этот узел активируется и отправляет данные на следующий уровень сети. В противном случае данные на следующий уровень сети не передаются.
Для обучения и постепенного повышения точности нейронных сетей применяются обучающие данные. При достижении требуемой точности алгоритмы обучения превращаются в мощные инструменты для вычислений и искусственного интеллекта, что позволяет использовать их для классификации и кластеризации данных с высокой скоростью. Задачи из области распознавания речи или изображений можно выполнить за несколько минут, а не за несколько часов, как при распознавании вручную. Одной из наиболее известных нейронных сетей является алгоритм поиска Google.
Принцип работы нейронных сетей
Представим каждый отдельный узел в виде модели линейной регрессии, состоящей из входных данных, весовых коэффициентов, смещения (или порогового значения) и выходных данных. Эту модель можно описать следующей формулой:
∑wixi + bias = w1x1 + w2x2 + w3x3 + bias
output = f(x) = 1 if ∑w1x1 + b> = 0; 0 if ∑w1x1 + b < 0
После определения слоя входных данных необходимо назначить весовые коэффициенты. Они помогают определить важность той или иной переменной: чем выше весовой коэффициент, тем существеннее его вклад в выходные данные по сравнению с другими входными данными. Затем произведения входных данных и соответствующих им весовых коэффициентов суммируются. Наконец, выходные данные передаются через функцию активации, которая вычисляет результат. Если полученный результат превышает установленное пороговое значение, узел срабатывает (активируется), передавая данные на следующий слой сети. Выходные данные одного узла становятся входными данными для следующего узла.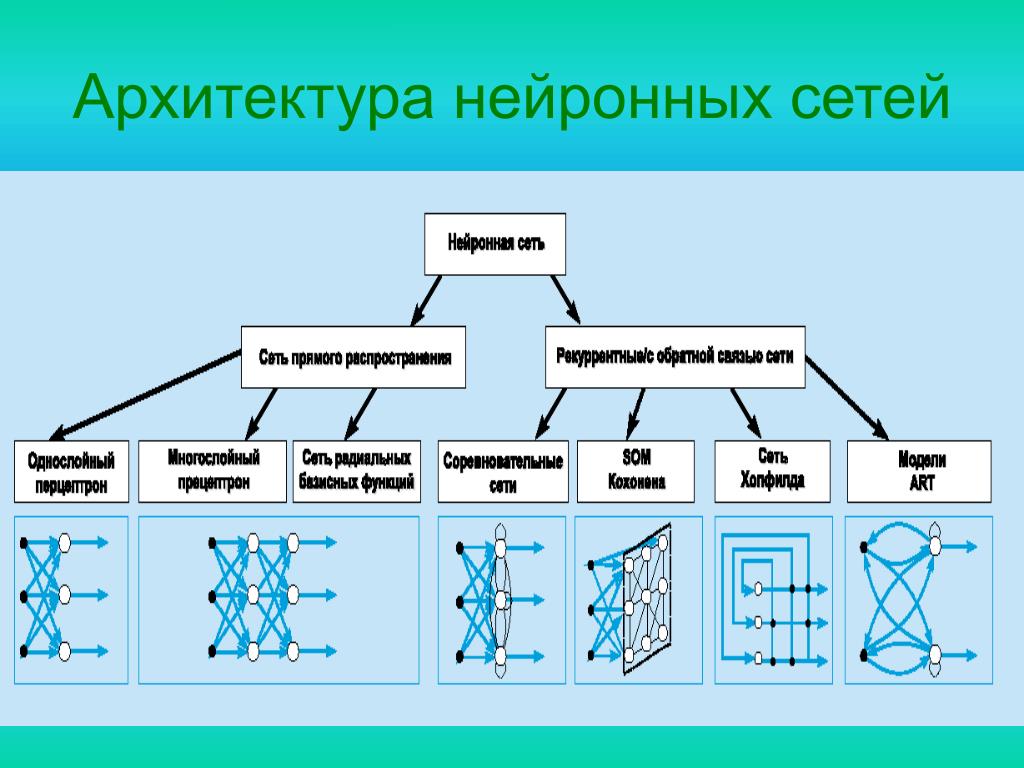 Такой последовательный процесс передачи данных между слоями характерен для нейронных сетей прямого распространения.
Такой последовательный процесс передачи данных между слоями характерен для нейронных сетей прямого распространения.
Попробуем представить отдельно взятый узел в виде двоичных чисел. Для более наглядной демонстрации этой концепции рассмотрим реальный пример: допустим, вам нужно принять решение, стоит ли идти на серфинг (Да: 1, Нет: 0). Решение «идти» или «не идти» — наш прогнозируемый результат или «y c крышечкой». Предположим, существует три фактора, которые влияют на принятие решения:
- Хорошие ли сегодня волны? (Да: 1, Нет: 0)
- Свободен ли лайнап? (Да: 1, Нет: 0)
- Были ли случаи нападения акул в последнее время? (Да: 0, Нет: 1)
Предположим, у нас имеются следующие входные данные:
- X1 = 1, так как сегодня хорошие волны для серфинга
- X2 = 0, так как уже собралось много серферов
- X3 = 1, так как в последнее время не было нападений акул
Теперь нам нужно присвоить весовые коэффициенты для определения важности. Чем выше значение весового коэффициента, тем большим будет влияние конкретной переменной на решение или результат.
Чем выше значение весового коэффициента, тем большим будет влияние конкретной переменной на решение или результат.
- W1 = 5, так как большие свеллы — редкость
- W2 = 2, так как вы уже привыкли к скоплению серферов
- W3 = 4, так как вы боитесь акул
Наконец, установим пороговое значение 3, т. е. величина смещения будет равна –3. Теперь, когда все входные данные готовы, можно подставить значения в формулу и получить желаемый результат.
Y-hat = (1*5) + (0*2) + (1*4) – 3 = 6
С помощью функции активации, о которой было сказано в начале раздела, можно вычислить выходные данные для этого узла: результат равен 1, так как 6 больше 0. Это означает, что нам стоит идти на серфинг; если же изменить весовые коэффициенты или пороговое значение, результат вычисления для данной модели может отличаться. Из примера, приведенного выше, следует, что нейронная сеть способна принимать решения с возрастающей степенью сложности, в зависимости от выходных данных предыдущих решений или слоев.
В предыдущем примере для иллюстрации математических понятий были использованы персептроны, в то время как в нейронных сетях применяются сигмоидальные нейроны, значения которых могут находиться в диапазоне от 0 до 1. По своему принципу работы нейронные сети схожи с деревьями принятия решений, поэтому в результате передачи данных от одного узла к другому, при x значений от 0 до 1, влияние того или иного изменения отдельной переменной на выходные данные любого узла и, следовательно, выходные данные нейронной сети уменьшается.
Когда речь заходит о более практических сценариях использования нейронных сетей, например распознавание или классификация изображений, то для обучения алгоритма используется контролируемое обучение или маркированные наборы данных. В ходе обучения модели нам потребуется оценить точность с помощью функции стоимости (или потерь). Это так называемая среднеквадратическая ошибка (MSE). В уравнении ниже используются следующие обозначения:
- i обозначает индекс выборки,
- y-hat («y c крышечкой») обозначает прогнозируемый результат,
- y обозначает фактическое значение,
- m обозначает число выборок.
 2
2Конечная цель — минимизировать функцию стоимости, чтобы обеспечить корректность для каждого отдельно взятого наблюдения. В процессе корректировки весовых коэффициентов и смещения модель использует функцию стоимости и обучение с подкреплением для достижения точки сходимости или локального минимума. Корректировка весовых коэффициентов происходит с помощью алгоритма градиентного спуска, что позволяет определить стратегию уменьшения количества ошибок (или минимизации функции стоимости). С каждым шагом обучения параметры модели корректируются, пока не будет достигнут минимум.
Для более подробного изучения математических понятий, используемых в нейронных сетях, рекомендуем прочитать статью на сайте IBM Developer.
Большинство глубоких нейронных сетей относятся к алгоритмам прямого распространения, т. е. данные передаются только в одном направлении — от входа к выходу. Однако для обучения моделей может также применяться метод обратного распространения ошибки, когда данные передаются в противоположном направлении — от выхода к входу.
Метод обратного распространения ошибки позволяет вычислить и объяснить ошибки, связанные с каждым нейроном, что позволяет скорректировать и адаптировать параметры модели соответствующим образом.Виды нейронных сетей
Нейронные сети можно разделить на несколько видов, в зависимости от целевого назначения. Вот список наиболее распространенных видов нейронных сетей, имеющих практическое применение:
Персептрон — первая нейронная сеть, созданная Фрэнком Розентблаттом в 1958 году. Она содержит один нейрон и представляет собой простейшую форму нейронной сети:
Эта статья посвящена в основном нейронным сетям прямого распространения или многослойным персептронам (MLP). Они состоят из следующих слоев: входные данные, один или несколько скрытых слоев и выходные данные. Хотя такие нейронные сети формально относятся к категории MLP, фактически они состоят из сигмоидальных нейронов, а не персептронов, так как большинство реальных задач нелинейны. Данные, поступающие в эти модели, используются для обучения; они лежат в основе алгоритмов компьютерного зрения, обработки данных на естественном языке и других нейронных сетей.
Сверточные нейронные сети (CNN) похожи на сети прямого распространения, однако они, как правило, применяются для распознавания изображений, выявления закономерностей и/или компьютерного зрения. Для обнаружения закономерностей в изображениях с помощью таких сетей применяются законы линейной алгебры, в частности правила перемножения матриц.
Рекуррентные нейронные сети (RNN) имеют в своем составе обратные связи. Такие алгоритмы обучения используются в основном для временных рядов данных с целью прогнозирования будущих событий, например стоимости акций на фондовых биржах или объема продаж.
Сравнение нейронных сетей и глубокого обучения
В обычном разговоре термины «глубокое обучение» и «нейронные сети» могут использоваться как синонимы, загоняя собеседников в тупик. Поэтому стоит отметить, что понятие «глубина» в «глубоком обучении» характеризует лишь количество слоев нейронной сети. Нейронную сеть, в составе которой более трех слоев (включая слой входных данных и слой выходных данных), можно отнести к алгоритмам глубокого обучения. Нейронная сеть с двумя-тремя уровнями считается простой нейронной сетью.
Для лучшего понимания разницы между нейронными сетями и другими разновидностями искусственного интеллекта, например машинным обучением, рекомендуем прочитать публикацию в блоге «Сравнение искусственного интеллекта, машинного обучения, глубокого обучения и нейронных сетей».
История возникновения нейронных сетей
История нейронных сетей намного длиннее, чем принято считать. Сама идея «способной к мышлению системы» возникла еще в Древней Греции, и популярность нейронных сетей менялась с течением времени. Мы же сосредоточимся на ключевых событиях современной эволюции:
1943: Уоррен Маккалок и Уолтер Питтс опубликовали работу «Логическое исчисление идей, относящихся к нервной деятельности» (внешняя ссылка, PDF, 1 МБ). Целью данного исследования было изучение работы человеческого мозга, а именно: создание сложных моделей путем передачи сигналов клетками мозга или нейронами. Одной из главных идей, возникших в ходе данного исследования, стала аналогия между нейронами с двоичным пороговым значением и булевской логикой (значения 0/1 или утверждения истина/ложь).
1958: Фрэнк Розенблатт в своем исследовании «Персептрон: вероятностная модель хранения и организации информации в головном мозге» (внешняя ссылка, PDF, 1,6 МБ) описал модель персептрона. Он развил идеи Маккалока и Питтса, добавив в формулу весовые коэффициенты. На компьютере IBM 704 Розенблатт смог обучить систему распознавать карточки, маркированные слева и справа.
1974: первым ученым на территории США, описавшим в своей диссертации (внешняя ссылка, PDF, 8,1 МБ) использование алгоритма обратного распространения ошибки в нейронных сетях, стал Пол Вербос, хотя развитием этой идеи занимались многие исследователи.
1989: Янн Лекун опубликовал статью (внешняя ссылка, PDF, 5,7 МБ), в которой было описано практическое использование ограничений обратного распространения ошибки и интеграция в архитектуру нейронной сети для обучения алгоритмов. В данном исследовании нейронная сеть успешно обучилась распознавать рукописные символы почтового индекса, предоставленные Почтовой службой США.
Нейронные сети и IBM Cloud
Компания IBM стоит у истоков развития ИИ-технологий и нейронных сетей, о чем свидетельствуют появление и эволюция IBM Watson. Watson — надежное решение для крупных предприятий, которым требуется внедрить передовые технологии глубокого обучения и обработки данных на естественном языке в свои системы, опираясь на проверенный многоуровневый подход к разработке и реализации ИИ.
Архитектура UIMA (Apache Unstructured Information Management Architecture) и программное обеспечение IBM DeepQA, лежащие в основе Watson, позволяют интегрировать в приложения мощные функции глубокого обучения. С помощью таких инструментов, как IBM Watson Studio, ваше предприятие сможет эффективно перенести ИИ-проекты с открытым исходным кодом в рабочую среду с возможностью развертывания и выполнения моделей в любой облачной среде.
Более подробная информация о том, как приступить к использованию технологии глубокого обучения, приведена на страницах IBM Watson Studio и Deep Learning service.
Получите IBMid и создайте учетную запись IBM Cloud.
Нейросети: что это такое и как работает | Будущее, Наука
За последнюю пару лет искусственный интеллект незаметно отряхнулся от тегов «фантастика» и «геймдизайн» и прочно прописался в ежедневных новостных лентах. Сущности под таинственным названием «нейросети» опознают людей по фотографиям, водят автомобили, играют в покер и совершают научные открытия. При этом из новостей не всегда понятно, что же такое эти загадочные нейросети: сложные программы, особые компьютеры или стойки со стройными рядами серверов?
Конечно, уже из названия можно догадаться, что в нейросетях разработчики попытались скопировать устройство человеческого мозга: как известно, он состоит из множества простых клеток-нейронов, которые обмениваются друг с другом электрическими сигналами. Но чем тогда нейросети отличаются от обычного компьютера, который тоже собран из примитивных электрических деталей? И почему до современного подхода не додумались ещё полвека назад?
Давайте попробуем разобраться, что же кроется за словом «нейросети», откуда они взялись — и правда ли, что компьютеры прямо на наших глазах постепенно обретают разум.
Идея нейросети заключается в том, чтобы собрать сложную структуру из очень простых элементов. Вряд ли можно считать разумным один-единственный участок мозга — а вот люди обычно на удивление неплохо проходят тест на IQ. Тем не менее до сих пор идею создания разума «из ничего» обычно высмеивали: шутке про тысячу обезьян с печатными машинками уже сотня лет, а при желании критику нейросетей можно найти даже у Цицерона, который ехидно предлагал до посинения подбрасывать в воздух жетоны с буквами, чтобы рано или поздно получился осмысленный текст. Однако в XXI веке оказалось, что классики ехидничали зря: именно армия обезьян с жетонами может при должном упорстве захватить мир.
Красота начинается, когда нейронов много
На самом деле нейросеть можно собрать даже из спичечных коробков: это просто набор нехитрых правил, по которым обрабатывается информация. «Искусственным нейроном», или перцептроном, называется не какой-то особый прибор, а всего лишь несколько арифметических действий.
Работает перцептрон проще некуда: он получает несколько исходных чисел, умножает каждое на «ценность» этого числа (о ней чуть ниже), складывает и в зависимости от результата выдаёт 1 или –1. Например, мы фотографируем чистое поле и показываем нашему нейрону какую-нибудь точку на этой картинке — то есть посылаем ему в качестве двух сигналов случайные координаты. А затем спрашиваем: «Дорогой нейрон, здесь небо или земля?» — «Минус один, — отвечает болванчик, безмятежно разглядывая кучевое облако. — Ясно же, что земля».
«Тыкать пальцем в небо» — это и есть основное занятие перцептрона. Никакой точности от него ждать не приходится: с тем же успехом можно подбросить монетку. Магия начинается на следующей стадии, которая называется машинным обучением. Мы ведь знаем правильный ответ — а значит, можем записать его в свою программу. Вот и получается, что за каждую неверную догадку перцептрон в буквальном смысле получает штраф, а за верную — премию: «ценность» входящих сигналов вырастает или уменьшается. После этого программа прогоняется уже по новой формуле. Рано или поздно нейрон неизбежно «поймёт», что земля на фотографии снизу, а небо сверху, — то есть попросту начнёт игнорировать сигнал от того канала, по которому ему передают x-координаты. Если такому умудрённому опытом роботу подсунуть другую фотографию, то линию горизонта он, может, и не найдёт, но верх с низом уже точно не перепутает.
Чтобы нарисовать прямую линию, нейрон исчеркает весь лист
В реальной работе формулы немного сложнее, но принцип остаётся тем же. Перцептрон умеет выполнять только одну задачу: брать числа и раскладывать по двум стопкам. Самое интересное начинается тогда, когда таких элементов несколько, ведь входящие числа могут быть сигналами от других «кирпичиков»! Скажем, один нейрон будет пытаться отличить синие пиксели от зелёных, второй продолжит возиться с координатами, а третий попробует рассудить, у кого из этих двоих результаты ближе к истине. Если же натравить на синие пиксели сразу несколько нейронов и суммировать их результаты, то получится уже целый слой, в котором «лучшие ученики» будут получать дополнительные премии. Таким образом достаточно развесистая сеть может перелопатить целую гору данных и учесть при этом все свои ошибки.
Перцептроны устроены не намного сложнее, чем любые другие элементы компьютера, которые обмениваются единицами и нулями. Неудивительно, что первый прибор, устроенный по принципу нейросети — Mark I Perceptron, — появился уже в 1958 году, всего через десятилетие после первых компьютеров. Как было заведено в ту эпоху, нейроны у этого громоздкого устройства состояли не из строчек кода, а из радиоламп и резисторов. Учёный Фрэнк Розенблатт смог соорудить только два слоя нейросети, а сигналы на «Марк-1» подавались с импровизированного экрана размером в целых 400 точек. Устройство довольно быстро научилось распознавать простые геометрические формы — а значит, рано или поздно подобный компьютер можно было обучить, например, чтению букв.
Розенблатт и его перцептрон
Розенблатт был пламенным энтузиастом своего дела: он прекрасно разбирался в нейрофизиологии и вёл в Корнеллском университете популярнейший курс лекций, на котором подробно объяснял всем желающим, как с помощью техники воспроизводить принципы работы мозга. Учёный надеялся, что уже через несколько лет перцептроны превратятся в полноценных разумных роботов: они смогут ходить, разговаривать, создавать себе подобных и даже колонизировать другие планеты. Энтузиазм Розенблатта вполне можно понять: тогда учёные ещё верили, что для создания ИИ достаточно воспроизвести на компьютере полный набор операций математической логики. Тьюринг уже предложил свой знаменитый тест, Айзек Азимов призывал задуматься о необходимости законов роботехники, а освоение Вселенной казалось делом недалёкого будущего.
Впрочем, были среди пионеров кибернетики и неисправимые скептики, самым грозным из которых оказался бывший однокурсник Розенблатта, Марвин Минский. Этот учёный обладал не менее громкой репутацией: тот же Азимов отзывался о нём с неизменным уважением, а Стэнли Кубрик приглашал в качестве консультанта на съёмки «Космической одиссеи 2001 года». Даже по работе Кубрика видно, что на самом деле Минский ничего не имел против нейросетей: HAL 9000 состоит именно из отдельных логических узлов, которые работают в связке друг с другом. Минский и сам увлекался машинным обучением ещё в 1950-х. Просто Марвин непримиримо относился к научным ошибкам и беспочвенным надеждам: недаром именно в его честь Дуглас Адамс назвал своего андроида-пессимиста.
В отличие от Розенблатта, Минский дожил до триумфа ИИ
Сомнения скептиков того времени Минский подытожил в книге «Перцептрон» (1969), которая надолго отбила у научного сообщества интерес к нейросетям. Минский математически доказал, что у «Марка-1» есть два серьёзных изъяна. Во-первых, сеть всего с двумя слоями почти ничего не умела — а ведь это и так уже был огромный шкаф, пожирающий уйму электричества. Во-вторых, для многослойных сетей алгоритмы Розенблатта не годились: по его формуле часть сведений об ошибках сети могла потеряться, так и не дойдя до нужного слоя.
Минский не собирался сильно критиковать коллегу: он просто честно отметил сильные и слабые стороны его проекта, а сам продолжил заниматься своими разработками. Увы, в 1971 году Розенблатт погиб — исправлять ошибки перцептрона оказалось некому. «Обычные» компьютеры в 1970-х развивались семимильными шагами, поэтому после книги Минского исследователи попросту махнули рукой на искусственные нейроны и занялись более перспективными направлениями.
Развитие нейросетей остановилось на десять с лишним лет — сейчас эти годы называют «зимой искусственного интеллекта». К началу эпохи киберпанка математики наконец-то придумали более подходящие формулы для расчёта ошибок, но научное сообщество поначалу не обратило внимания на эти исследования. Только в 1986 году, когда уже третья подряд группа учёных независимо от других решила обнаруженную Минским проблему обучения многослойных сетей, работа над искусственным интеллектом наконец-то закипела с новой силой.
Хотя правила работы остались прежними, вывеска сменилась: теперь речь шла уже не о «перцептронах», а о «когнитивных вычислениях». Экспериментальных приборов никто уже не строил: теперь все нужные формулы проще было записать в виде несложного кода на обычном компьютере, а потом зациклить программу. Буквально за пару лет нейроны научились собирать в сложные структуры. Например, некоторые слои искали на изображении конкретные геометрические фигуры, а другие суммировали полученные данные. Именно так удалось научить компьютеры читать человеческий почерк. Вскоре стали появляться даже самообучающиеся сети, которые не получали «правильные ответы» от людей, а находили их сами. Нейросети сразу начали использовать и на практике: программу, которая распознавала цифры на чеках, с удовольствием взяли на вооружение американские банки.
1993 год: капча уже морально устарела
К середине 1990-х исследователи сошлись на том, что самое полезное свойство нейросетей — их способность самостоятельно придумывать верные решения. Метод проб и ошибок позволяет программе самой выработать для себя правила поведения. Именно тогда стали входить в моду соревнования самодельных роботов, которых программировали и обучали конструкторы-энтузиасты. А в 1997 году суперкомпьютер Deep Blue потряс любителей шахмат, обыграв чемпиона мира Гарри Каспарова.
Строго говоря, Deep Blue не учился на своих ошибках, а попросту перебирал миллионы комбинаций
Увы, примерно в те же годы нейросети упёрлись в потолок возможностей. Другие области программирования не стояли на месте — вскоре оказалось, что с теми же задачами куда проще справляются обычные продуманные и оптимизированные алгоритмы. Автоматическое распознавание текста сильно упростило жизнь работникам архивов и интернет-пиратам, роботы продолжали умнеть, но разговоры об искусственном интеллекте потихоньку заглохли. Для действительно сложных задач нейросетям по-прежнему не хватало вычислительной мощности.
Вторая «оттепель» ИИ случилась, только когда изменилась сама философия программирования.
В последнее десятилетие программисты — да и простые пользователи — часто жалуются, что никто больше не обращает внимания на оптимизацию. Раньше код сокращали как могли — лишь бы программа работала быстрее и занимала меньше памяти. Теперь даже простейший интернет-сайт норовит подгрести под себя всю память и обвешаться «библиотеками» для красивой анимации.
Конечно, для обычных программ это серьёзная проблема, — но как раз такого изобилия и не хватало нейросетям! Учёным давно известно, что если не экономить ресурсы, самые сложные задачи начинают решаться словно бы сами собой. Ведь именно так действуют все законы природы, от квантовой физики до эволюции: если повторять раз за разом бесчисленные случайные события, отбирая самые стабильные варианты, то из хаоса родится стройная и упорядоченная система. Теперь в руках человечества наконец-то оказался инструмент, который позволяет не ждать изменений миллиарды лет, а обучать сложные системы буквально на ходу.
В последние годы никакой революции в программировании не случилось — просто компьютеры накопили столько вычислительной мощности, что теперь любой ноутбук может взять сотню нейронов и прогнать каждый из них через миллион циклов обучения. Оказалось, что тысяче обезьян с пишущими машинками просто нужен очень терпеливый надсмотрщик, который будет выдавать им бананы за правильно напечатанные буквы, — тогда зверушки не только скопируют «Войну и мир», но и напишут пару новых романов не хуже.
Так и произошло третье пришествие перцептронов — на этот раз уже под знакомыми нам названиями «нейросети» и «глубинное обучение». Неудивительно, что новостями об успехах ИИ чаще всего делятся такие крупные корпорации как Google и IBM. Их главный ресурс — огромные дата-центры, где на мощных серверах можно тренировать многослойные нейросети. Эпоха машинного обучения по-настоящему началась именно сейчас, потому что в интернете и соцсетях наконец-то накопились те самые big data, то есть гигантские массивы информации, которые и скармливают нейросетям для обучения.
В итоге современные сети занимаются теми трудоёмкими задачами, на которые людям попросту не хватило бы жизни. Например, для поиска новых лекарств учёным до сих пор приходилось долго высчитывать, какие химические соединения стоит протестировать. А сейчас существует нейросеть, которая попросту перебирает все возможные комбинации веществ и предлагает наиболее перспективные направления исследований. Компьютер IBM Watson успешно помогает врачам в диагностике: обучившись на историях болезней, он легко находит в данных новых пациентов неочевидные закономерности.
Люди классифицируют информацию с помощью таблиц, но нейросетям незачем ограничивать себя двумя измерениями — поэтому массивы данных выглядят примерно так
В сфере развлечений компьютеры продвинулись не хуже, чем в науке. За счёт машинного обучения им наконец поддались игры, алгоритмы выигрыша для которых придумать ещё сложнее, чем для шахмат. Недавно нейросеть AlphaGo разгромила одного из лучших в мире игроков в го, а программа Libratus победила в профессиональном турнире по покеру. Более того, ИИ уже постепенно пробирается и в кино: например, создатели сериала «Карточный домик» использовали big data при кастинге, чтобы подобрать максимально популярный актёрский состав.
Как и полвека назад, самым перспективным направлением остаётся распознание образов. Рукописный текст или «капча» давно уже не проблема — теперь сети успешно различают людей по фотографиям, учатся определять выражения лиц, сами рисуют котиков и сюрреалистические картины. Сейчас основную практическую пользу из этих развлечений извлекают разработчики беспилотных автомобилей — ведь чтобы оценить ситуацию на дороге, машине нужно очень быстро и точно распознать окружающие предметы. Не отстают и спецслужбы с маркетологами: по обычной записи видеонаблюдения нейронная сеть давно уже может отыскать человека в соцсетях. Поэтому особо недоверчивые заводят себе специальные камуфляжные очки, которые могут обмануть программу.
«Ты всего лишь машина. Только имитация жизни. Разве робот сочинит симфонию? Разве робот превратит кусок холста в шедевр искусства?» («Я, робот»)
Наконец, начинает сбываться и предсказание Розенблатта о самокопирующихся роботах: недавно нейросеть DeepCoder обучили программированию. На самом деле программа пока что просто заимствует куски чужого кода, да и писать умеет только самые примитивные функции. Но разве не с простейшей формулы началась история самих сетей?
Игры с ботами
Развлекаться с недоученными нейросетями очень весело: они порой выдают такие ошибки, что в страшном сне не приснится. А если ИИ начинает учиться, появляется азарт: «Неужто сумеет?» Поэтому сейчас набирают популярность интернет-игры с нейросетями.
Одним из первых прославился интернет-джинн Акинатор, который за несколько наводящих вопросов угадывал любого персонажа. Строго говоря, это не совсем нейросеть, а несложный алгоритм, но со временем он становился всё догадливее. Джинн пополнял базу данных за счёт самих пользователей — и в результате его обучили даже интернет-мемам.
Другое развлечение с «угадайкой» предлагает ИИ от Google: нужно накалякать за двадцать секунд рисунок к заданному слову, а нейросеть потом пробует угадать, что это было. Программа очень смешно промахивается, но порой для верного ответа хватает всего пары линий — а ведь именно так узнаём объекты и мы сами.
Ну и, конечно, в интернете не обойтись без котиков. Программисты взяли вполне серьёзную нейросеть, которая умеет строить проекты фасадов или угадывать цвет на чёрно-белых фотографиях, и обучили её на кошках — чтобы она пыталась превратить любой контур в полноценную кошачью фотографию. Поскольку проделать это ИИ старается даже с квадратом, результат порой достоин пера Лавкрафта!
При таком обилии удивительных новостей может показаться, что искусственный интеллект вот-вот осознает себя и сумеет решить любую задачу. На самом деле не так всё радужно — или, если встать на сторону человечества, не так мрачно. Несмотря на успехи нейросетей, у них накопилось столько проблем, что впереди нас вполне может ждать очередная «зима».
Главная слабость нейросетей в том, что каждая из них заточена под определённую задачу. Если натренировать сеть на фотографиях с котиками, а потом предложить ей задачку «отличи небо от земли», программа не справится, будь в ней хоть миллиард нейронов. Чтобы появились по-настоящему «умные» компьютеры, надо придумать новый алгоритм, объединяющий уже не нейроны, а целые сети, каждая из которых занимается конкретной задачей. Но даже тогда до человеческого мозга компьютерам будет далеко.
Сейчас самой крупной сетью располагает компания Digital Reasoning (хотя новые рекорды появляются чуть ли не каждый месяц) — в их творении 160 миллиардов элементов. Для сравнения: в одном кубическом миллиметре мышиного мозга около миллиарда связей. Причём биологам пока удалось описать от силы участок в пару сотен микрометров, где нашлось около десятка тысяч связей. Что уж говорить о людях!
Один слой умеет узнавать людей, другой — столы, третий — ножи…
Такими 3D-моделями модно иллюстрировать новости о нейросетях, но это всего лишь крошечный участок мышиного мозга
Кроме того, исследователи советуют осторожнее относиться к громким заявлениям Google и IBM. Никаких принципиальных прорывов в «когнитивных вычислениях» с 1980-х годов не произошло: компьютеры всё так же механически обсчитывают входящие данные и выдают результат. Нейросеть способна найти закономерность, которую не заметит человек, — но эта закономерность может оказаться случайной. Машина может подсчитать, сколько раз в твиттере упоминается «Оскар», — но не сможет определить, радуются пользователи результатам или ехидничают над выбором киноакадемии.
Теоретики искусственного интеллекта настаивают, что одну из главных проблем — понимание человеческого языка — невозможно решить простым перебором ключевых слов. А именно такой подход до сих пор используют даже самые продвинутые нейросети.
Сказки про Скайнет
Хотя нам самим сложно удержаться от иронии на тему бунта роботов, серьёзных учёных не стоит даже и спрашивать о сценариях из «Матрицы» или «Терминатора»: это всё равно что поинтересоваться у астронома, видел ли он НЛО. Исследователь искусственного интеллекта Элиезер Юдковски, известный по роману «Гарри Поттер и методы рационального мышления», написал ряд статей, где объяснил, почему мы так волнуемся из-за восстания машин — и чего стоит опасаться на самом деле.
Прежде всего, «Скайнет» приводят в пример так, словно мы уже пережили эту историю и боимся повторения. А всё потому, что наш мозг не умеет отличать выдумки с киноэкранов от жизненного опыта. На самом-то деле роботы никогда не бунтовали против своей программы, и попаданцы не прилетали из будущего. С чего мы вообще взяли, что это реальный риск?
Бояться надо не врагов, а чересчур усердных друзей. У любой нейросети есть мотивация: если ИИ должен гнуть скрепки, то, чем больше он их сделает, тем больше получит «награды». Если дать хорошо оптимизированному ИИ слишком много ресурсов, он не задумываясь переплавит на скрепки всё окрестное железо, потом людей, Землю и всю Вселенную. Звучит безумно — но только на человеческий вкус! Так что главная задача будущих создателей ИИ — написать такой жёсткий этический кодекс, чтобы даже существо с безграничным воображением не смогло найти в нём «дырок».
* * *
Итак, до настоящего искусственного интеллекта пока ещё далеко. С одной стороны над этой проблемой по-прежнему бьются нейробиологи, которые ещё до конца не понимают, как же устроено наше сознание. С другой наступают программисты, которые попросту берут задачу штурмом, бросая на обучение нейросетей всё новые и новые вычислительные ресурсы. Но мы уже живём в прекрасную эпоху, когда машины берут на себя всё больше рутинных задач и умнеют на глазах. А заодно служат людям отличным примером, потому что всегда учатся на своих ошибках.
Сделай сам
Нейронную сеть можно сделать с помощью спичечных коробков — тогда у вас в арсенале появится фокус, которым можно развлекать гостей на вечеринках. Редакция МирФ уже попробовала — и смиренно признаёт превосходство искусственного интеллекта. Давайте научим неразумную материю играть в игру «11 палочек». Правила просты: на столе лежит 11 спичек, и в каждый ход можно взять либо одну, либо две. Побеждает тот, кто взял последнюю. Как же играть в это против «компьютера»? Очень просто.
- Берём 10 коробков или стаканчиков. На каждом пишем номер от 2 до 11.
- Кладём в каждый коробок два камешка — чёрный и белый. Можно использовать любые предметы — лишь бы они отличались друг от друга. Всё — у нас есть сеть из десяти нейронов!
Теперь начинается игра.
- Нейросеть всегда ходит первой. Для начала посмотрите, сколько осталось спичек, и возьмите коробок с таким номером. На первом ходу это будет коробок №11.
- Возьмите из нужного коробка любой камешек. Можно закрыть глаза или кинуть монетку, главное — действовать наугад.
- Если камень белый — нейросеть решает взять две спички. Если чёрный — одну. Положите камешек рядом с коробком, чтобы не забыть, какой именно «нейрон» принимал решение.
- После этого ходит человек — и так до тех пор, пока спички не закончатся.
Ну а теперь начинается самое интересное: обучение. Если сеть выиграла партию, то её надо наградить: кинуть в те «нейроны», которые участвовали в этой партии, по одному дополнительному камешку того же цвета, который выпал во время игры. Если же сеть проиграла — возьмите последний использованный коробок и выньте оттуда неудачно сыгравший камень. Может оказаться, что коробок уже пустой, — тогда «последним» считается предыдущий походивший нейрон. Во время следующей партии, попав на пустой коробок, нейросеть автоматически сдастся.
Вот и всё! Сыграйте так несколько партий. Сперва вы не заметите ничего подозрительного, но после каждого выигрыша сеть будет делать всё более и более удачные ходы — и где-то через десяток партий вы поймёте, что создали монстра, которого не в силах обыграть.
А можно сыграть в эту игру прямо здесь
Кот-император | 08.04.2017
Нейросети — это настолько просто, что их можно строить даже из спичечных коробков. Мы решили наглядно показать, как это работает, и сделали для вас маленькую браузерную игру. Попробуйте обучить собственный ИИ!
что это такое? Обучение нейронным сетям
О понятии «нейронные сети» мы впервые слышим в курсе биологии восьмого класса. Нейрон – это структурно-функциональная единица нашей нервной системы. Нейроны объединяются в сеть, чтобы выполнять специфические физиологические функции. Учёных давно интересовала возможность повторить работу такой сети вне человеческого организма, иными словами – создать искусственную нейронную сеть, которая могла бы повторять процессы, проходящие в головном мозгу и, самое главное, могла бы самостоятельно обучаться.
Про искусственный интеллект написано много книг и снято немало фильмов, но первый серьёзный прорыв в этом направлении совершили американский нейропсихолог, один из основателей кибернетики, Уоррен Мак-Каллок и Уолтер Питтс, американский нейролингвист. Вдвоём они разработали модель искусственного нейрона, а затем и сеть из множества таких элементов. С помощью алгоритмов обучения Мак-Каллок и Питтс доказали, что их сеть способна саморазвиваться. Сначала её использовали в достаточно простых вещах – прогнозы, анализы, распознавание графических образов – на самом примитивном уровне.
Каждый отдельный нейрон в такой сети можно сравнить с процессором, выполняющим одну простую задачу, и способным подать сигнал соседним таким же процессорам и принять ответный сигнал от них. Но этих процессоров очень много, и вместе они способны выполнить уже множество значительно более сложных задач за короткое время.
Вам будет это интересно: нейронные сети и имитационное моделирование
Главное свойство нейронной сети – её умение обучаться. То есть, нейронную сеть не программируют в привычном нам смысле, ведь любая программа действует по конкретным алгоритмам, она не может отступить и измениться, а нейронная сеть – может. Нейронные сети способны работать с неполными, неверными и частично отсутствующими данными и делать выводы на основании предыдущих знаний.
Разумеется, это означает, что, в отличие от программы, нейронная сеть, как и человек, способна ошибаться.
Зачем же нужны нейронные сети?
Для выполнения задач, с которыми могут справиться люди, но не может справиться программа. При этом нейронная сеть работает быстрее человека, она беспристрастна и у неё отсутствует фактор человеческих ошибок.
Это может быть аналитическое предсказание, например, рост или падение курса валют.
Анализирование и отбор объектов, подходящих под определённые параметры. Например, нейронная сеть получает доступ к электронному журналу школы и предлагает подходящие каждому ученику направления дальнейшего обучения.
Распознавание – сейчас это наиболее активное использование нейронных сетей. Большое количество различных приложений работают именно так.
Это и графические редакторы, определяющие положение лица на фото, глаз, и умеющие проводить корректировку формы лица, цвета глаз, без дополнительного вмешательства пользователя, по одному указанию. Это умение приложения по запросу пользователя сделать из фото стилизацию под манеру различных художников.
Это современные клавиатуры смартфонов, которые не просто предлагают слова из словаря, а анализируют ваш словарный запас и угадывают, что же вы хотите написать. Чем дольше пользователь использует подобную клавиатуру, тем легче нейросети предлагать варианты слов и фраз.
Это приложения, анализирующие на видео вашу мимику, и дополняющие видео несуществующими элементами, например, дорисовывая человеку кроличий нос и уши.
Это приложения, способные по куску музыкального фрагмента отыскать в интернет-библиотеках всю песню.
Это различные голосовые ассистенты в смартфонах, способные отвечать на ваши запросы и так же, как и клавиатуры, обучающиеся со временем.
Это интеллектуальные охранные системы, распознающие хозяев по множеству надёжных параметров.
Это беспилотные автомобили, которые должны не просто двигаться по дорогам в соответствии с правилами дорожного движения, но и обязаны сориентироваться в сложной, аварийной ситуации и избегать дорожно-транспортных происшествий.
Мы прямо сейчас наблюдаем, как нейронные сети постепенно охватывают весь мир, мы применяем их практически во всех сферах деятельности, но, тем не менее, пока нейронные технологии далеки по возможностям от человеческого мозга, и их развитие только начинается.
Лавриненко Мария Михайловна, преподаватель химии и ИКТ, ГБОУ №463
Нейронные сети, или Как обучить искусственный интеллект — Интернет изнутри
Машинное обучение является не единственным, но одним из фундаментальных разделов искусственного интеллекта, занимающимся вопросами самостоятельного извлечения знаний интеллектуальной системой в процессе ее работы. Основу машинного обучения составляют так называемые искусственные нейронные сети, принцип работы которых напоминает работу биологических нейронов нервной системы животных и человека.
Технологии искусственного интеллекта все активнее используются в самых различных областях – от производственных процессов до финансовой деятельности. Популярные услуги техгигантов, такие как «Яндекс.Алиса», Google Translate, Google Photos и Google Image Search (AlexNet, GoogleNet) основаны на работе нейронных сетей.
Что такое нейронные сети и как они работают – об этом пойдет речь в статье.Введение
У искусственного интеллекта множество определений. Под этим термином понимается, например, научное направление, в рамках которого ставятся и решаются задачи аппаратного или программного моделирования тех видов человеческой деятельности, которые традиционно считаются творческими или интеллектуальными, а также соответствующий раздел информатики, задачей которого является воссоздание с помощью вычислительных систем и иных искусственных устройств разумных рассуждений и действий, равно как и свойство систем выполнять «творческие» функции. Искусственный интеллект уже сегодня прочно вошел в нашу жизнь, он используется так или иначе во многих вещах, которые нас окружают: от смартфонов до холодильников, — и сферах деятельности: компании многих направлений, от IT и банков до тяжелого производства, стремятся использовать последние разработки для
повышения эффективности. Данная тенденция будет лишь усиливаться в будущем.Машинное обучение является не единственным, но одним из основных разделов, фундаментом искусственного интеллекта, занимающимся вопросами самостоятельного извлечения знаний интеллектуальной системой в процессе ее работы. Зародилось это направление еще в середине XX века, однако резко возросший интерес направление получило с существенным развитием области математики, специализирующейся на нейронных сетях, после недавнего изобретения эффективных алгоритмов обучения таких сетей. Идея создания искусственных нейронных сетей была перенята у природы. В качестве примера и аналога была использована нервная система как животного, так и человека. Принцип работы искусственной нейронной сети соответствует алгоритму работы биологических нейронов.
Нейрон – вычислительная единица, получающая информацию и производящая над этой информацией какие-либо вычисления. Нейроны являются простейшей структурной единицей любой нейронной сети, из их множества, упорядоченного некоторым образом в слои, а в конечном счете – во всю сеть, состоят все сети. Все нейроны функционируют примерно одинаковым образом, однако бывают некоторые частные случаи нейронов, выполняющих специфические функции. Три основных типа нейронов:
Рис. 1. Основные типы нейронов.Входной – слой нейронов, получающий информацию (синий цвет на рис. 1).
Скрытый – некоторое количество слоев, обрабатывающих информацию (красный цвет на рис. 1).
Выходной – слой нейронов, представляющий результаты вычислений (зеленый цвет на рис. 1).Помимо самих нейронов существуют синапсы. Синапс – связь, соединяющая выход одного нейрона со входом другого. Во время прохождения сигнала через синапс сигнал может усиливаться или ослабевать. Параметром синапса является вес (некоторый коэффициент, может быть любым вещественным числом), из-за которого информация, передающаяся от одного нейрона к другому, может изменяться. При помощи весов входная информация проходит обработку — и после мы получаем результат.
Рис. 2. Модель искусственного нейрона.На рис. 2 изображена математическая модель нейрона. На вход подаются числа (сигналы), после они умножаются на веса (каждый сигнал – на свой вес) и суммируются. Функция активации высчитывает выходной сигнал и подает его на выход.
Сама идея функции активации также взята из биологии. Представьте себе ситуацию: вы подошли и положили палец на конфорку варочной панели. В зависимости от сигнала, который при этом поступит от пальца по нервным окончаниям в мозг, в нейронах вашего мозга будет принято решение: пропускать ли сигнал дальше по нейронным связям, давая посыл мышцам отдернуть палец от горячей конфорки, или не пропускать сигнал, если конфорка холодная и палец можно оставить. Математический аналог функции активации имеет то же назначение. Таким образом, функция активации позволяет проходить или не проходить сигналам от нейрона к нейронам в зависимости от информации, которую они передают. Т.е. если информация является важной, то функция пропускает ее, а если информации мало или она недостоверна, то функция активации не позволяет ей пройти дальше.
Таблица 1. Популярные разновидности активационных функций искусственного нейронаВ таблице 1 представлены некоторые виды активационных функций нейрона. Простейшей разновидностью функции активации является пороговая. Как следует из названия, ее график представляет из себя ступеньку. Например, если поступивший в нейрон суммарный сигнал от предыдущих нейронов меньше 0, то в результате применения функции активации сигнал полностью «тормозится» и дальше не проходит, т.е. на выход данного нейрона (и, соответственно, входы последующих нейронов) подается 0. Если же сигнал >= 0, то на выход данного нейрона подается 1.
Функция активации должна быть одинаковой для всех нейронов внутри одного слоя, однако для разных слоев могут выбираться разные функции активации. В искусственных нейронных сетях выбор функции обуславливается областью применения и является важной исследовательской задачей для специалиста по машинному обучению.
Нейронные сети набирают все большую популярность и область их использования также расширяется. Список некоторых областей, где применяются искусственные нейронные сети:
- Ввод и обработка информации. Распознавание текстов на фотографиях и различных документах, распознавание голосовых команд, голосовой ввод текста.
- Безопасность. Распознавание лиц и различных биометрических данных, анализ трафика в сети, обнаружение подделок.
- Интернет. Таргетинговая реклама, капча, составление новостных лент, блокировка спама, ассоциативный поиск информации.
- Связь. Маршрутизация пакетов, сжатие видеоинформации, увеличение скорости кодирования и декодирования информации.
Помимо перечисленных областей, нейронные сети применяются в робототехнике, компьютерных и настольных играх, авионике, медицине, экономике, бизнесе и в различных политических и социальных технологиях, финансово-экономическом анализе.
Архитектуры нейронных сетей
Архитектур нейронных сетей большое количество, и со временем появляются новые. Рассмотрим наиболее часто встречающиеся базовые архитектуры.
Персептрон
Рис. 3. Пример архитектуры персептрона.Персептрон – это простейшая модель нейросети, состоящая из одного нейрона. Нейрон может иметь произвольное количество входов (на рис. 3 изображен пример вида персептрона с четырьмя входами), а один из них обычно тождественно равен 1. Этот единичный вход называют смещением, его использование иногда бывает очень удобным. Каждый вход имеет свой собственный вес. При поступлении сигнала в нейрон, как и было описано выше, вычисляется взвешенная сумма сигналов, затем к сигналу применяется функция активации и сигнал передается на выход. Такая
простая на первый взгляд сеть, всего из одного-единственного нейрона, способна, тем не менее, решать ряд задач: выполнять простейший прогноз, регрессию данных и т.п., а также моделировать поведение несложных функций. Главное для эффективности работы этой сети – линейная разделимость данных.Для читателей, немного знакомых с таким разделом как логика, будут знакомы логическое И (умножение) и логическое ИЛИ (сложение). Это булевы функции, принимающие значение, равное 0, всегда, кроме одного случая, для умножения, и, наоборот, значения, равные 1, всегда, кроме одного случая, для сложения. Для таких функций всегда можно провести прямую (или гиперплоскость в многомерном пространстве), отделяющие 0 значения от 1. Это и называют линейной разделимостью объектов. Тогда подобная модель сможет решить поставленную задачу классификации и сформировать базовый логический элемент. Если же объекты линейно неразделимы, то сеть из одного нейрона с ними не справится. Для этого существуют более сложные архитектуры нейронных сетей, в конечном счете, тем не менее, состоящие из множества таких персептронов, объединенных в слои.
Многослойный персептрон
Слоем называют объединение нейронов, на схемах, как правило, слои изображаются в виде одного вертикального ряда (в некоторых случаях схему могут поворачивать, и тогда ряд будет горизонтальным). Многослойный персептрон является обобщением однослойного персептрона. Он состоит из некоторого множества входных узлов, нескольких скрытых слоев вычислительных
Рис. 4. Архитектура многослойного персептрона.
нейронов и выходного слоя (см. рис. 4).Отличительные признаки многослойного персептрона:
- Все нейроны обладают нелинейной функцией активации, которая является дифференцируемой.
- Сеть достигает высокой степени связности при помощи синаптических соединений.
- Сеть имеет один или несколько скрытых слоев.
Такие многослойные сети еще называют глубокими. Эта сеть нужна для решения задач, с которыми не может справиться персептрон. В частности, линейно неразделимых задач. В действительности, как следствие из теоремы Колмогорова, именно многослойный персептрон является единственной универсальной нейронной сетью, универсальным аппроксиматором, способным решить любую задачу. Возможно, не самым эффективным способом, который могли бы обеспечить более узкопрофильные нейросети, но все же решить.
Именно поэтому, если исследователь не уверен, нейросеть какого вида подходит для решения стоящей перед ним задачи, он выбирает сначала многослойный персептрон.Сверточная нейронная сеть (convolution neural network)
Сверточная нейронная сеть – сеть, которая обрабатывает передаваемые данные не целиком, а фрагментами. Данные последовательно обрабатываются, а после передаются дальше по слоям. Сверточные нейронные сети состоят из нескольких типов слоев: сверточный слой, субдискретизирующий слой, слой полносвязной сети (когда каждый нейрон одного слоя связан с каждым нейроном следующего – полная связь). Слои свертки и подвыборки (субдискретизации) чередуются и их набор может повторяться несколько раз (см. рис. 5). К конечным слоям часто добавляют персептроны, которые служат для последующей обработки данных.
Рис. 5. Архитектура сверточной нейронной сети.Название архитектура сети получила из-за наличия операции свёртки, суть которой в том, что каждый фрагмент изображения умножается на матрицу (ядро) свёртки поэлементно, а результат суммируется и записывается в аналогичную позицию выходного изображения. Необходимо это для перехода от конкретных особенностей изображения к более абстрактным деталям, и далее – к
ещё более абстрактным, вплоть до выделения понятий высокого уровня (присутствует ли что-либо искомое на изображении).Сверточные нейронные сети решают следующие задачи:
- Классификация. Пример: нейронная сеть определяет, что или кто находится на изображении.
- Детекция. Пример: нейронная сеть определяет, что/кто и где находится на изображении.
- Сегментация. Пример: нейронная сеть может определить каждый пиксель изображения и понять, к чему он относится.
Описанные сети относятся к сетям прямого распространения. Наряду с ними существуют нейронные сети, архитектуры которых имеют в своем составе связи, по которым сигнал распространяется в обратную сторону.
Рекуррентная нейронная сеть
Рекуррентная нейронная сеть – сеть, соединения между нейронами которой образуют ориентированный цикл. Т.е. в сети имеются обратные связи. При этом информация к нейронам может передаваться как с предыдущих слоев, так и от самих себя с предыдущей итерации (задержка). Пример схемы первой рекуррентной нейронной сети (НС Хопфилда) представлен на рис. 6.
Рис. 6. Архитектура рекуррентной нейронной сети.Характеристики сети:
- Каждое соединение имеет свой вес, который также является приоритетом.
- Узлы подразделяются на два типа: вводные (слева) и скрытые (1, 2, … K).
- Информация, находящаяся в нейронной сети, может передаваться как по прямой, слой за слоем, так и между нейронами.
Такие сети еще называют «памятью» (в случае сети Хопфилда – автоассоциативной; бывают также гетероассоциативные (сеть Коско – развитие сети Хопфилда) и другие). Почему? Если подать данной сети на вход некие «образцы» – последовательности кодов (к примеру, 1000001, 0111110 и 0110110) — и обучить ее на запоминание этих образцов, настроив веса синапсов сети определенным образом при помощи правила Хебба3, то затем, в процессе функционирования, сеть сможет «узнавать» запомненные образы и выдавать их на выход, в том числе исправляя искаженные поданные на вход образы. К примеру, если после обучения такой сети я подам на вход 1001001, то сеть узнает и исправит запомненный образец, выдав на выходе 1000001. Правда, эта нейронная сеть не толерантна к поворотам и сдвигам образов, и все же для первой нейронной сети своего класса сеть весьма интересна.
Таким образом, особенность рекуррентной нейронной сети состоит в том, что она имеет «области внимания». Данная область позволяет задавать фрагменты передаваемых данных, которым требуется усиленная обработка.
Информация в рекуррентных сетях со временем теряется со скоростью, зависящей от активационных функций. Данные сети на сегодняшний день нашли свое применение в распознавании и обработке текстовых данных. Об этом речь пойдет далее.
Самоорганизующаяся нейронная сеть
Пример самоорганизующейся нейронной сети – сеть Кохонена. В процессе обучения осуществляется адаптация сети к поставленной задаче. В представленной сети (см. рис. 7) сигнал идет от входа к выходу в прямом направлении. Структура сети имеет один слой нейронов, которые не имеют коэффициентов смещения (тождественно единичных входов). Процесс обучения сети происходит при помощи метода последовательных приближений. Нейронная сеть подстраивается под закономерности входных данных, а не под лучшее значение на выходе. В результате обучения сеть находит окрестность, в которой находится лучший нейрон. Сеть функционирует по принципу «победитель получает все»: этот самый лучший нейрон в итоге на выходе будет иметь 1, а остальные нейроны, сигнал на которых получился меньше, 0. Визуализировать это можно так: представьте, что правый ряд нейронов, выходной, на
Рис. 7. Архитектура самоорганизующейся нейронной сети.
рис. 7 – это лампочки. Тогда после подачи на вход сети данных после их обработки на выходе «зажжется» только одна лампочка, указывающая, куда относится поданный объект. Именно поэтому такие сети часто используются в задачах кластеризации и классификации.Алгоритмы обучения нейронных сетей
Чтобы получить решение поставленной задачи с использованием нейронной сети, вначале требуется сеть обучить (рис. 8). Процесс обучения сети заключается в настройке весовых коэффициентов связей между нейронами.
Рис. 8. Процесс обучения нейронной сети.Алгоритмы обучения для нейронной сети бывают с
учителем и без.- С учителем: предоставление нейронной сети некоторой выборки обучающих примеров. Образец подается на вход, после происходит обработка внутри нейронной сети и рассчитывается выходной сигнал, сравнивающийся с соответствующим значением целевого вектора (известным нам «правильным ответом» для каждого из обучающих примеров). Если ответ сети не совпадает с требуемым, производится коррекция весов сети, напрямую зависящая от того, насколько отличается ответ сети от правильного (ошибка). Правило этой коррекции называется правилом Видроу-Хоффа и является прямой пропорциональностью коррекции каждого веса и размера ошибки, производной функции активации и входного сигнала нейрона. Именно после изобретения и доработок алгоритма распространения этой ошибки на все нейроны скрытых слоев глубоких нейронных сетей эта область искусственного интеллекта вернула к себе интерес.
- Без учителя: алгоритм подготавливает веса сети таким образом, чтобы можно было получить согласованные выходные векторы, т.е. предоставление достаточно близких векторов будет давать похожие выходы. Одним из таких алгоритмов обучения является правило Хебба, по которому настраивается перед работой матрица весов, например, рекуррентной сети Хопфилда.
Рассмотрим теперь, какие архитектуры сетей являются наиболее востребованными сейчас, каковы особенности использования нейросетей на примерах известных крупных проектов.
Рекуррентные сети на примерах Google и «Яндекса»
Уже упоминавшаяся выше рекуррентная нейронная сеть (RNN) – сеть, которая обладает кратковременной «памятью», из-за чего может быстро производить анализ последовательностей различной длины. RNN разбивает потоки данных на части и производит оценку связей между ними.
Сеть долговременной краткосрочной памяти (Long shortterm memory – LSTM) – сеть, которая появилась в результате развития RNN-сетей. Это интересная модификация RNN-сетей, позволяющая сети не просто «держать контекст», но и умеющая «видеть» долговременные зависимости. Поэтому LSTM подходит для прогнозирования различных изменений при помощи экстраполяции (выявление тенденции на основе данных), а также в любых задачах, где важно умение «держать контекст», особенно хорошо подвластное для данной нейросети.
Рис. 9. Модули рекуррентной нейронной сети.Форма рекуррентных нейронных сетей представляет собой несколько повторяющихся модулей. В стандартном виде эти модули имеют простую структуру. На рисунке 9 изображена сеть, которая имеет в одном из слоев гиперболический тангенс в качестве функции активации.
Рис. 10. Модуль LSTM-сети.LSTM также имеет цепочечную структуру. Отличие состоит в том, что сеть имеет четыре слоя, а не один (рис. 10). Главным отличием LSTM-сети является ее клеточное состояние (или состояние ячейки), которое обозначается горизонтальной линией в верхней части диаграммы и по которой проходит информация (рис. 11). Это самое состояние ячейки напоминает ленту конвейера: она проходит напрямую через всю цепочку, участвуя в некоторых преобразованиях. Информация может как «течь» по ней, не подвергаясь изменениям, так и быть подвергнута преобразованиям со стороны нейросети7. (Представьте себе линию контроля на конвейере: изделия продвигаются на ленте перед сотрудником контроля, который лишь наблюдает за ними, но если ему что-то покажется важным или подозрительным, он может вмешаться).
Рис. 11. Клеточное состояние LSTM-модуля.LSTM имеет способность удалять или добавлять информацию к клеточному состоянию. Данная способность осуществляется при помощи вентилей, которые регулируют процессы взаимодействия с информацией. Вентиль – возможность выборочно пропускать информацию. Он состоит из сигмоидного слоя нейронной сети и операции поточечного умножения (рис. 12).
Рис. 12. Вентиль.Сигмоидный слой (нейроны с сигмоидальной функцией активации) подает на выход числа между нулем и единицей, описывая таким образом, насколько каждый компонент должен быть пропущен сквозь вентиль. Ноль – «не пропускать вовсе», один – «пропустить все». Таких «фильтров» в LSTM-сети несколько. Для чего сети нужна эта способность: решать, что важно, а что нет? Представьте себе следующее: сеть переводит предложение и в какой-то момент ей предстоит перевести с английского языка на русский, скажем, местоимение, прилагательное или причастие. Для этого сети необходимо, как минимум, помнить род и/или число предыдущего существительного, к которому переводимое слово относится. Однако как только мы встретим новое существительное, род предыдущего можно забыть. Конечно, это очень упрощенный пример, тем не
менее, он позволяет понять трудность принятия решения: какая информация еще важна, а какую уже можно забыть. Иначе говоря, сети нужно решить, какая информация будет храниться в состоянии ячейки, а затем – что на выходе из нее будет выводить.Примеры использования нейронных сетей
Мы рассмотрели основные типы нейронных систем и познакомились с принципами их работы. Остановимся теперь на их практическом применении в системах Google Translate, «Яндекс.Алиса», Google Photos и Google Image Search (AlexNet, GoogleNet).
LSTM в Google Translate
Google-переводчик в настоящее время основан на методах машинного обучения и использует принцип работы LSTM-сетей. Система производит вычисления, чтобы понять значение слова или фразы, основываясь на предыдущих значениях в последовательности (контексте). Такой алгоритм помогает системе понимать контекст предложения и верно подбирать перевод среди различных вариантов. Еще несколько лет назад Google Translate работал на основе статистического машинного перевода – это разновидность перевода, где перевод генерируется на основе статистических моделей (бывают: по словам, по фразам, по синтаксису и т.д.), а параметры этих моделей являются результатами анализа корпусов текстов двух выбранных для перевода языков. Эти статистические модели обладали большим быстродействием, однако их эффективность ниже. Общий прирост качества перевода после внедрения системы на основе нейросетей в Google-переводчик составил, казалось бы, не очень много – порядка 10%, однако для отдельных языковых пар эффективность перевода достигла 80-90%,
Рис. 13. Рекуррентная двунаправленная нейронная сеть Google-переводчика.
вплотную приблизившись к оценкам качества человеческого перевода. «Платой» за такое качество перевода является сложность построения, обучения и перенастройки системы на основе нейросети: она занимает недели. Вообще для современных глубоких нейронных сетей, использующихся в таких крупных проектах, в порядке вещей обучение, занимающее дни и недели.Рассмотрим LSTM-сеть переводчика (GNMT) подробнее. Нейронная сеть переводчика имеет разделение на два потока (см. рис. 13). Первый поток нейронной сети (слева) является анализирующим и состоит из восьми слоев. Данный поток помогает разбивать фразы или предложения на несколько смысловых частей, а после производит их анализ. Сеть позволяет читать предложения в двух направлениях, что помогает лучше понимать контекст. Также она занимается формированием модулей внимания, которые позволяют второму потоку определять ценности отдельно взятых смысловых фрагментов.
Второй поток нейронной сети (справа) является синтезирующим. Он позволяет вычислять самый подходящий вариант для перевода, основываясь на контексте и модулях внимания (показаны голубым цветом).
В системе нейронной сети самым маленьким элементом является фрагмент слова. Это позволяет сфокусировать вычислительную мощность на контексте предложения, что обеспечивает высокую скорость и точность переводчика. Также анализ фрагментов слова сокращает риски неточного перевода слов, которые имеют суффиксы, префиксы и окончания.
LSTM в «Яндекс.Алисе»
Компания «Яндекс» также использует нейросеть типа LSTM в продукте «Яндекс.Алиса». На рисунке 14 изображено взаимодействие пользователя с системой. После вопроса пользователя информация передается на сервер распознавания, где она преобразуется в текст. Затем текст поступает в классификатор интентов (интент (от англ. intent) – намерение, цель пользователя, которое он вкладывает в запрос), где при помощи машинного обучения анализируется. После анализа интентов они поступают на семантический теггер (tagger) – модель, которая позволяет выделить полезную и требующуюся информацию из предложения. Затем полученные результаты структурируются и передаются в модуль dialog manager, где обрабатывается полученная информация и генерируется ответ.
Рис. 14. Процесс работы сервиса «Яндекс.Алиса».
LSTM-сети применяются в семантическом теггере. В этом модуле используются двунаправленные LSTM с attention. На этом этапе генерируется не только самая вероятная гипотеза, потому что в зависимости от диалога могут потребоваться и другие. От состояния диалога в dialog manager происходит повторное взвешивание гипотез. Сети с долговременной памятью помогают лучше вести диалог с пользователем, потому что могут помнить предыдущие сообщения и более точно генерировать ответы, а также они помогают разрешать много проблемных ситуаций. В ходе диалога нейронная сеть может убирать слова, которые не несут никакой важной информации, а остальные анализировать и предоставлять ответ9. Для примера на рис. 14 результат работы системы будет следующим. Сначала речь пользователя в звуковом формате будет передана на сервер распознавания, который выполнит лексический анализ (т.е. переведет сказанное в текст и разобьет его на слова – лексемы), затем классификатор интентов выполнит уже роль семантического анализа (понимание смысла того, что было сказано; в данном случае – пользователя интересует погода), а семантический теггер выделит полезные элементы информации: теггер выдал бы, что завтра – это дата, на которую нужен прогноз погоды. В итоге данного анализа запроса пользователя будет составлено внутреннее представление запроса – фрейм, в котором будет указано, что интент – погода, что погода нужна на +1 день от текущего дня, а где – неизвестно. Этот фрейм попадет в диалоговый менеджер, который хранит тот самый контекст беседы и будет принимать на основе хранящегося контекста решение, что делать с этим запросом. Например, если до этого беседа не происходила, а для станции с «Яндекс.Алисой» указана геолокация г. Москва, то менеджер получит через специальный интерфейс (API) погоду на завтра в Москве, отправит команду на генерацию текста с этим прогнозом, после чего тот будет передан в синтезатор речи помощника. Если же Алиса до этого вела беседу с пользователем о достопримечательностях Парижа, то наиболее вероятно, что менеджер учтет это и либо уточнит у пользователя информацию о месте, либо сразу сообщит о погоде в Париже. Сам диалоговый менеджер работает на основе скриптов (сценариев обработки запросов) и правил, именуемых form-filling. Вот такой непростой набор технических решений, методов, алгоритмов и систем кроется за фасадом, позволяющим пользователю спросить и узнать ответ на простой бытовой вопрос или команду.Свёрточные нейронные сети, используемые для классификации изображений, на примере Google Photos и Google Image Search
Задача классификации изображений – это получение на вход начального изображения и вывод его класса (стол, шкаф, кошка, собака и т.д.) или группы вероятных классов, которая лучше всего характеризует изображение. Для людей это совершенно естественно и просто: это один из первых навыков, который мы осваиваем с рождения. Компьютер лишь «видит» перед собой пиксели изображения, имеющие различный цвет и интенсивность. На сегодня задача классификации объектов, расположенных на изображении, является основной для области компьютерного зрения. Данная область начала активно развиваться с 1970-х, когда компьютеры стали достаточно мощными, чтобы оперировать большими объёмами данных. До развития нейронных сетей задачу классификации изображений решали с помощью специализированных алгоритмов. Например, выделение границ изображения с помощью фильтра Собеля и фильтра Шарра или использование гистограмм градиентов10. С появлением более мощных GPU, позволяющих значительно эффективнее обучать нейросеть, применение нейросетей в сфере компьютерного зрения значительно возросло.
В 1988 году Ян Лекун предложил свёрточную архитектуру нейросети, нацеленную на классификацию изображений. А в 2012 году сеть AlexNet, построенная по данной архитектуре, заняла первое место в конкурсе по распознаванию изображений ImageNet, имея ошибку распознавания равную 15,3%12. Свёрточная архитектура нейросети использует некоторые особенности биологического распознавания образов, происходящих в мозгу человека. Например, в мозгу есть некоторые группы клеток, которые активируются, если в определённое поле зрения попадает горизонтальная или вертикальная граница объекта. Данное явление обнаружили Хьюбель и Визель в 1962 году. Поэтому, когда мы смотрим на изображение, скажем, собаки, мы можем отнести его к конкретному классу, если у изображения есть характерные особенности, которые можно идентифицировать, такие как лапы или четыре ноги. Аналогичным образом компьютер может выполнять классификацию изображений через поиск характеристик базового уровня, например, границ и искривлений, а затем — с помощью построения более абстрактных концепций через группы сверточных слоев.
Рис. 15. Архитектура свёрточной сети AlexNet.Рассмотрим подробнее архитектуру и работу свёрточной нейросети (convolution neural network) на примере нейросети AlexNet (см. рис. 15). На вход подаётся изображение 227х227 пикселей (на рисунке изображено желтым), которое необходимо классифицировать (всего 1000 возможных классов). Изображение цветное, поэтому оно разбито по трём RGB-каналам. Наиболее важная операция – операция свёртки.
Операция свёртки (convolution) производится над двумя матрицами A и B размера [axb] и [cxd], результатом которой является матрица С размера
, где s – шаг, на который сдвигают матрицу B. Вычисляется результирующая матрица следующим образом:
см. рис. 16.Рисунок 16. Операция свёртки15: Исходная матрица A обозначена голубым цветом (имеет большую размерность), ядро свертки – матрица B — обозначена темно-синим цветом и перемещается по матрице A; результирующая матрица изображена зеленым, при этом соответствующая каждому шагу свертки результирующая ячейка отмечена темно-зеленым.
Рис. 16. Операция свёртки.Чем больше результирующий элемент ci,j,, тем более похожа область матрицы A на матрицу B. A называют изображением, а B – ядром или фильтром. Обычно шаг смещения B равен s = 1. Если увеличить шаг смещения, можно добиться уменьшения влияния соседних пикселей друг на друга в сумме (уменьшить рецептивное поле восприятия нейросети), в подавляющем большинстве случаев шаг оставляют равным 1. На рецептивное поле также влияет и размер ядра свёртки. Как видно из рис. 16, при свёртке результат теряет в размерности по сравнению с матрицей A. Поэтому, чтобы избежать данного явления, матрицу A дополняют ячейками (padding). Если этого не сделать, данные при переходе на следующие слои будут теряться слишком быстро, а информация о границах слоя будет неточной.
Таким образом, свёртка позволяет одному нейрону отвечать за определённый набор пикселей в изображении. Весовыми коэффициентами являются коэффициенты фильтра, а входными переменными – интенсивность свечения пикселя плюс параметр смещения.
Данный пример свёртки (см. рис. 16) был одномерным и подходит, например, для черно-белого изображения. В случае цветного изображения операция свёртки происходит следующим образом: в один фильтр включены три ядра, для каждого канала RGB соответственно, над каждым каналом операция свёртки происходит идентично примеру выше, затем три результирующие матрицы поэлементно складываются — и получается результат работы одного
фильтра – карта признаков.Эта на первый взгляд непростая с математической точки зрения процедура нужна для выделения тех самых границ и искривлений – контуров изображения, при помощи которых, по аналогии с мозгом человека, сеть должна понять, что же изображено на картинке. Т.е. на карте признаков будут содержаться выделенные характеристические очертания детектированных объектов. Эта карта признаков будет являться результатом работы чередующихся слоев свертки и пулинга (от англ. pooling, или иначе – subsampling layers). Помните, в разделе описания концепции архитектуры сверточных сетей мы говорили, что эти слои чередуются и их наборы могут повторяться несколько раз (см. рис. 5)? Для чего это нужно? После свертки, как мы знаем, выделяются и «заостряются» некие характеристические черты анализируемого изображения (матрицы пикселей) путем увеличения значений соответствующих ядру ячеек матрицы и «занулению» значений других. При операции субдискретизации, или пулинга, происходит уменьшение размерности сформированных отдельных карт признаков. Поскольку для сверточных нейросетей считается, что информация о факте наличия искомого признака важнее точного знания его координат на изображении, то из нескольких соседних нейронов карты признаков выбирается максимальный и принимается за один нейрон уплотнённой карты признаков меньшей размерности. За счёт данной операции, помимо ускорения дальнейших вычислений, сеть становится также более инвариантной к масштабу входного изображения, сдвигам и поворотам изображений. Данное чередование слоев мы видим и для данной сети AlexNet (см. рис. 15), где слои свертки (обозначены CONV) чередуются с пулингом (обозначены эти слои как POOL), при этом следует учитывать, что операции свертки тем ресурсозатратнее, чем больше размер ядра свертки (матрицы B на рис. 16), поэтому иногда, когда требуется свертка с ядром достаточно большой размерности, ее заменяют на две и более последовательных свертки с ядром меньших
размерностей. (Об этом мы поговорим далее.) Поэтому на рис. 15 мы можем увидеть участок архитектуры AlexNet, на котором три слоя CONV идут друг за другом.Самая интересная часть в сети – полносвязный слой в конце. В этом слое по вводным данным (которые пришли с предыдущих слоев) строится и выводится вектор длины N, где N – число классов, по которым мы бы хотели классифицировать изображение, из них программа выбирает нужный. Например, если мы хотим построить сеть по распознаванию цифр, у N будет значение 10, потому что цифр всего 10. Каждое число в этом векторе представляет собой вероятность конкретного класса. Например, если результирующий вектор для распознавания цифр это [0 0.2 0 0.75 0 0 0 0 0.05], значит существует 20% вероятность, что на изображении «1», 75% вероятность – что «3», и 5% вероятность – что «9». Если мы хотим сеть по распознаванию букв латинского алфавита, то N должно быть равным 26 (без учета регистра), а если и буквы, и цифры вместе, то уже 36. И т.д. Конечно, это очень упрощенные примеры. В сети AlexNet конечная размерность выхода (изображена на рис. 15 зеленым) — 1000, а перед этим идут еще несколько полносвязных слоев с размерностями входа 9216 и выхода 4096 и обоими параметрами 4096 (изображены оранжевым и отмечены FC – full connected — на рисунке).
Способ, с помощью которого работает полносвязный слой, – это обращение к выходу предыдущего слоя (который, как мы помним, должен выводить высокоуровневые карты свойств) и определение свойств, которые больше связаны с определенным классом. Поэтому в результате работы окончания сверточной сети по поданному на вход изображению с лужайкой, на которой, скажем, собака гоняется за птичкой, упрощенно можно сказать, что результатом может являться следующий вывод:
[dog (0.6), bird (0.35), cloud (0.05)].Свёрточная нейронная сеть GoogleNet
В 2014 году на том же соревновании ImageNet, где была представлена AlexNet, компания Google показала свою свёрточную нейросеть под названием GoogleNet. Отличительная особенность этой сети была в том, что она использовала в 12 раз меньше параметров (почувствуйте масштабы: 5 000 000 против 60 000 000) и её архитектура структурно была не похожа на архитектуру AlexNet, в которой было восемь слоёв, причём данная сеть давала более точный результат – 6,67% ошибки против 16,4%16.
Разработчики GoogleNet пытались избежать простого увеличения слоёв нейронной сети, потому что данный шаг привёл бы к значительному увеличению использования памяти и сеть была бы больше склонна к перенасыщению при обучении на небольшом и ограниченном наборе примеров.
Проанализируем приём, на который пошли разработчики компании Google для оптимизации скорости и использования памяти. В нейросети GoogleNet свёртка с размером фильтра 7×7 используется один раз в начале обработки изображения, далее максимальный размер – 5×5. Так как количество параметров при свёртке растёт квадратично с увеличением размерности ядра, нужно стараться заменять одну свёртку на несколько свёрток с меньшим размером фильтра, вместе с этим пропустить промежуточные результаты через ReLU (функция активации, возвращающая 0, если сигнал отрицателен, и само значение сигнала, если нет), чтобы внести дополнительную нелинейность. Например, свёртку с размером фильтра 5×5 можно заменить двумя последовательными операциями с размером ядра 3×3. Такая оптимизация позволяет строить более гибкие и глубокие сети. На хранение промежуточных свёрток тратится память, и использовать их более разумно в слоях, где размер карты признаков небольшой. Поэтому в начале сети GoogleNet вместо трёх свёрток 3×3 используется одна 7×7, чтобы избежать избыточного использования памяти.
Рис. 17. Первая реализация блока Inception.Схему архитектуры сети целиком мы приводить здесь не будем, она слишком громоздка и на ней трудно что-либо разглядеть, кому это будет интересно, могут ознакомиться с ней на официальном ресурсе16. Отличительной особенностью нейросети от компании Google является использование специального модуля – Inception (см. рис. 17). Данный модуль, по своей сути, является небольшой локальной сетью. Идея данного блока состоит в том, что на одну карту признаков накладывается сразу несколько свёрток разного размера, вычисляющихся параллельно. В конце все свёртки объединяются в единый блок. Таким образом, можно из исходной карты признаков извлечь признаки разного размера, увеличив эффективность сети и точность обработки признаков. Однако при использовании данной реализации (см. рис. 17) нужно выполнить колоссальный объём вычислений, между тем, при включении данных модулей друг за другом размерность блока будет только расти. Поэтому разработчики во второй версии добавили свёртки, уменьшающие размерность (см. рис. 18).
Рис. 18. Вторая реализация блока Inception.Жёлтые свёртки размера 1×1 введены для уменьшения глубины блоков, и благодаря им, значительно снижается нагрузка на память. GoogleNet содержит девять таких Inception-модулей и состоит из 22 слоёв.
Из-за большой глубины сети разработчики также столкнулись с проблемой затухания градиента при обучении (см. описание процедуры обучения нейросети: коррекция весов осуществляется в соответствии со значением ошибки, производной функции активации – градиента – и т.д.) и ввели два вспомогательных модуля классификатора (см. рис. 19). Данные модули представляют собой выходную часть малой свёрточной сети и уже частично классифицируют объект по внутренним характеристикам самой сети. При обучении нейронной сети данные модули не дают ошибке, распространяющиейся с конца, сильно уменьшиться, так как вводят в середину сети дополнительную ошибку.
Рис. 19. Вспомогательный модуль GoogleNet, использующийся при обучении сети.Ещё один полезный аспект в архитектуре GoogleNet, по мнению разработчиков, состоит в том, что сеть интуитивно правильно обрабатывает изображение: сначала картинка обрабатывается в разных масштабах, а затем результаты агрегируются. Такой подход больше соответствует тому, как подсознательно выполняет анализ окружения человек.
В 2015 году разработчики из Google представили модифицированный модуль Inception v2, в котором свёртка 5×5 была заменена на две свёртки 3×3, по причинам, приведённым выше, вдобавок потери информации в картах признаков при таком действии происходят незначительные, так как соседние ячейки имеют между собой сильную корреляционную связь. Также, если заменить свёртку 3×3 на две последовательные свёртки 3×1 и 1×3, то это будет на 33% эффективнее, чем стандартная свёртка, а две свёртки 2×2 дадут выигрыш лишь в 11%17. Данная архитектура нейросети давала ошибку 5,6%, а потребляла ресурсов в 2,5 раза меньше.
Стоит отметить, что точного алгоритма построения архитектуры нейросети не существует. Разработчики составляют свёрточные нейросети, основываясь на результатах экспериментов и собственном опыте.
Нейронную сеть можно использовать для точной классификации изображений, загруженных в глобальную сеть, либо использовать для сортировки фотографий по определённому признаку в галерее смартфона.
Свёрточная нейронная сеть имеет следующие преимущества: благодаря своей структуре, она позволяет значительно снизить количество весов в сравнении с полносвязанной нейронной сетью, её операции легко поддаются распараллеливанию, что положительно сказывается на скорости обучения и на скорости работы, данная архитектура лидирует в области классификации изображений, занимая первые места на соревновании ImageNet. Из-за того, что для сети более важно наличие признака, а не его место на изображении, она инвариантна к различным сдвигам и поворотам сканируемого изображения.
К недостаткам данной архитектуры можно отнести следующие: состав сети (количество её слоёв, функция активации, размерность свёрток, размерность pooling-слоёв, очередность слоёв и т.п.) необходимо подбирать эмпирически к определённому размеру и виду
изображения; сложность обучения: нейросети с хорошим показателем ошибки должны тренироваться на мощных GPU долгое время; и, наверное, главный недостаток – атаки на данные нейросети. Инженеры Google в 2015 году показали, что к картинке можно подмешать невидимый для человеческого зрения градиент, который приведёт к неправильной классификации.Нейронные сети: что такое, для чего нужны, как происходит обучение
Если вам когда-нибудь приходилось выбирать все изображения, на которых есть дорожные знаки, поздравляем: вы приложили руку к тренировке искусственного интеллекта. «Капча» Google призвана не только вычислить роботов (и заставить нас сомневаться в собственной человечности). Каждый раз, когда пользователь отмечает объекты на фото, нейронные сети Google становятся немного умнее, поиск по изображениям – точнее, Google Photos лучше находят лица, места и предметы в вашей фотобиблиотеке, а беспилотники Waymo реже сбивают людей и кошек.
Нейросети перестали быть фантастической технологией будущего (на самом деле, они никогда ею не были, но об этом позже) и стали широко использоваться бизнесом. А в последнее время доступ к ним получили все, у кого есть свободное время, мощный компьютер и интерес к программированию. Так, в сети стали появляться дипфейки – фото и видео, на которых лица людей (чаще всего знаменитостей) помещают на чужие тела. Именно нейросетям мы обязаны появлением президента Трампутина или Джима Керри в фильме «Сияние».
И все же для большинства людей устройство нейросетей остается загадкой, а результат их работы – сродни магии. Чтобы развеять туман, мы задали семь простых вопросов эксперту Ивану Лаптеву, руководителю исследований компании – разработчика технологий распознавания лиц VisionLabs и директору по исследованиям института INRIA в Париже.
1
Что такое нейросети?
Если упрощать, нейронная сеть – это программа, которая выполняет какую-то задачу. Такое звучное название она получила, поскольку ее устройство напоминает работу нейронов в мозгу. Но если в обычных программах все настройки задаются человеком, то нейросетям доверяют задачи, для решения которых необходимо указывать и корректировать десятки миллионов параметров. Настроить их вручную невозможно, это происходит автоматически.
Нейроны мозга под микроскопом
2
Какие задачи выполняют нейросети?
Facebook использует нейросети, чтобы распознать ваше лицо на чужих фото. Google – чтобы определять, что находится на картинках, и выдавать те, которые лучше всего соответствуют вашему запросу. Shazam учит нейронные сети распознавать песни даже в шумной комнате. Всевозможные голосовые помощники учат преобразовывать речь в текст. Беспилотные автомобили – распознавать разных участников дорожного движения. Одним словом, нейросети позволяют компьютерам воспринимать окружающий мир во всем его многообразии. Программе невозможно объяснить все обилие элементов, из которых складываются музыка, фотографии кошек или лица людей, но ее можно научить различать их самостоятельно.
3
Как происходит обучение?
Для обучения нейросети нужно большое количество изображений (музыкальных композиций, образцов речи и т. д.) с метками, то есть со значениями, которые вы хотели бы получить от сети, загрузив в нее эти картинки. Так, чтобы нейронная сеть научилась узнавать велосипедистов, ей нужны тысячи фотографий людей на велосипедах с соответствующей меткой. В процессе обучения сеть сама определяет элементы, которые она будет искать в других изображениях, чтобы распознать их с минимальным количеством ошибок. Иногда они совпадают с привычными нам деталями (если нейросеть решит, что узнавать собак ей помогают носы, она их запомнит), но чаще всего ее выбор не поддается интерпретации. В основе же всего лежит метод градиентного спуска, описанный еще в XX веке.
Нейросеть Google попросили преобразовать цифровой шум в известные ей объекты
4
Тогда почему бум нейросетей случился только сейчас?
Бум произошел, потому что мы достигли критической массы тренировочных данных и компьютерных мощностей. Еще 15 лет назад нейросети могли обладать, скажем, тысячей настраиваемых параметров. Этого хватало, чтобы справляться с простейшими задачами вроде распознавания букв, но не более того. Когда же в нашем распоряжении оказались сверхмощные компьютеры и огромное количество информации, нейросети стали работать в разы лучше, чем все применявшиеся ранее методы.
5
Как нейросети попали в руки программистов-любителей?
Видекоарты, на которых сегодня играют геймеры, в сотни раз мощнее компьютерной техники, которая 15 лет назад была доступна только профессионалам и исследователям. Кроме того, любой желающий может арендовать вычислительные мощности онлайн, например, через Amazon Web Services. А данные для тренировки нейросетей находятся в свободном доступе. Начать разбираться в нейронных сетях, создавать, учить и пользоваться ими может любой желающий.
Самый дорогой игровой компьютер 8Pack OrionX стоит больше $30 000 и вмещает четыре топовые видеокарты
6
Могут ли нейросети создавать изображения?
Преобразование одного изображения в другое – стандартная операция для любой нейронной сети. Когда сети выполняют задачи распознавания лиц, предметов или звуков, на выходе они выдают вектор или числовое значение, которое может относиться к тому или иному классу объектов. Но ничто не мешает настроить нейросеть так, чтобы в результате мы получали не число, а набор пикселей. Другой вопрос: как сделать так, чтобы этот набор походил на реальную фотографию или картинку, а не на бессмысленную абстракцию?
Тут на помощь приходит относительно новое изобретение – генеративно-состязательные сети (generative adversarial networks, сокращенно GANs). Если не углубляться в детали, устроены они довольно просто. Две нейронные сети соревнуются друг с другом: одна научена создавать изображения какого-то объекта, вторая натренирована различать его реальные и сгенерированные фотографии. Первая сеть пытается обмануть вторую и с каждой неудавшейся попыткой, получая от нее фидбек, начинает справляться с этой задачей немного лучше. Это происходит, пока нейросеть-тренер не перестанет видеть разницу между настоящими картинками и тем, что выдает ее оппонент.
Сайт thispersondoesnotexist.com генерирует фотографию человеческого лица при каждом обновлении страницы, этих людей не существует
7
Как заставить нейросеть сгенерировать лицо Джима Керри?
А для этого используют не обычные генеративно-состязательные сети, а так называемые conditional GANs. Чтобы получить правдоподобные фотографии Джима Керри (или любого другого человека), нейросеть-тренера учат именно на его фотографиях, тогда пройти ее проверку могут только изображения с лицом актера, которые практически невозможно отличить от реальных. А для того, чтобы это лицо говорило, кривилось и моргало, как в известном виральном видео, нейросеть снабжают фотографиями людей с разными выражениями лица – благо гримасничаем мы все довольно похожим образом.
Вероятно, вам также будет интересно:
Илон Маск научился вживлять чипы в мозг
Как заставить технологии приносить пользу?
Фото: Getty Images, 8Pack, Google
Часто проверяете почту? Пусть там будет что-то интересное от нас.
Нейронные сети
Нейронные сети – это одно из направлений исследований в области искусственного интеллекта, основанное на попытках воспроизвести нервную систему человека. А именно: способность нервной системы обучаться и исправлять ошибки, что должно позволить смоделировать, хотя и достаточно грубо, работу человеческого мозга.
Нейронная сеть или нервная система человека – это сложная сеть структур человека, обеспечивающая взаимосвязанное поведение всех систем организма.
Биологический нейрон – это специальная клетка, которая структурно состоит из ядра, тела клетки и отростков. Одной из ключевых задач нейрона является передача электрохимического импульса по всей нейронной сети через доступные связи с другими нейронами. Притом, каждая связь характеризуется некоторой величиной, называемой силой синаптической связи. Эта величина определяет, что произойдет с электрохимическим импульсом при передаче его другому нейрону: либо он усилится, либо он ослабится, либо останется неизменным.
Биологическая нейронная сеть обладает высокой степенью связности: на один нейрон может приходиться несколько тысяч связей с другими нейронами. Но, это приблизительное значение и в каждом конкретном случае оно разное. Передача импульсов от одного нейрона к другому порождает определенное возбуждение всей нейронной сети. Величина этого возбуждения определяет реакцию нейронной сети на какие-то входные сигналы. Например, встреча человека со старым знакомым может привести к сильному возбуждению нейронной сети, если с этим знакомым связаны какие-то яркие и приятные жизненные воспоминания. В свою очередь сильное возбуждение нейронной сети может привести к учащению сердцебиения, более частому морганию глаз и к другим реакциям. Встреча же с незнакомым человеком для нейронной сети пройдет практически незаметной, а значит и не вызовет каких-либо сильных реакций.
Можно привести следующую сильно упрощенную модель биологической нейронной сети:
Каждый нейрон состоит из тела клетки, которое содержит ядро. От тела клетки ответвляется множество коротких волокон, называемых дендритами. Длинные дендриты называются аксонами. Аксоны растягиваются на большие расстояния, намного превышающее то, что показано в масштабе этого рисунка. Обычно аксоны имеют длину 1 см (что превышает в 100 раз диаметр тела клетки), но могут достигать и 1 метра.
В 60-80 годах XX века приоритетным направлением исследований в области искусственного интеллекта были экспертные системы. Экспертные системы хорошо себя зарекомендовали, но только в узкоспециализированных областях. Для создания более универсальных интеллектуальных систем требовался другой подход. Наверное, это привело к тому, что исследователи искусственного интеллекта обратили внимание на биологические нейронные сети, которые лежат в основе человеческого мозга.
Нейронные сети в искусственном интеллекте – это упрощенные модели биологических нейронных сетей.
На этом сходство заканчивается. Структура человеческого мозга гораздо более сложная, чем описанная выше, и поэтому воспроизвести ее хотя бы более менее точно не представляется возможным.
У нейронных сетей много важных свойств, но ключевое из них – это способность к обучению. Обучение нейронной сети в первую очередь заключается в изменении «силы» синаптических связей между нейронами. Следующий пример наглядно это демонстрирует. В классическом опыте Павлова, каждый раз непосредственно перед кормлением собаки звонил колокольчик. Собака достаточно быстро научилась ассоциировать звонок колокольчика с приемом пищи. Это явилось следствием того, что синаптические связи между участками головного мозга, ответственными за слух и слюнные железы, усилились. И в последующем возбуждение нейронной сети звуком колокольчика, стало приводить к более сильному слюноотделению у собаки.
На сегодняшний день нейронные сети являются одним из приоритетных направлений исследований в области искусственного интеллекта.
Что такое нейронные сети? | IBM
Нейронные сети отражают поведение человеческого мозга, позволяя компьютерным программам распознавать закономерности и решать общие проблемы в области искусственного интеллекта, машинного обучения и глубокого обучения.
Что такое нейронные сети?
Нейронные сети, также известные как искусственные нейронные сети (ИНС) или моделируемые нейронные сети (СНС), представляют собой подмножество машинного обучения и лежат в основе алгоритмов глубокого обучения.Их название и структура вдохновлены человеческим мозгом, имитируя способ передачи сигналов друг другу биологических нейронов.
Искусственные нейронные сети (ИНС) состоят из узловых слоев, содержащих входной слой, один или несколько скрытых слоев и выходной слой. Каждый узел или искусственный нейрон соединяется с другим и имеет связанный вес и порог. Если выходной сигнал любого отдельного узла превышает заданное пороговое значение, этот узел активируется, отправляя данные на следующий уровень сети.В противном случае никакие данные не передаются на следующий уровень сети.
Нейронные сети полагаются на обучающие данные для обучения и повышения своей точности с течением времени. Однако, как только эти алгоритмы обучения настроены на точность, они становятся мощными инструментами в области информатики и искусственного интеллекта, позволяя нам классифицировать и кластеризовать данные с высокой скоростью. Задачи по распознаванию речи или изображений могут занимать минуты, а не часы, по сравнению с идентификацией вручную специалистами-людьми.Одна из самых известных нейронных сетей — это поисковый алгоритм Google.
Как работают нейронные сети?
Думайте о каждом отдельном узле как о своей собственной модели линейной регрессии, состоящей из входных данных, весов, смещения (или порога) и выходных данных. Формула будет выглядеть примерно так:
∑wixi + смещение = w1x1 + w2x2 + w3x3 + смещение
output = f (x) = 1, если ∑w1x1 + b> = 0; 0, если ∑w1x1 + b <0
После определения входного слоя назначаются веса.Эти веса помогают определить важность любой данной переменной, причем более крупные из них вносят более значительный вклад в результат по сравнению с другими входными данными. Затем все входные данные умножаются на их соответствующие веса и затем суммируются. После этого вывод проходит через функцию активации, которая определяет вывод. Если этот выходной сигнал превышает заданный порог, он «запускает» (или активирует) узел, передавая данные на следующий уровень в сети. Это приводит к тому, что выход одного узла становится входом следующего узла.Этот процесс передачи данных от одного уровня к следующему определяет эту нейронную сеть как сеть прямого распространения.
Давайте разберемся, как может выглядеть один единственный узел, используя двоичные значения. Мы можем применить эту концепцию к более осязаемому примеру, например, стоит ли вам заниматься серфингом (Да: 1, Нет: 0). Решение идти или не идти — это наш прогнозируемый результат, или н-хет. Предположим, на ваше решение влияют три фактора:
- Волны хорошие? (Да: 1, Нет: 0)
- Состав пуст? (Да: 1, Нет: 0)
- Было ли нападение акулы в последнее время? (Да: 0, Нет: 1)
Тогда предположим следующее, дав нам следующие входные данные:
- X1 = 1, так как волны накачиваются
- X2 = 0, так как толпы нет
- X3 = 1, поскольку нападения акул в последнее время не было.
Теперь нам нужно присвоить веса, чтобы определить важность.Большие веса означают, что определенные переменные имеют большее значение для решения или результата.
- W1 = 5, так как большие вздутия возникают нечасто
- W2 = 2, раз уж вы привыкли к толпе
- W3 = 4, так как вы боитесь акул
Наконец, мы также предположим, что пороговое значение равно 3, что соответствует значению смещения –3. Имея все различные входные данные, мы можем начать подставлять значения в формулу, чтобы получить желаемый результат.
Y-шляпа = (1 * 5) + (0 * 2) + (1 * 4) — 3 = 6
Если мы воспользуемся функцией активации из начала этого раздела, мы сможем определить, что на выходе этого узла будет 1, поскольку 6 больше 0. В этом случае вы будете заниматься серфингом; но если мы скорректируем веса или порог, мы сможем получить разные результаты от модели. Наблюдая за одним решением, как в приведенном выше примере, мы можем увидеть, как нейронная сеть может принимать все более сложные решения в зависимости от результатов предыдущих решений или уровней.
В приведенном выше примере мы использовали перцептроны, чтобы проиллюстрировать некоторые математические аспекты здесь, но нейронные сети используют сигмовидные нейроны, которые отличаются значениями от 0 до 1. Поскольку нейронные сети ведут себя аналогично деревьям решений, каскадно передавая данные из одного узел к другому, наличие значений x от 0 до 1 уменьшит влияние любого заданного изменения одной переменной на выход любого заданного узла, а затем и выход нейронной сети.
По мере того, как мы начинаем думать о более практических примерах использования нейронных сетей, таких как распознавание или классификация изображений, мы будем использовать контролируемое обучение или размеченные наборы данных для обучения алгоритма.2
В конечном итоге цель состоит в том, чтобы свести к минимуму нашу функцию затрат, чтобы гарантировать правильность подгонки для любого данного наблюдения. По мере того, как модель корректирует свои веса и смещение, она использует функцию стоимости и обучение с подкреплением, чтобы достичь точки сходимости или локального минимума. Процесс, в котором алгоритм корректирует свои веса, осуществляется посредством градиентного спуска, что позволяет модели определять направление, в котором следует двигаться, чтобы уменьшить ошибки (или минимизировать функцию стоимости). В каждом примере обучения параметры модели постепенно сходятся к минимуму.
См. Эту статью IBM Developer для более глубокого объяснения количественных концепций, используемых в нейронных сетях.
Большинство глубоких нейронных сетей имеют прямую связь, то есть они движутся только в одном направлении, от входа к выходу. Однако вы также можете обучить свою модель с помощью обратного распространения ошибки; то есть двигаться в противоположном направлении от вывода к вводу. Обратное распространение позволяет нам вычислить и приписать ошибку, связанную с каждым нейроном, что позволяет нам соответствующим образом настроить и подогнать параметры модели (моделей).
Типы нейронных сетей
Нейронные сети можно разделить на разные типы, которые используются для разных целей. Хотя это неполный список типов, ниже представлены наиболее распространенные типы нейронных сетей, с которыми вы столкнетесь в типичных случаях использования:
Персептрон — самая старая нейронная сеть, созданная Фрэнком Розенблаттом в 1958 году. Она состоит из одного нейрона и представляет собой простейшую форму нейронной сети:
Нейронные сети с прямой связью или многослойные перцептроны (MLP) — это то, на чем мы в первую очередь сосредоточились в этой статье.Они состоят из входного слоя, скрытого слоя или слоев и выходного слоя. Хотя эти нейронные сети также обычно называют MLP, важно отметить, что они на самом деле состоят из сигмовидных нейронов, а не перцептронов, поскольку большинство реальных проблем нелинейны. Данные обычно вводятся в эти модели для их обучения, и они являются основой для компьютерного зрения, обработки естественного языка и других нейронных сетей.
Сверточные нейронные сети (CNN) похожи на сети прямого распространения, но обычно используются для распознавания изображений, распознавания образов и / или компьютерного зрения.Эти сети используют принципы линейной алгебры, в частности, матричное умножение, для выявления закономерностей в изображении.
Рекуррентные нейронные сети (RNN) идентифицируются по их петлям обратной связи. Эти алгоритмы обучения в первую очередь используются при использовании данных временных рядов для прогнозирования будущих результатов, например прогнозов фондового рынка или прогнозирования продаж.
Нейронные сети и глубокое обучение
Deep Learning и нейронные сети, как правило, взаимозаменяемы в разговоре, что может сбивать с толку.В результате стоит отметить, что «глубокое» в глубоком обучении означает просто глубину слоев в нейронной сети. Нейронная сеть, состоящая из более чем трех слоев, включая входные и выходные данные, может считаться алгоритмом глубокого обучения. Нейронная сеть, состоящая всего из двух или трех слоев, — это просто базовая нейронная сеть.
Чтобы узнать больше о различиях между нейронными сетями и другими формами искусственного интеллекта, такими как машинное обучение, прочтите сообщение в блоге «AI vs.Машинное обучение, глубокое обучение и нейронные сети: в чем разница? »
История нейронных сетей
История нейронных сетей длиннее, чем думает большинство людей. Хотя идея «машины, которая думает» восходит к древним грекам, мы сосредоточимся на ключевых событиях, которые привели к эволюции мышления вокруг нейронных сетей, популярность которой с годами снижалась и уменьшалась:
1943: Уоррен С. Маккалок и Уолтер Питтс опубликовали «Логический расчет идей, присущих нервной деятельности (PDF, 1 МБ) (ссылка находится вне IBM)». Это исследование было направлено на то, чтобы понять, как человеческий мозг может создавать сложные модели через связанные клетки мозга или нейроны.Одной из основных идей, которые возникли в результате этой работы, было сравнение нейронов с бинарным порогом с булевой логикой (т. Е. С утверждениями 0/1 или истинным / ложным).
1958: Фрэнку Розенблатту приписывают разработку перцептрона, описанного в его исследовании «Персептрон: вероятностная модель хранения и организации информации в мозге» (PDF, 1,6 МБ) (ссылка находится вне IBM). Он продвигает работу Маккаллоха и Питта на шаг вперед, вводя веса в уравнение.Используя IBM 704, Розенблатт смог заставить компьютер научиться отличать карты, отмеченные слева, от карт, отмеченных справа.
1974: В то время как многочисленные исследователи внесли свой вклад в идею обратного распространения ошибки, Пол Вербос был первым человеком в США, который отметил его применение в нейронных сетях в своей докторской диссертации (PDF, 8,1 МБ) (ссылка находится за пределами IBM).
1989: Ян ЛеКун опубликовал статью (PDF, 5,7 МБ) (ссылка находится за пределами IBM), в которой показано, как использование ограничений в обратном распространении и его интеграция в архитектуру нейронной сети может использоваться для обучения алгоритмов.В этом исследовании успешно использовалась нейронная сеть для распознавания рукописных цифр почтового индекса, предоставленного почтовой службой США.
Нейронные сети и IBM Cloud
Вот уже несколько десятилетий IBM является пионером в разработке технологий искусственного интеллекта и нейронных сетей, что подтверждается развитием и развитием IBM Watson. Watson теперь является надежным решением для предприятий, которые хотят применить в своих системах передовые методы обработки естественного языка и глубокого обучения, используя проверенный многоуровневый подход к внедрению и внедрению искусственного интеллекта.
Watson использует инфраструктуру Apache Unstructured Information Management Architecture (UIMA) и программное обеспечение IBM DeepQA, чтобы сделать мощные возможности глубокого обучения доступными для приложений. Используя такие инструменты, как IBM Watson Studio, ваше предприятие может беспрепятственно внедрять проекты ИИ с открытым исходным кодом в производство при развертывании и запуске моделей в любом облаке.
Для получения дополнительной информации о том, как начать работу с технологией глубокого обучения, изучите IBM Watson Studio и службу Deep Learning.
Зарегистрируйтесь в IBMid и создайте свою учетную запись IBM Cloud.
Что такое рекуррентные нейронные сети?
Узнайте, как рекуррентные нейронные сети используют последовательные данные для решения общих временных проблем, возникающих при языковом переводе и распознавании речи.
Что такое рекуррентные нейронные сети?Рекуррентная нейронная сеть (RNN) — это тип искусственной нейронной сети, которая использует последовательные данные или данные временных рядов.Эти алгоритмы глубокого обучения обычно используются для порядковых или временных задач, таких как языковой перевод, обработка естественного языка (nlp), распознавание речи и добавление субтитров к изображениям; они включены в популярные приложения, такие как Siri, голосовой поиск и Google Translate. Как и нейронные сети с прямой связью и сверточные нейронные сети (CNN), рекуррентные нейронные сети используют обучающие данные для обучения. Они отличаются своей «памятью», поскольку они берут информацию из предыдущих входов, чтобы влиять на текущий вход и выход.В то время как традиционные глубокие нейронные сети предполагают, что входы и выходы независимы друг от друга, выходные данные рекуррентных нейронных сетей зависят от предшествующих элементов в последовательности. Хотя будущие события также могут быть полезны при определении выходных данных данной последовательности, однонаправленные рекуррентные нейронные сети не могут учитывать эти события в своих прогнозах.
Рекуррентная нейронная сеть против нейронной сети прямого распространенияСравнение рекуррентных нейронных сетей (слева) и нейронных сетей прямого распространения (справа)
Давайте возьмем идиому, такую как «чувство непогоды», которая обычно используется, когда кто-то болен, чтобы помочь нам в объяснении RNN.Чтобы идиома имела смысл, она должна быть выражена в определенном порядке. В результате повторяющиеся сети должны учитывать положение каждого слова в идиоме, и они используют эту информацию для предсказания следующего слова в последовательности.
Глядя на изображение ниже, «свернутое» изображение RNN представляет собой всю нейронную сеть, или, скорее, всю предсказанную фразу, например, «ощущение непогоды». «Развернутый» визуал представляет отдельные слои или временные шаги нейронной сети.Каждому слою соответствует одно слово в этой фразе, например «погода». Предыдущие входные данные, такие как «ощущение» и «ниже», будут представлены как скрытое состояние на третьем временном шаге для прогнозирования выходных данных в последовательности «the».
Другой отличительной особенностью рекуррентных сетей является то, что они разделяют параметры на каждом уровне сети. В то время как сети с прямой связью имеют разные веса для каждого узла, рекуррентные нейронные сети имеют один и тот же параметр веса на каждом уровне сети.Тем не менее, эти веса все еще корректируются в процессе обратного распространения ошибки и градиентного спуска, чтобы облегчить обучение с подкреплением.
Рекуррентные нейронные сети используют алгоритм обратного распространения во времени (BPTT) для определения градиентов, который немного отличается от традиционного обратного распространения, поскольку он специфичен для данных последовательности. Принципы BPTT такие же, как и при традиционном обратном распространении, где модель обучается, вычисляя ошибки от выходного уровня до входного.Эти расчеты позволяют нам соответствующим образом скорректировать и подогнать параметры модели. BPTT отличается от традиционного подхода тем, что BPTT суммирует ошибки на каждом временном шаге, тогда как в сетях прямого распространения нет необходимости суммировать ошибки, поскольку они не разделяют параметры на каждом уровне.
В ходе этого процесса RNN, как правило, сталкиваются с двумя проблемами, известными как взрывные градиенты и исчезающие градиенты. Эти проблемы определяются размером градиента, который представляет собой наклон функции потерь вдоль кривой ошибки.Когда градиент слишком мал, он продолжает уменьшаться, обновляя весовые параметры до тех пор, пока они не станут несущественными, т.е. 0. Когда это происходит, алгоритм больше не обучается. Взрывные градиенты возникают, когда градиент слишком большой, что создает нестабильную модель. В этом случае веса модели станут слишком большими и в конечном итоге будут представлены как NaN. Одним из решений этих проблем является уменьшение количества скрытых слоев в нейронной сети, что устраняет некоторые сложности в модели RNN.
Типы рекуррентных нейронных сетей Сети прямого распространениясопоставляют один вход с одним выходом, и хотя мы визуализировали рекуррентные нейронные сети таким образом на приведенных выше диаграммах, на самом деле у них нет этого ограничения. Вместо этого их входные и выходные данные могут различаться по длине, и разные типы RNN используются для разных случаев использования, таких как создание музыки, классификация настроений и машинный перевод. Различные типы RNN обычно выражаются с помощью следующих диаграмм:
Один к одному:
Один ко многим:
Многие к одному:
Многие ко многим:
Многие ко многим:
Общие функции активацииКак обсуждалось в статье Learn о нейронных сетях, функция активации определяет, следует ли активировать нейрон.-Икс).
Relu: Это представлено формулой g (x) = max (0, x)
Варианты архитектуры RNNДвунаправленные рекуррентные нейронные сети (BRNN): Это вариант сетевой архитектуры RNN. В то время как однонаправленные RNN могут извлекаться только из предыдущих входных данных для прогнозирования текущего состояния, двунаправленные RNN извлекают будущие данные для повышения их точности. Если мы вернемся к примеру «чувствовать себя нездоровым» ранее в этой статье, модель может лучше предсказать, что второе слово в этой фразе будет «под», если она знает, что последнее слово в последовательности — «погода».”
Долговременная краткосрочная память (LSTM) : это популярная архитектура RNN, которая была представлена Зеппом Хохрайтером и Юргеном Шмидхубером как решение проблемы исчезающего градиента. В своей статье (PDF, 388 КБ) (ссылка находится за пределами IBM) они работают над решением проблемы долгосрочных зависимостей. То есть, если предыдущее состояние, которое влияет на текущий прогноз, не находится в недавнем прошлом, модель RNN может быть не в состоянии точно прогнозировать текущее состояние. В качестве примера предположим, что мы хотели предсказать слова, выделенные курсивом в следующем: «У Алисы аллергия на орехи.Она не может есть арахисовое масло «. Контекст аллергии на орехи может помочь нам предвидеть, что пища, которую нельзя есть, содержит орехи. Однако, если бы этот контекст был на несколько предложений раньше, тогда для RNN было бы сложно или даже невозможно связать информацию. Чтобы исправить это, LSTM имеют «ячейки» в скрытых слоях нейронной сети, которые имеют три логических элемента: входной вентиль, выходной вентиль и вентиль забывания. Эти шлюзы управляют потоком информации, необходимой для прогнозирования выходных данных в сети.Например, если местоимения рода, такие как «она», повторялись несколько раз в предыдущих предложениях, вы можете исключить это из состояния ячейки.
Стробированные повторяющиеся блоки (GRU): Этот вариант RNN похож на LSTM, поскольку он также работает для решения проблемы краткосрочной памяти моделей RNN. Вместо использования регулирующей информации о «состоянии ячейки» он использует скрытые состояния и вместо трех ворот имеет два — ворота сброса и ворота обновления. Подобно воротам в LSTM, шлюзы сброса и обновления контролируют, сколько и какую информацию сохранять.
Рекуррентные нейронные сети и IBM CloudВот уже несколько десятилетий IBM является пионером в разработке технологий искусственного интеллекта и нейронных сетей, что подтверждается развитием и развитием IBM Watson. Watson теперь является надежным решением для предприятий, которые хотят применить в своих системах передовые методы обработки естественного языка и глубокого обучения, используя проверенный многоуровневый подход к внедрению и внедрению искусственного интеллекта.
Продукты IBM, такие как IBM Watson Machine Learning, также поддерживают популярные библиотеки Python, такие как TensorFlow, Keras и PyTorch, которые обычно используются в повторяющихся нейронных сетях.Используя такие инструменты, как IBM Watson Studio и Watson Machine Learning, ваше предприятие может беспрепятственно внедрять свои проекты ИИ с открытым исходным кодом в производство, развертывая и выполняя свои модели в любом облаке.
Для получения дополнительной информации о том, как начать работу с технологией искусственного интеллекта, изучите IBM Watson Studio.
Зарегистрируйтесь в IBMid и создайте свою учетную запись IBM Cloud.
AI против машинного обучения против глубокого обучения противНейронные сети: в чем разница?
Эти термины часто используются как синонимы, но каковы различия, которые делают каждый из них уникальной технологией?
Технологии с каждой минутой все больше внедряются в нашу повседневную жизнь, и, чтобы идти в ногу с ожиданиями потребителей, компании все больше полагаются на алгоритмы обучения, чтобы упростить задачу. Вы можете увидеть его применение в социальных сетях (через распознавание объектов на фотографиях) или в разговоре напрямую с устройствами (такими как Alexa или Siri).
Эти технологии обычно ассоциируются с искусственным интеллектом, машинным обучением, глубоким обучением и нейронными сетями, и хотя все они играют определенную роль, эти термины, как правило, используются взаимозаменяемо в разговоре, что приводит к некоторой путанице в отношении нюансов между ними. Надеюсь, мы сможем использовать это сообщение в блоге, чтобы прояснить здесь некоторую двусмысленность.
Как связаны искусственный интеллект, машинное обучение, нейронные сети и глубокое обучение?
Возможно, самый простой способ думать об искусственном интеллекте, машинном обучении, нейронных сетях и глубоком обучении — это думать о них как о русских матрешках.Каждый из них по сути является составной частью предыдущего термина.
То есть машинное обучение — это подраздел искусственного интеллекта. Глубокое обучение — это подраздел машинного обучения, а нейронные сети составляют основу алгоритмов глубокого обучения. Фактически, именно количество узловых слоев или глубина нейронных сетей отличает одну нейронную сеть от алгоритма глубокого обучения, которого должно быть больше трех.
Что такое нейронная сеть?
Нейронные сети, а точнее искусственные нейронные сети (ИНС), имитируют человеческий мозг с помощью набора алгоритмов.На базовом уровне нейронная сеть состоит из четырех основных компонентов: входов, весов, смещения или порога и выхода. Подобно линейной регрессии, алгебраическая формула будет выглядеть примерно так:
Теперь применим его к более осязаемому примеру, например, следует ли вам заказывать пиццу на ужин. Это будет наш прогнозируемый результат, или y-hat. Предположим, что есть три основных фактора, которые повлияют на ваше решение:
- Если вы сэкономите время, сделав заказ (Да: 1; Нет: 0)
- Если вы похудеете, заказав пиццу (Да: 1; Нет: 0)
- Если сэкономите (Да: 1; Нет: 0)
Тогда предположим следующее, дав нам следующие входные данные:
- X 1 = 1, так как вы не готовите ужин
- X2 = 0, так как мы получаем ВСЕ начинки
- X 3 = 1, так как мы получаем только 2 фрагмента
Для простоты наши входные данные будут иметь двоичное значение 0 или 1.Технически это определяет его как перцептрон, поскольку нейронные сети в основном используют сигмовидные нейроны, которые представляют значения от отрицательной бесконечности до положительной бесконечности. Это различие важно, поскольку большинство реальных проблем нелинейны, поэтому нам нужны значения, которые уменьшают влияние любого отдельного ввода на результат. Однако такое обобщение поможет вам понять лежащую в основе математику.
Двигаясь дальше, теперь нам нужно присвоить некоторые веса, чтобы определить важность.Большие веса делают вклад одного входа в результат более значительным по сравнению с другими входами.
- W 1 = 5, так как вы цените время
- W 2 = 3, так как вы цените форму
- W 3 = 2, так как у вас деньги в банке
Наконец, мы также предположим, что пороговое значение равно 5, что соответствует значению смещения –5.
Поскольку мы установили все соответствующие значения для нашего суммирования, теперь мы можем подставить их в эту формулу.
Теперь, используя следующую функцию активации, мы можем рассчитать выход (т.е. наше решение заказать пиццу):
Итого:
Y-шляпа (наш прогноз) = Решить, заказывать пиццу или нет
Y-шляпа = (1 * 5) + (0 * 3) + (1 * 2) — 5
Y-шляпа = 5 + 0 + 2 — 5
Y-шляпа = 2, что больше нуля.
Поскольку Y-hat равно 2, вывод из функции активации будет 1, , что означает, что мы будем заказывать пиццу (я имею в виду, кто не любит пиццу).
Если выходной сигнал любого отдельного узла превышает заданное пороговое значение, этот узел активируется, отправляя данные на следующий уровень сети. В противном случае никакие данные не передаются на следующий уровень сети. Теперь представьте, что описанный выше процесс повторяется несколько раз для одного решения, поскольку нейронные сети, как правило, имеют несколько «скрытых» слоев как часть алгоритмов глубокого обучения. Каждый скрытый слой имеет свою функцию активации, потенциально передавая информацию из предыдущего слоя в следующий.После того, как все выходные данные скрытых слоев сгенерированы, они используются в качестве входных данных для расчета окончательного выхода нейронной сети. Опять же, приведенный выше пример — это просто самый простой пример нейронной сети; большинство реальных примеров нелинейны и намного сложнее.
Основное различие между регрессией и нейронной сетью — это влияние изменения на один вес. В регрессии вы можете изменить вес, не затрагивая другие входные данные функции. Однако это не относится к нейронным сетям.Поскольку выходные данные одного уровня передаются на следующий уровень сети, одно изменение может иметь каскадный эффект на другие нейроны в сети.
См. Эту статью IBM Developer для более глубокого объяснения количественных концепций, используемых в нейронных сетях.
Чем глубокое обучение отличается от нейронных сетей?
Хотя это подразумевалось в объяснении нейронных сетей, стоит отметить более подробно. «Глубина» в глубоком обучении относится к глубине слоев нейронной сети.Нейронная сеть, состоящая из более чем трех слоев, включая входные и выходные данные, может считаться алгоритмом глубокого обучения. Обычно это представлено на следующей диаграмме:
Большинство глубоких нейронных сетей имеют прямую связь, то есть они движутся только в одном направлении от входа к выходу. Однако вы также можете обучить свою модель с помощью обратного распространения ошибки; то есть двигаться в противоположном направлении от вывода к вводу. Обратное распространение позволяет нам вычислить и приписать ошибку, связанную с каждым нейроном, что позволяет нам соответствующим образом настроить и подогнать алгоритм.
Чем глубокое обучение отличается от машинного обучения?
Как мы объясняем в нашей статье Learn Hub о глубоком обучении, глубокое обучение — это просто подмножество машинного обучения. Основное различие между ними заключается в том, как каждый алгоритм учится и сколько данных использует каждый тип алгоритма. Глубокое обучение автоматизирует большую часть процесса извлечения признаков, устраняя необходимость в ручном вмешательстве человека. Он также позволяет использовать большие наборы данных, за что в этой лекции Массачусетского технологического института назван «масштабируемым машинным обучением».Эта возможность будет особенно интересна, когда мы начнем больше исследовать использование неструктурированных данных, особенно с учетом того, что 80-90% данных организации оценивается как неструктурированные.
Классическое, или «неглубокое», машинное обучение больше зависит от вмешательства человека. Специалисты-люди определяют иерархию функций, чтобы понять различия между входными данными, обычно для изучения требуются более структурированные данные. Например, предположим, что я должен был показать вам серию изображений различных видов фаст-фуда, «пиццы», «бургера» или «тако».«Человек-эксперт по этим изображениям определил бы характеристики, которые отличают каждую картинку как конкретный тип фаст-фуда. Например, хлеб каждого типа пищи может быть отличительной чертой на каждой картинке. В качестве альтернативы вы можете просто использовать ярлыки, такие как «пицца», «бургер» или «тако», чтобы упростить процесс обучения посредством обучения с учителем.
«Глубокое» машинное обучение может использовать помеченные наборы данных, также известные как контролируемое обучение, для информирования своего алгоритма, но для этого необязательно наличие помеченного набора данных.Он может принимать неструктурированные данные в необработанном виде (например, текст, изображения) и может автоматически определять набор функций, которые отличают друг от друга «пиццу», «бургер» и «тако».
Для более глубокого понимания различий между этими подходами ознакомьтесь с разделом «Обучение с учителем и обучение без учителя: в чем разница?»
Наблюдая закономерности в данных, модель глубокого обучения может соответствующим образом кластеризовать входные данные. Взяв тот же пример из предыдущего, мы могли бы сгруппировать изображения пиццы, гамбургеров и тако по соответствующим категориям на основе сходства или различий, выявленных на изображениях.С учетом сказанного, модели глубокого обучения потребуется больше точек данных для повышения ее точности, тогда как модель машинного обучения полагается на меньшее количество данных с учетом базовой структуры данных. Глубокое обучение в первую очередь используется для более сложных случаев использования, таких как виртуальные помощники или обнаружение мошенничества.
Что такое искусственный интеллект (ИИ)?
Наконец, искусственный интеллект (ИИ) — это самый широкий термин, используемый для классификации машин, имитирующих человеческий интеллект. Он используется для прогнозирования, автоматизации и оптимизации задач, которые люди исторически выполняли, таких как распознавание речи и лиц, принятие решений и перевод.
Существует три основных категории AI:
- Искусственный узкий интеллект (ANI)
- Общий искусственный интеллект (AGI)
- Искусственный суперинтеллект (ИСИ)
ANI считается «слабым» ИИ, тогда как два других типа классифицируются как «сильные». Слабый ИИ определяется его способностью выполнять очень конкретную задачу, например, выиграть в шахматы или идентифицировать конкретного человека на серии фотографий. По мере того, как мы переходим к более сильным формам ИИ, таким как AGI и ASI, становится более заметным включение большего количества человеческих форм поведения, таких как способность интерпретировать тон и эмоции.Чат-боты и виртуальные помощники, такие как Siri, поверхностно относятся к этому, но они все еще являются примерами ANI.
Сильный ИИ определяется его способностями по сравнению с людьми. Общий искусственный интеллект (AGI) будет работать наравне с другим человеком, в то время как искусственный суперинтеллект (ASI), также известный как суперинтеллект, превзойдет человеческий интеллект и способности. Ни одной из форм сильного ИИ пока не существует, но исследования в этой области продолжаются. Поскольку эта область ИИ все еще быстро развивается, лучшим примером, который я могу предложить, как это могло бы выглядеть, является Долорес из сериала HBO Westworld .
Управляйте своими данными для AI
Хотя все эти области ИИ могут помочь оптимизировать области вашего бизнеса и улучшить качество обслуживания клиентов, достижение целей ИИ может быть сложной задачей, потому что сначала вам нужно убедиться, что у вас есть правильные системы для управления данными для построения алгоритмы обучения. Управление данными, возможно, сложнее, чем создание реальных моделей, которые вы будете использовать для своего бизнеса. Вам понадобится место для хранения ваших данных и механизмы для их очистки и контроля предвзятости, прежде чем вы сможете начать что-либо создавать.Ознакомьтесь с некоторыми предложениями продуктов IBM, которые помогут вам и вашему бизнесу встать на правильный путь для подготовки и масштабного управления данными.
Что такое искусственная нейронная сеть (ИНС)?
Что такое нейронная сеть?В информационных технологиях (ИТ) искусственная нейронная сеть (ИНС) — это система оборудования и / или программного обеспечения, созданная по образцу работы нейронов в человеческом мозгу. ИНС, также называемые просто нейронными сетями, представляют собой разновидность технологии глубокого обучения, которая также подпадает под действие искусственного интеллекта или ИИ.
Коммерческое применение этих технологий обычно сосредоточено на решении сложных задач обработки сигналов или распознавания образов. Примеры важных коммерческих приложений с 2000 года включают распознавание почерка для обработки чеков, преобразование речи в текст, анализ данных разведки нефти, прогноз погоды и распознавание лиц.
История искусственных нейронных сетей восходит к ранним дням развития вычислительной техники. В 1943 году математики Уоррен МакКаллох и Уолтер Питтс построили систему схем, предназначенную для приближения функционирования человеческого мозга, которая выполняла простые алгоритмы.
Исследования возобновились только в 2010 году. Тенденция к большим данным, когда компании накапливают огромные массивы данных, а параллельные вычисления предоставили специалистам по обработке данных данные для обучения и вычислительные ресурсы, необходимые для работы сложных искусственных нейронных сетей. В 2012 году нейронная сеть смогла превзойти человеческую производительность в задаче распознавания изображений в рамках конкурса ImageNet. С тех пор интерес к искусственным нейронным сетям резко возрос, и технология продолжает совершенствоваться.
Как работают искусственные нейронные сетиИНС обычно включает в себя большое количество процессоров, работающих параллельно и расположенных по уровням. Первый уровень получает необработанную входную информацию — аналог зрительных нервов в обработке человеческого зрения. Каждый последующий уровень получает выходные данные от предшествующего ему уровня, а не необработанные входные данные — точно так же нейроны, расположенные дальше от зрительного нерва, получают сигналы от тех, кто находится ближе к нему. Последний уровень производит вывод системы.
У каждого узла обработки есть своя небольшая сфера знаний, включая то, что он видел, и любые правила, которые он изначально запрограммировал или разработал для себя. Уровни сильно взаимосвязаны, что означает, что каждый узел на уровне n будет подключен ко многим узлам на уровне n-1 — его входы — и на уровне n + 1, , который предоставляет входные данные для этих узлов. . В выходном слое может быть один или несколько узлов, из которых можно прочитать полученный ответ.
Искусственные нейронные сети отличаются своей адаптивностью, что означает, что они изменяют себя по мере обучения в ходе первоначального обучения, а последующие прогоны предоставляют больше информации о мире. Самая базовая модель обучения сосредоточена на взвешивании входных потоков, то есть на том, как каждый узел взвешивает важность входных данных от каждого из своих предшественников. Вклады, которые способствуют получению правильных ответов, имеют больший вес.
Как нейронные сети учатсяОбычно ИНС изначально обучается или получает большие объемы данных.Обучение состоит из предоставления входных данных и сообщения сети, каким должен быть результат. Например, для построения сети, которая идентифицирует лица актеров, начальное обучение может представлять собой серию изображений, включая актеров, не актеров, маски, скульптуры и лица животных. Каждый ввод сопровождается соответствующей идентификацией, такой как имена актеров или информация «не актер» или «не человек». Предоставление ответов позволяет модели скорректировать свои внутренние веса, чтобы научиться лучше выполнять свою работу.
Например, если узлы Дэвид, Дайанна и Дакота сообщают узлу Эрни, что текущее входное изображение — это изображение Брэда Питта, но узел Дуранго говорит, что это Бетти Уайт, и программа обучения подтверждает, что это Питт, Эрни уменьшит присвоенный ему вес. на вклад Дуранго и увеличить вес, который он придает Дэвиду, Дайанне и Дакоте.
При определении правил и принятии решений — то есть решения каждого узла о том, что отправлять на следующий уровень на основе входных данных с предыдущего уровня — нейронные сети используют несколько принципов.К ним относятся обучение на основе градиента, нечеткая логика, генетические алгоритмы и байесовские методы. Им могут быть даны некоторые основные правила относительно объектных отношений в моделируемых данных.
Например, система распознавания лиц может получить команду: «Брови находятся над глазами» или «Усы находятся под носом. Усы находятся над и / или рядом со ртом». Правила предварительной загрузки могут ускорить обучение и сделать модель более мощной. Но он также строится на предположениях о природе проблемы, которые могут оказаться либо неуместными и бесполезными, либо неправильными и контрпродуктивными, что позволяет принять решение о том, какие правила следует использовать, если таковые имеются, очень важным.
Кроме того, предположения, которые люди делают при обучении алгоритмов, заставляют нейронные сети усиливать культурные предубеждения. Предвзятые наборы данных — постоянная проблема в обучающих системах, которые самостоятельно находят ответы, распознавая закономерности в данных. Если данные, поступающие в алгоритм, не нейтральны — а данных почти нет — машина распространяет смещение.
Нейронные сети и другие системы машинного обучения могут усиливать предвзятость Типы нейронных сетейНейронные сети иногда описывают с точки зрения их глубины, включая количество слоев между входом и выходом или так называемые скрытые слои модели.Вот почему термин нейронная сеть используется почти как синоним глубокого обучения. Их также можно описать количеством скрытых узлов, которые есть в модели, или количеством входов и выходов у каждого узла. Вариации классического дизайна нейронной сети позволяют использовать различные формы прямого и обратного распространения информации между уровнями.
Конкретные типы искусственных нейронных сетей включают:
- Нейронные сети с прямой связью: один из простейших вариантов нейронных сетей.Они передают информацию в одном направлении через различные входные узлы, пока не попадут в выходной узел. Сеть может иметь или не иметь скрытых узловых слоев, что делает их функционирование более понятным. Он подготовлен к обработке большого количества шума. Этот тип вычислительной модели ИНС используется в таких технологиях, как распознавание лиц и компьютерное зрение.
- Рекуррентные нейронные сети: сложнее. Они сохраняют выходные данные узлов обработки и возвращают результат в модель.Говорят, что именно так модель учится предсказывать результат слоя. Каждый узел в модели RNN действует как ячейка памяти, продолжая вычисления и выполнение операций. Эта нейронная сеть начинается с того же переднего распространения, что и сеть с прямой связью, но затем продолжает запоминать всю обработанную информацию, чтобы повторно использовать ее в будущем. Если предсказание сети неверно, то система самообучается и продолжает работать над правильным предсказанием во время обратного распространения.Этот тип ИНС часто используется при преобразовании текста в речь.
- Сверточные нейронные сети: одна из самых популярных моделей, используемых сегодня. Эта вычислительная модель нейронной сети использует вариант многослойных перцептронов и содержит один или несколько сверточных слоев, которые могут быть либо полностью связаны, либо объединены. Эти сверточные слои создают карты характеристик, которые записывают область изображения, которая в конечном итоге разбивается на прямоугольники и отправляется для нелинейного преобразования. Модель CNN особенно популярна в области распознавания изображений; он использовался во многих самых передовых приложениях искусственного интеллекта, включая распознавание лиц, оцифровку текста и обработку естественного языка.Другие применения включают обнаружение перефразирования, обработку сигналов и классификацию изображений.
- Деконволюционные нейронные сети: используйте процесс обратной модели CNN. Они стремятся найти потерянные функции или сигналы, которые изначально могли считаться несущественными для задачи системы CNN. Эта сетевая модель может использоваться при синтезе и анализе изображений.
- Модульные нейронные сети: содержат несколько нейронных сетей, работающих отдельно друг от друга. Сети не взаимодействуют друг с другом и не мешают друг другу в процессе вычислений.Следовательно, сложные или большие вычислительные процессы могут выполняться более эффективно.
К преимуществам искусственных нейронных сетей можно отнести:
- Возможности параллельной обработки означают, что сеть может выполнять более одного задания одновременно.
- Информация хранится во всей сети, а не только в базе данных.
- Способность учиться и моделировать нелинейные сложные отношения помогает моделировать реальные отношения между вводом и выводом.
- Отказоустойчивость означает, что повреждение одной или нескольких ячеек ИНС не остановит генерацию вывода.
- Постепенное повреждение означает, что сеть со временем будет медленно деградировать, вместо того, чтобы проблема мгновенно разрушала сеть.
- Способность производить выходные данные с неполными знаниями с потерей производительности в зависимости от того, насколько важна недостающая информация.
- На входные переменные не накладываются никакие ограничения, например на то, как они должны распределяться.
- Машинное обучение означает, что ИНС может учиться на событиях и принимать решения на основе наблюдений.
- Способность изучать скрытые взаимосвязи в данных без указания каких-либо фиксированных взаимосвязей означает, что ИНС может лучше моделировать очень изменчивые данные и непостоянную дисперсию.
- Способность обобщать и выводить невидимые отношения на невидимых данных означает, что ИНС могут предсказывать вывод невидимых данных.
К недостаткам ИНС можно отнести:
- Отсутствие правил для определения правильной структуры сети означает, что подходящую архитектуру искусственной нейронной сети можно найти только путем проб, ошибок и опыта.
- Требование процессоров с возможностью параллельной обработки делает нейронные сети зависимыми от оборудования.
- Сеть работает с числовой информацией, поэтому все проблемы должны быть переведены в числовые значения, прежде чем они могут быть представлены в ИНС.
- Отсутствие объяснения решений для зондирования — один из самых больших недостатков ИНС. Неспособность объяснить, почему и как стоит решение, вызывает недоверие к сети.
Распознавание изображений было одной из первых областей, в которых были успешно применены нейронные сети, но эта технология распространилась на многие другие области, в том числе:
- Чат-боты
- Обработка естественного языка, перевод и создание языка
- Прогноз фондового рынка
- Планирование и оптимизация маршрута водителем-доставщиком
- Открытие и разработка лекарств
Это лишь несколько конкретных областей, в которых нейронные сети применяются сегодня.Использование Prime включает любой процесс, который работает в соответствии со строгими правилами или шаблонами и имеет большие объемы данных. Если задействованные данные слишком велики, чтобы человек мог их понять за разумное время, процесс, вероятно, станет главным кандидатом на автоматизацию с помощью искусственных нейронных сетей.
Чтобы узнать больше о том, чем разные типы нейронных сетей отличаются друг от друга и как их используют компании, перейдите по ссылкам здесь, чтобы перейти к остальной части нашего обзора по этой теме.
Neural Networks — обзор
Dream-Like Neural Network Processing
ANN предназначены для включения операций на основе нейронных ячеек общей обработки включения-выключения, множественных соединений, нескольких уровней и динамической обратной связи, происходящей во временной последовательности или в искусственные псевдовременные пространства.Эти процессы включают связанные процессы ассоциативной, многоуровневой памяти и когнитивной обратной связи. Для многих людей сновидения обеспечивают обратную связь с пониманием когнитивных функций ЦНС, особенно функций, которые происходят во время сна. Обработка нейронной сети, принимая сновидческие процессы когнитивной обратной связи и многоуровневой ассоциативной памяти, является попыткой пародировать биологические процессы сновидения.
Обратная связь нейронной сети, однако, гораздо более специфична в ее попытке управлять дискретными точками данных.Системы, разработанные в настоящее время, включают гораздо меньшее количество искусственных нейронов, чем биологические системы. Таким образом, достигаемые уровни сложности довольно низкие. Однако, как уже отмечалось, даже на уровнях низкой сложности в строго контролируемых системах, использующих несколько уровней нейронной обратной связи, дискретный и ограниченный анализ данных трудно обучить и контролировать. Неполное обучение становится серьезной проблемой, если приводит к нарушению работы систем, управляемых ИИ, таких как автомобили.
Системы искусственного интеллекта также отличаются от биологических систем тем, что они спроектированы и структурированы для достижения поставленных целей.Компьютерные программисты и инженеры, такие как Лейбниц, склонны рассматривать роль систем ИИ как прикладных калькуляторов, управляющих серией механических операций для достижения желаемых результатов (целей). Постановка целей менее характерна для сновидений, хотя это важная часть процесса, называемого инкубацией сновидений. Инкубация — это традиционное и освященное веками использование сновидений, при котором человек засыпает, учитывая проблему, с которой сталкивается во время бодрствования. 9 Некоторые люди связывают этот процесс с попыткой достичь контроля над процессом принятия решений (осознанности) в состоянии сна.Художники, режиссеры, музыканты, ученые и особенно писатели рассказывают о таких целенаправленных мечтах, которые приносят полезные и часто творческие результаты. 10 Но большинство снов, даже самые полезные с творческой точки зрения, не включают в себя поставленные цели и не отражают целенаправленное поведение.
Машины ведут учет своего опыта, включая историю выполнения низкоуровневых инструкций и коррелированных входов / выходов на самых высоких уровнях. Эта история может или не может быть сохранена.При использовании в системах с мягкой нечеткой логикой или в обученном ИИ эта история может обеспечить основу для получения новых и потенциально творческих результатов даже на основе анализа данных с жесткими ограничениями.
Опыт и обучение машины ИИ определяют реакцию машины ИИ. Системы искусственного интеллекта на основе нейронных сетей могут только окончательно реагировать на стимулы, которым они обучены. Комбинации реальных числовых стимулов, шума и частичного или неполного обучения делают нарушение работы ИИ-машины более вероятным по мере увеличения искусственной нейронной плотности.Обработка, разработанная нейронной сетью, может давать значительную часть результатов, которые можно рассматривать как неопределенные или галлюцинаторные. Биологические сновидения часто неопределенны, а иногда и галлюцинаторные, особенно в начале сна, возникающие сразу после засыпания. Биологические сны, особенно кошмары, кажутся реальными, и, рассматриваемые как таковые, их можно рассматривать как галлюцинаторные, предоставляя альтернативную и очевидно реальную версию реальности.Примерно три из восьми результатов, полученных с помощью простой обработки нейронной сети, являются неопределенными или галлюцинаторными. Такие полученные результаты часто рассматриваются как свидетельство неисправности оборудования, гипотетические и неприменимые к реальной ситуации.
Анализ данных, проводимый с использованием систем нечеткой логики, ИИ и нейронных сетей, даже анализ, основанный на установленных и контролируемых целях, с гораздо большей вероятностью приведет к неожиданным результатам, чем система, основанная на параметрической и строго контролируемой логике.Такие результаты часто являются нестандартными, неопределенными и / или галлюцинаторными. Эти результаты, вместо того, чтобы указывать на неисправность машины, указывают на уровень сложности и гибкости системы. Для взаимодействия с интерактивными системами, которые часто работают вне логических ограничений (люди), может быть важно включить и включить такие альтернативные и явно нелогичные результаты. Является ли антропоморфизмом рассмотрение и, возможно, описание таких результатов как машинные сны?
Как работают нейронные сети — простое введение
Криса Вудфорда.Последнее изменение: 30 августа 2021 г.
Что лучше — компьютер или мозг? Спросите большинство людей, хотят ли они такого мозга, как компьютер, и они, вероятно, ухватятся за этот шанс. Но посмотрите, какую работу вели ученые за последние пару десятилетий, и вы обнаружите, что многие из них изо всех сил пытались сделать свои компьютеры более похожими на мозг! Как? С помощью нейронных сетей — компьютерные программы, собранные из сотен, тысяч или миллионов искусственных клеток мозга, которые обучаются и ведут себя очень похоже на человеческий мозг.Что такое нейронные сети? Как они работают? Давайте посмотрим внимательнее!
Фото: У компьютеров и мозга много общего, но по сути они очень разные. Что произойдет, если объединить лучшее из обоих миров — систематическую мощь компьютера и тесно связанные между собой клетки мозга? Вы получаете великолепно полезную нейронную сеть.
Чем мозг отличается от компьютера
Вы часто слышите, как люди сравнивают человеческий мозг и электронный компьютер, и, на первый взгляд, у них есть общие черты.Типичный мозг содержит около 100 миллиардов крохотных клеток, называемых нейронами (никто не знает точно, сколько их, и по оценкам от примерно 50 миллиардов до целых 500 миллиардов) [1]. Каждый нейрон состоит из клеточного тела (центральная масса клетки) с рядом исходящих от него соединений: многочисленные дендриты (входы клетки, несущие информацию к телу клетки) и единственный аксон (вывод клетки — уносит информацию).Нейроны настолько крошечные, что вы можете упаковать около 100 их клеточных тел в один миллиметр. (Также стоит отметить, вкратце мимоходом, что нейроны составляют только 10-50 процентов всех клеток в головном мозге; остальные — глиальные клетки, также называемые нейроглией, которые поддерживают и защищают нейроны и подпитывают их энергией, позволяющей им работать и расти.) [1] Внутри компьютера клетка мозга эквивалентна клетке. наноскопически крошечное коммутационное устройство, называемое транзистором. Новейшие передовые микропроцессоры (однокристальные компьютеры) содержат более 30 миллиардов транзисторов; даже базовый микропроцессор Pentium примерно 20 лет назад было около 50 миллионов транзисторов, все упакованные на интегральную схему площадью всего 25 мм (меньше почтовой марки)! [2]
Изображение: Нейрон: основная структура клетки мозга, показывающая центральное тело клетки, дендриты (ведущие в тело клетки) и аксон (ведущие от него).
Здесь начинается и заканчивается сравнение компьютеров и мозга, потому что это совершенно разные вещи. Дело не только в том, что компьютеры — это холодные металлические коробки, набитые двоичными числами, а мозг теплый, живой, вещи наполнены мыслями, чувствами и воспоминаниями. Настоящая разница в том, что компьютеры и мозг «думают» совершенно по-разному. В Транзисторы в компьютере соединены в относительно простые последовательные цепи (каждый из них связан, может быть, с двумя или тремя другими в базовых схемах, известных как логические вентили), тогда как нейроны в мозге плотно взаимосвязаны сложными параллельными способами (каждый из них подключен к примерно 10 000 своих соседей).[3]
Это существенное структурное различие между компьютерами (возможно, с несколькими сотнями миллионов транзисторов, подключенных относительно простым способом) и мозгом (возможно, в 10–100 раз больше клеток мозга, соединенных более богатыми и сложными способами) — вот что заставляет их «думать» так по-разному. . Компьютеры идеально подходят для хранения огромного количества бессмысленной (для них) информации и преобразования ее любым количеством способов в соответствии с точными инструкциями (программами), которые мы им заранее вводим.Мозг, с другой стороны, учится медленно, более окольными методами, часто на то, чтобы полностью понять что-то действительно сложное, уходят месяцы или годы. Но, в отличие от компьютеров, они могут спонтанно объединять информацию поразительными новыми способами — вот откуда исходит человеческое творчество Бетховена или Шекспира — распознавая оригинальные шаблоны, налаживая связи и видя то, чему они научились, в совершенно ином свете. .
Разве не было бы замечательно, если бы компьютеры были больше похожи на мозг? Вот тут и пригодятся нейронные сети!
Фото: Электронный мозг? Не совсем.Компьютерные микросхемы состоят из тысяч, миллионов, а иногда и миллиардов крошечных электронных переключателей, называемых транзисторами. Звучит много, но их по-прежнему намного меньше, чем клеток в человеческом мозгу.
Что такое нейронная сеть?
Основная идея нейронной сети состоит в том, чтобы моделировать (копировать упрощенным, но достаточно точным образом) множество плотно связанных между собой клеток мозга внутри компьютера, чтобы вы могли научить его, распознавать закономерности и принимать решения по-человечески.Самое удивительное в нейронной сети то, что вам не нужно программировать ее для явного обучения: она обучается сама по себе, как мозг!
Но это не мозг. Важно отметить, что нейронные сети (как правило) представляют собой моделирование программного обеспечения: они создаются путем программирования очень обычных компьютеров, работающих очень традиционным образом со своими обычными транзисторами и последовательно подключенными логическими вентилями, чтобы вести себя так, как будто они построены из миллиардов тесно связанных между собой клеток мозга, работающих параллельно.Никто еще не пытался построить компьютер, соединив транзисторы в плотно параллельную структуру, точно такую же, как человеческий мозг. Другими словами, нейронная сеть отличается от человеческого мозга точно так же, как компьютерная модель погоды отличается от настоящих облаков, снежинок или солнечного света. Компьютерное моделирование — это просто набор алгебраических переменных и математических уравнений, связывающих их вместе (другими словами, числа, хранящиеся в ящиках, значения которых постоянно меняются). Они ничего не значат для компьютеров, внутри которых работают, — только для людей, которые их программируют.
Реальные и искусственные нейронные сети
Прежде чем мы продолжим, стоит также отметить некоторый жаргон. Строго говоря, нейронные сети, созданные таким образом, называются искусственными нейронными сетями (или ИНС), чтобы отличать их от настоящих нейронных сетей (совокупностей взаимосвязанных клеток мозга), которые мы находим внутри нашего мозга. Вы также можете увидеть нейронные сети, называемые такими именами, как соединительные машины (это поле также называется коннекционизмом), параллельные распределенные процессоры (PDP), мыслящие машины и т. Д., Но в этой статье мы будем использовать термин «нейронные сети». сеть «повсюду» и всегда используют его для обозначения «искусственная нейронная сеть».«
Из чего состоит нейронная сеть?
Типичная нейронная сеть содержит от нескольких десятков до сотен, тысяч или даже миллионов искусственных нейронов, называемых блоки расположены в ряд слоев, каждый из которых соединяется со слоями с каждой стороны. Некоторые из них, известные как блоки ввода , предназначены для приема различных форм информации из внешнего мира, которую сеть будет пытаться узнать, распознать или обработать иным образом.Другие устройства находятся на противоположной стороне сети и сигнализируют, как она реагирует на полученную информацию; они известны как блоки вывода . Между блоками ввода и выводами находится один или несколько уровней из скрытых блоков , которые вместе составляют большую часть искусственного мозга. Большинство нейронных сетей — это полностью подключенных , что означает, что каждый скрытый блок и каждый выходной блок подключены к каждому блоку в слоях с каждой стороны. Связи между одним модулем и другим представлены числом, называемым весом , которое может быть либо положительным (если один модуль возбуждает другой), либо отрицательным (если один модуль подавляет или запрещает другой).Чем выше вес, тем большее влияние оказывает одно устройство на другое. (Это соответствует тому, как реальные клетки мозга запускают друг друга через крошечные промежутки, называемые синапсами.)
Фотография: Полностью подключенная нейронная сеть состоит из входных блоков (красный), скрытых блоков (синий) и выходных блоков (желтый), причем все блоки подключены ко всем блокам в слоях с каждой стороны. Входы подаются слева, активируйте скрытые блоки посередине и сделайте выходы поданными справа.Сила (вес) связи между любыми двумя устройствами постепенно регулируется по мере обучения сети.
Хотя простая нейронная сеть для решения простых задач может состоять всего из трех слоев, как показано здесь, она также может состоять из множества различных уровней между входом и выходом. Такая более богатая структура называется глубокой нейронной сетью (DNN) и обычно используется для решения гораздо более сложных проблем. Теоретически DNN может сопоставлять любой тип ввода с любым типом вывода, но недостатком является то, что он требует значительно большего обучения: ему нужно «видеть» миллионы или миллиарды примеров по сравнению с, возможно, сотнями или тысячами, как в более простой сети. может понадобиться.Глубокий или «неглубокий», как бы он ни был структурирован, и как бы мы ни изображали его на странице, стоит еще раз напомнить себе, что нейронная сеть — это , а не , на самом деле мозг или что-то подобное. В конце концов, это куча умных математических расчетов … куча уравнений … алгоритм, если хотите. [4]
Как нейронная сеть учится?
Информация проходит через нейронную сеть двумя способами. Когда он обучается (обучается) или работает нормально (после обучения), образцы информации передаются в сеть через входные блоки, которые запускают слои скрытых блоков, а они, в свою очередь, поступают в выходные блоки.Эта общая схема называется сетью прямой связи . Не все подразделения «стреляют» все время. Каждое устройство получает входные данные от устройств слева от него, и эти входные данные умножаются на веса соединений, по которым они перемещаются. Каждый блок суммирует все входные данные, которые он получает таким образом, и (в простейшем типе сети), если сумма превышает определенное пороговое значение , блок «срабатывает» и запускает блоки, к которым он подключен (те, что на его Правильно).
Фото: Боулинг: Вы учитесь делать такие умелые вещи с помощью нейронной сети внутри вашего мозга.Каждый раз, когда вы неправильно бросаете мяч, вы узнаете, какие поправки нужно внести в следующий раз. Фото Кеннета Р. Хендрикса / ВМС США Опубликован в Flickr.
Чтобы нейронная сеть могла обучаться, должен быть задействован элемент обратной связи — точно так же, как дети учатся, когда им говорят, что они делают правильно или неправильно. Фактически, мы все постоянно пользуемся обратной связью. Вспомните, когда вы впервые научились играть в боулинг с десятью кеглями. Когда вы поднимали тяжелый мяч и катили его по аллее, ваш мозг наблюдал, как быстро мяч движется и по какой линии он следует, и отмечал, как близко вы подошли к тому, чтобы сбить кегли.В следующий раз, когда настала ваша очередь, вы вспомнили, что делали неправильно раньше, изменили свои движения соответствующим образом и, надеюсь, бросили мяч немного лучше. Итак, вы использовали обратную связь, чтобы сравнить желаемый результат с тем, что произошло на самом деле, выяснили разницу между ними и использовали это, чтобы изменить то, что вы сделали в следующий раз («Мне нужно бросить это посильнее», «Мне нужно бросить немного больше. слева: «Мне нужно отпустить позже» и т. д.). Чем больше разница между предполагаемым и фактическим исходом, тем радикальнее вы бы изменили свои ходы.
Нейронные сети изучают вещи точно так же, как правило, с помощью процесса обратной связи, который называется обратное распространение (иногда сокращенно «обратное распространение»). Это включает в себя сравнение выходных данных, которые производит сеть, с выходными данными, которые она должна была производить, и использование разницы между ними для изменения весов соединений между устройствами в сети, работая от выходных блоков через скрытые блоки к входным блокам. Другими словами, движение назад. Со временем обратное распространение приводит к тому, что сеть учится, уменьшая разницу между фактическим и предполагаемым выходом до точки, в которой они точно совпадают, поэтому сеть выясняет вещи именно так, как должна.
Фотография: Нейронная сеть может обучаться путем обратного распространения ошибки, который представляет собой своего рода процесс обратной связи, который передает корректирующие значения в обратном направлении по сети.
Как это работает на практике?
После того, как сеть обучена с помощью достаточного количества обучающих примеров, она достигает точки, когда вы можете представить ей совершенно новый набор входных данных, которого раньше не видели, и посмотреть, как она отреагирует. Например, предположим, что вы обучаете сеть, показывая ей множество изображений стульев и столов, представленных каким-либо подходящим образом, и сообщая ей, является ли каждый из них стулом или столом.Показав ему, скажем, 25 разных стульев и 25 разных столов, вы скармливаете ему изображение какого-то нового дизайна, которого раньше не встречали, — скажем, шезлонга, — и смотрите, что получится. В зависимости от того, как вы его обучили, он попытается классифицировать новый пример как стул или стол, обобщая на основе своего прошлого опыта — точно так же, как человек. Привет, ты научил компьютер распознавать мебель!
Это не значит, что нейронная сеть может просто «смотреть» на предметы мебели и мгновенно реагировать на них осмысленным образом; это не поведение человека.Рассмотрим только что приведенный пример: сеть на самом деле не смотрит на предметы мебели. Входы в сеть — это, по сути, двоичные числа: каждый входной блок либо включен, либо выключен. Итак, если у вас есть пять модулей ввода, вы можете ввести информацию о пяти различных характеристиках разных стульев, используя двоичные (да / нет) ответы. Вопросы могут быть такие: 1) Есть ли у него спинка? 2) Есть ли у него верх? 3) Есть ли мягкая обивка? 4) Сможете ли вы с комфортом сидеть на нем долгое время? 5) Можете ли вы положить на него много чего? Типичный стул тогда будет представлен как Да, Нет, Да, Да, Нет или 10110 в двоичном формате, в то время как типичная таблица может быть представлена как Нет, Да, Нет, Нет, Да или 01001.Итак, на этапе обучения сеть просто просматривает множество чисел, таких как 10110 и 01001, и узнает, что некоторые из них означают стул (что может быть результатом 1), а другие означают таблицу (выход 0).
Для чего используются нейронные сети?
Фото: Последние два десятилетия НАСА экспериментировало с самообучающейся нейронной сетью под названием Интеллектуальная система управления полетом (IFCS), которая может помочь пилотам приземлить самолеты после серьезных сбоев или повреждений в бою.Прототип испытывался на этом модифицированном самолете NF-15B (родственник McDonnell Douglas F-15). Фото Джима Росса любезно предоставлено НАСА.
На основе этого примера вы, вероятно, увидите множество различных приложений для нейронных сетей, которые включают распознавание шаблонов и принятие простых решений по ним. В самолетах вы можете использовать нейронную сеть в качестве базового автопилота с модулями ввода, считывающими сигналы от различных приборов кабины, и модулями вывода, которые соответствующим образом изменяют органы управления самолета, чтобы безопасно удерживать его на курсе.Внутри фабрики вы можете использовать нейронную сеть для контроля качества. Допустим, вы производите средство для стирки одежды с помощью гигантского запутанного химического процесса. Вы можете измерить конечное моющее средство различными способами (его цвет, кислотность, толщину и т. Д.), Ввести эти измерения в свою нейронную сеть в качестве входных данных, а затем позволить сети решить, принять или отклонить партию.
Также существует множество приложений для нейронных сетей в сфере безопасности. Предположим, у вас есть банк, в котором каждую минуту через вашу компьютерную систему проходят тысячи транзакций по кредитным картам.Вам нужен быстрый автоматизированный способ выявления любых транзакций, которые могут быть мошенническими, и для этого идеально подходит нейронная сеть. Ваши данные будут примерно такими: 1) Присутствует ли на самом деле владелец карты? 2) Был ли использован действующий ПИН-код? 3) Было ли произведено пять или более транзакций по этой карте за последние 10 минут? 4) Используется ли карта в другой стране, в которой она зарегистрирована? -и так далее. Имея достаточное количество подсказок, нейронная сеть может помечать любые транзакции, которые выглядят подозрительно, что позволяет оператору-человеку более внимательно их исследовать.Точно так же банк мог бы использовать нейронную сеть, чтобы помочь ему решить, давать ли ссуды людям на основе их прошлой кредитной истории, текущих доходов и трудовой книжки.
Фото: Распознавание рукописного ввода на сенсорном экране, планшетный компьютер — одно из многих приложений, идеально подходящих для нейронной сети. Каждый вводимый вами символ (буква, цифра или символ) распознается на основе содержащихся в нем ключевых характеристик (вертикальные линии, горизонтальные линии, наклонные линии, кривые и т. Д.) И порядка, в котором вы их рисуете на экране. .Нейронные сети со временем распознают все лучше и лучше.
Многие вещи, которые мы делаем каждый день, включают распознавание шаблонов и их использование для принятия решений, поэтому нейронные сети могут помочь нам множеством разных способов. Они могут помочь нам прогнозировать фондовый рынок или погоду, управлять системами радиолокационного сканирования, которые автоматически идентифицируют вражеские самолеты или корабли, и даже помогать врачам диагностировать сложные заболевания на основе их симптомов. Прямо в эту минуту внутри вашего компьютера или мобильного телефона могут работать нейронные сети.Если вы используете приложения для мобильных телефонов, которые распознают ваш почерк на сенсорном экране, они могут использовать простую нейронную сеть, чтобы выяснить, какие символы вы пишете, ища отличительные особенности в отметках, которые вы делаете пальцами (и в каком порядке вы их делаете). Некоторые виды программного обеспечения для распознавания голоса также используют нейронные сети. То же самое и с некоторыми почтовыми программами, которые автоматически различают подлинные электронные письма и спам. Нейронные сети даже доказали свою эффективность при переводе текста с одного языка на другой.
Автоматический перевод Google, например, за последние несколько лет все шире использует эту технологию для преобразования слов на одном языке (вход сети) в эквивалентные слова на другом языке (выход сети). В 2016 году Google объявил, что использует то, что называется нейронным машинным переводом (NMT), для мгновенного преобразования целых предложений с Снижение ошибок на 55–85%. Это всего лишь один пример того, как Google разворачивает технологию нейронных сетей: Google Brain. так называется масштабное исследование, которое применяет нейронные методы ко всему спектру продуктов, включая его поисковая система.Он также использует глубокие нейронные сети для поддержки рекомендаций, которые вы видите на YouTube, с моделями, которые «узнают приблизительно один миллиард параметров и обучены на сотнях миллиардов примеров »[5]
В общем, нейронные сети сделали компьютерные системы более полезными, сделав их более человечными. Так что в следующий раз, когда вам захочется, чтобы ваш мозг был таким же надежным, как компьютер, подумайте еще раз — и будьте благодарны, что в вашей голове уже установлена такая превосходная нейронная сеть!
Нейронные сети стали проще — TechCrunch
Офир Танц — генеральный директор GumGum, компании, занимающейся искусственным интеллектом, с особым опытом в области компьютерного зрения.GumGum применяет свои возможности в самых разных отраслях, от рекламы до профессионального спорта по всему миру. Офир имеет степень бакалавра наук. и M.S. из Университета Карнеги-Меллона и в настоящее время живет в Лос-Анджелесе. Другие сообщения этого автора- Почему будущее глубокого обучения зависит от поиска надежных данных
- Простота нейронных сетей
Кемброн Картер Автор
Камброн Картер возглавляет команду разработчиков изображений в GumGum, где он разрабатывает решения для компьютерного зрения и машинного обучения для самых разных приложений.Камброн владеет B.S. степени в области физики и электротехники и магистра инженерных наук. по электротехнике в Университете Луисвилля. Другие сообщения этого автора- Почему будущее глубокого обучения зависит от поиска надежных данных
- Простота нейронных сетей
Если вы копались в статьях об искусственном интеллекте, вы почти наверняка встречали термин «нейронная сеть». Искусственные нейронные сети, смоделированные по образцу человеческого мозга, позволяют компьютерам учиться на основе полученных данных.
Эффективность этого мощного направления машинного обучения больше, чем что-либо еще, послужила началом новой эры искусственного интеллекта, положившей конец долгой «зиме искусственного интеллекта». Проще говоря, нейронная сеть вполне может быть одной из самых принципиально разрушительных технологий, существующих сегодня.
Это руководство по нейронным сетям призвано дать вам понимание глубокого обучения на разговорном уровне. С этой целью мы не будем углубляться в математику и вместо этого будем максимально полагаться на аналогии и анимацию.
Мышление грубой силой
Одна из первых школ искусственного интеллекта учила, что если вы загрузите как можно больше информации в мощный компьютер и дадите ему как можно больше направлений для понимания этих данных, он должен уметь «думать». Это была идея, лежащая в основе шахматных компьютеров, таких как знаменитый Deep Blue от IBM: исчерпывающе запрограммировав в компьютер все возможные шахматные ходы, а также известные стратегии, а затем придав ему достаточную мощность, программисты IBM создали машину, которая теоретически могла бы вычислить каждый возможный ход и исход в будущем и выберите последовательность последующих ходов, чтобы переиграть своего противника.Это действительно работает, как шахматные мастера узнали в 1997 году. *
При такого рода вычислениях машина полагается на фиксированные правила, которые были тщательно заранее запрограммированы инженерами — если это произойдет, то это произойдет; если это произойдет, сделайте это — и поэтому это совсем не человеческое гибкое обучение в том виде, в каком мы его знаем. Конечно, это мощный суперкомпьютер, но не «мышление» как таковое.
Учебные машины для обучения
За последнее десятилетие ученые возродили старую концепцию, которая опирается не на массивный банк энциклопедической памяти, а на простой и систематический способ анализа входных данных, который в общих чертах смоделирован по образцу человеческого мышления.Эта технология, известная как глубокое обучение или нейронные сети, существует с 1940-х годов, но из-за сегодняшнего экспоненциального распространения данных — изображений, видео, голосового поиска, привычек просмотра и многого другого — вместе с мощными и доступными процессорами, наконец, стала в состоянии начать раскрывать свой истинный потенциал.
Машины — они такие же, как мы!
Искусственная (в отличие от человеческой) нейронная сеть (ИНС) — это алгоритмическая конструкция, которая позволяет машинам узнавать все, от голосовых команд и настройки списков воспроизведения до композиции музыки и распознавания изображений.Типичная ИНС состоит из тысяч взаимосвязанных искусственных нейронов, которые последовательно уложены в ряды, известные как слои, образуя миллионы соединений. Во многих случаях слои связаны только со слоем нейронов до и после них через входы и выходы. (Это сильно отличается от нейронов в человеческом мозгу, которые связаны между собой во всех отношениях.)
Источник: GumGum
Эта многоуровневая ИНС — один из основных способов развития машинного обучения сегодня, и передача ему огромного количества помеченных данных позволяет ему научиться интерпретировать эти данные как (а иногда и лучше) человеческий.
Подобно тому, как родители учат своих детей распознавать яблоки и апельсины в реальной жизни, для компьютеров практика тоже помогает.
Возьмем, к примеру, распознавание изображений, которое основывается на особом типе нейронной сети, известной как сверточная нейронная сеть (CNN) — так называемой, потому что она использует математический процесс, известный как свертка, чтобы иметь возможность анализировать изображения не буквальными способами. , например, определение частично скрытого объекта или объекта, который можно увидеть только под определенным углом.(Существуют и другие типы нейронных сетей, в том числе рекуррентные нейронные сети и нейронные сети с прямой связью, но они менее полезны для идентификации таких вещей, как изображения, что является примером, который мы собираемся использовать ниже.)
Все на борт обучения сети
Так как же нейронные сети учатся? Давайте посмотрим на очень простую, но эффективную процедуру, называемую обучением с учителем. Здесь мы передаем нейронной сети огромные объемы обучающих данных, помеченных людьми, чтобы нейронная сеть могла фактически проверять себя во время обучения.
Допустим, эти маркированные данные состоят из изображений яблок и апельсинов соответственно. Картинки — это данные; «Яблоко» и «апельсин» — это надписи, в зависимости от рисунка. По мере загрузки изображений сеть разбивает их на самые основные компоненты, то есть края, текстуры и формы. По мере того, как изображение распространяется по сети, эти базовые компоненты объединяются, чтобы сформировать более абстрактные концепции, то есть кривые и разные цвета, которые при дальнейшем объединении начинают выглядеть как стебель, целый апельсин или как зеленые, так и красные яблоки.
В конце этого процесса сеть пытается сделать прогноз относительно того, что изображено на картинке. Сначала эти прогнозы будут казаться случайными, поскольку реального обучения еще не произошло. Если входное изображение — яблоко, но прогнозируется «апельсин», внутренние слои сети необходимо отрегулировать.
Корректировки выполняются с помощью процесса, называемого обратным распространением, чтобы увеличить вероятность предсказания «яблока» для того же изображения в следующий раз.Это происходит снова и снова, пока прогнозы не станут более или менее точными и, похоже, не улучшатся. Подобно тому, как родители учат своих детей распознавать яблоки и апельсины в реальной жизни, для компьютеров практика тоже помогает. Если в своей голове вы просто подумали: «Эй, это похоже на обучение», то, возможно, вы сделаете карьеру в области искусственного интеллекта.
Так много слоев…
Как правило, сверточная нейронная сеть имеет четыре основных слоя нейронов помимо входного и выходного слоев:
- Свертка
- Активация
- Объединение
- Полностью подключен
Свертка
В начальном сверточном слое или слоях тысячи нейронов действуют как первый набор фильтров, очищая каждую часть и пиксель изображения в поисках закономерностей.По мере того, как обрабатывается все больше и больше изображений, каждый нейрон постепенно учится фильтровать определенные функции, что повышает точность.
В случае яблок один фильтр может быть сфокусирован на поиске красного цвета, в то время как другой может искать закругленные края, а третий может определять тонкие, похожие на палочки стебли. Если вам когда-либо приходилось убирать захламленный подвал, чтобы подготовиться к гаражной распродаже или большому переезду — или вы работали с профессиональным организатором, — тогда вы знаете, что это такое — все перебрать и разложить по стопкам разной тематики (книги , игрушки, электроника, предметы искусства, одежда).Это то же самое, что сверточный слой делает с изображением, разбивая его на различные элементы.
Одно из преимуществ нейронных сетей состоит в том, что они способны к нелинейному обучению.
Что особенно важно — и одна из главных претензий нейронной сети к славе — это то, что, в отличие от более ранних методов искусственного интеллекта (Deep Blue и ему подобных), эти фильтры не создаются вручную; они учатся и совершенствуются, просто глядя на данные.
Сверточный слой, по сути, создает карты — разные, разбитые версии изображения, каждая из которых посвящена разному отфильтрованному объекту, — которые указывают, где его нейроны видят экземпляр (хотя и частичный) красного цвета, стебли, кривые и различные другие элементы, в данном случае, яблока.Но поскольку слой свертки довольно либерален в плане идентификации функций, ему нужен дополнительный набор глаз, чтобы убедиться, что ничего ценного не упущено при перемещении изображения по сети.
Активация
Одним из преимуществ нейронных сетей является то, что они способны к нелинейному обучению, что, говоря без математических выражений, означает, что они могут обнаруживать на изображениях не столь очевидные особенности — изображения яблок на деревьях, некоторые из них. под прямыми солнечными лучами и другими предметами в тени или сложенным в миску на кухонной стойке.Все это благодаря слою активации, который служит более или менее для выделения ценных вещей — как простых, так и труднодоступных разновидностей.
В мире нашего организатора гаражных распродаж или консультанта по беспорядку представьте себе, что из каждой из этих отдельных груд вещей мы выбрали несколько предметов — горстку редких книг, несколько классических футболок из студенческих дней до носить иронично — что мы, возможно, захотим сохранить. Мы помещаем эти «возможно» элементы поверх стопки соответствующих категорий для другого рассмотрения позже.
Объединение
Все эти «свертки» по всему изображению генерируют много информации, и это может быстро превратиться в вычислительный кошмар. Войдите в объединяющий слой, который сжимает все в более общую и удобоваримую форму. Есть много способов сделать это, но один из самых популярных — это «максимальное объединение», при котором каждая карта характеристик преобразуется в версию Reader’s Digest , так что только лучшие примеры покраснения, стеснения или пышность характерны.
В примере с генеральной уборкой гаража, если бы мы использовали принципы знаменитого японского консультанта по вопросам беспорядка Мари Кондо, наша вьючная крыса должна была бы выбирать только те вещи, которые «вызывают радость» из меньшего ассортимента фаворитов в каждой стопке категорий, и продавать или бросать все остальное. Итак, теперь у нас все еще есть все наши стопки, сгруппированные по типу элементов, но состоящие только из элементов, которые мы действительно хотим сохранить; все остальное продается. (И на этом, кстати, заканчивается наша аналогия с устранением беспорядка, чтобы помочь описать фильтрацию и уменьшение размера, происходящие внутри нейронной сети.)
На этом этапе разработчик нейронной сети может складывать последующие многоуровневые конфигурации такого рода — свертка, активация, объединение — и продолжать фильтровать изображения, чтобы получить информацию более высокого уровня. В случае идентификации яблока на изображениях изображения фильтруются снова и снова, при этом на начальных слоях видны едва различимые части края, красная точка или только кончик стебля, в то время как последующие, более отфильтрованные слои будут показать целые яблоки. В любом случае, когда пришло время начать получать результаты, в игру вступает полностью связанный слой.
Источник: GumGum
Полностью подключен
Теперь пора начинать получать ответы. В полностью связанном слое каждая сокращенная или «объединенная» карта характеристик «полностью связана» с выходными узлами (нейронами), которые представляют элементы, которые нейронная сеть учится идентифицировать. Если задача сети — научиться определять кошек, собак, морских свинок и песчанок, то у нее будет четыре выходных узла. В случае с нейронной сетью, которую мы описывали, у нее будет всего два выходных узла: один для «яблок» и один для «апельсинов».”
Если изображение яблока, которое было передано через сеть, уже прошло некоторое обучение и улучшается со своими прогнозами, то вполне вероятно, что хороший фрагмент карт функций содержит качественные экземпляры функций яблока. Именно здесь эти конечные выходные узлы начинают выполнять свою судьбу с своего рода обратными выборами.
Внесены тонкости и корректировки, чтобы помочь каждому нейрону лучше идентифицировать данные на каждом уровне.
Задача (которую они узнали «на работе») как яблочного, так и оранжевого узлов, по сути, состоит в том, чтобы «голосовать» за карты функций, которые содержат их соответствующие плоды.Таким образом, чем больше узел «яблоко» думает, что конкретная карта функций содержит функции «яблоко», тем больше голосов он отправляет этой карте функций. Оба узла должны голосовать за каждую отдельную карту функций, независимо от того, что она содержит. Таким образом, в этом случае «оранжевый» узел не будет отправлять много голосов ни за одну из карт функций, потому что на самом деле они не содержат никаких «оранжевых» функций. В конце концов, узел, который отправил наибольшее количество голосов — в этом примере узел «яблоко» — можно считать «ответом» сети, хотя это не так просто.
Поскольку одна и та же сеть ищет две разные вещи — яблоки и апельсины, конечный результат сети выражается в процентах. В этом случае мы предполагаем, что сеть уже немного продвинулась в своем обучении, поэтому прогнозы здесь могут быть, скажем, на 75 процентов «яблочными» и на 25 процентов «оранжевыми». Или, если это было раньше на тренировке, это могло бы быть более неточно и определить, что это на 20 процентов «яблоко» и на 80 процентов «апельсин». Ой.
Источник: GumGum
Если сначала у вас не получится, попробуйте, попробуйте, попробуйте еще раз
Итак, на ранних стадиях нейронная сеть выдает кучу неправильных ответов в виде процентов.Прогноз на 20 процентов «яблоко» и 80 процентов «апельсин» явно неверен, но поскольку это контролируемое обучение с помеченными данными обучения, сеть может выяснить, где и как произошла эта ошибка, с помощью системы сдержек и противовесов, известной как обратное распространение.
Итак, это бессчетное объяснение, поэтому достаточно сказать, что обратное распространение посылает обратное распространение узлам предыдущего уровня о том, насколько далеко были ответы. Затем этот слой отправляет обратную связь на предыдущий уровень и так далее, как в телефонной игре, пока он не вернется в состояние свертки.Внесены тонкости и корректировки, чтобы помочь каждому нейрону лучше идентифицировать данные на каждом уровне, когда последующие изображения проходят через сеть.
Этот процесс повторяется снова и снова, пока нейронная сеть не будет определять яблоки и апельсины на изображениях с нарастающей точностью, что в конечном итоге приведет к стопроцентно правильным предсказаниям — хотя многие инженеры считают 85 процентов приемлемыми.
 2
2 Метод обратного распространения ошибки позволяет вычислить и объяснить ошибки, связанные с каждым нейроном, что позволяет скорректировать и адаптировать параметры модели соответствующим образом.
Метод обратного распространения ошибки позволяет вычислить и объяснить ошибки, связанные с каждым нейроном, что позволяет скорректировать и адаптировать параметры модели соответствующим образом.