Процессоры AMD Архитектура и эволюция
Министерство образования и науки Российской Федерации
УФИМСКИЙ ГОСУДАРСТВЕННЫЙ АВИАЦИОННЫЙ ТЕХНИЧЕСКИЙ
УНИВЕРСИТЕТ
Кафедра АТС
Реферат
по дисциплине:
«Вычислительные машины, системы и сети»
на тему:
«Процессоры AMD :Архитектура и эволюция»
Выполнил:
гр. АУ-328
Проверила: Чепайкина Е.А.
УФА 2006
Содержание
Введение…………………………………………………………………………….3
AMD K5….………………………………………………………………………….4
AMDK6….………………………………..…………………………………………6
AMDK6-2.……………………………………….………………………………… 7
Технология 3DNow!…………………………………..………………………………….. 8
AMD K6-III ………………………………………………………………………… 9
AMDK7 …………………………………………………………………………… 10
AMDAthlon..……………………………………………………………………… 12
AMDAthlonXP.…………………………………………………………………… 13
64-битные процессоры…………………………………………………………… 15
AMDAthlon64..…………………………………………………………………….16
Заключение……………………………………………………………………….. 19
Список литературы ………………………………………………………………. 20
Введение
Компания AMD была основана в 1969 году и ее штаб-квартира находится г. Саннивейл (шт. Калифорния). AMD разрабатывает и выпускает инновационные микропроцессоры, устройства флэш-памяти и процессоры с пониженным энергопотреблением для вычислительных устройств, коммуникационного оборудования и бытовой электроники.
Однако «технологии ради технологий» — это не тот путь, который выбрала для себя компания AMD. Вся история проникнута стремлением разрабатывать технологические новшества, которые действительно нужны клиентам, компания AMD руководствуется реальными потребностями людей, а не желанием обеспечить собственное превосходство. Основатель компании AMD Джерри Сандерс всегда говорил, что «на любом этапе развития компании в первую очередь должны учитываться интересы клиентов». Сегодняшний руководитель компании Гектор Руиз, продолжая следовать этой традиции, утверждает: «Инновации, ориентированные на потребности клиентов, — это неоспоримое преимущество компании AMD. В этом смысл нашей деятельности и в этом наш путь к успеху».
История компании AMD определяется также непоколебимой верой в ценности честного соревнования. Отсутствие свободного и открытого соревнования замедляет разработку инноваций. Вследствие чего страдает клиент, который ограничен в выборе, вынужден платить больше и получать меньше возможностей для роста. На каждом этапе своей деятельности компания AMD способствовала созданию условий для открытого и честного соревнования для всех желающих, чтобы наша отрасль разрабатывала такие технологии, которые работают на благо людей.
AMD K5
Процессор фирмы AMD Krypton-5 (K5). Эти процессоры построены по архитектуре x86-to-RISC86, принципиально отличной от архитектуры примененной в процессорах Intel Pentium, но они устанавливаются в тот же разъем Socket-7 на материнских платах и полностью совместимы с процессорами Pentium.Процессор AMD K5 содержит 16 Кб кэш памяти для инструкций и 8 Кб для данных, напряжение питания процессора 3,3 В (STD). Использование другой архитектуры позволило при равных тактовых частотах на процессорах AMD K5 получить большую производительность, чем на процессорах Intel Pentium. Процессоры AMD K5-PR75, AMD K5-PR90 и AMD K5-PR100 работают на тактовых частотах соответствующих их P-рейтингам. В процессоры AMD K5-PR120, PR-133, PR-150 и PR-166 были внесены значительные конструктивные изменения по сравнению с предыдущими моделями и их производительность значительно повысилась. Они работают на частотах 90, 100, 120 и 133 МГц соответственно.
Использование новой архитектуры в процессорах K5 привело к сбоям в работе некоторых программ, написанных некорректно. Чаще всего это проявляется в том, что программа во время работы выдает ошибку Divide overflow (переполнение деления или деление на 0). Происходит это из-за того, что процессоры AMD K5 оказались «слишком умными». Дело в том, что некоторые программы используют «пустой цикл» — небольшой многократно повторяющийся участок программы, на котором ничего не происходит (например, по времени исполнения «пустого цикла», можно определить скорость работы процессора). «Умный» AMD K5 видит, что в этом цикле ничего не происходит и не выполняет его. Это приводит к тому, что программа, замеряющая время работы пустого цикла на процессоре K5, получает время равное нулю, и при попытке деления константы на полученное время возникает ошибка. Таких программ остается все меньше и меньше, и обычно эти ошибки проявляются только при работе под DOS.
Для процессора K5 существует стандартная программа, которая отключает предсказание переходов (снижая производительность процессора, но обеспечивая корректную работу без сбоев) и обеспечивает скорость выполнения циклов на уровне Pentium. Аналогичного результата можно добиться путем отключения кэша, что, правда, еще сильнее снизит производительность, сводя на нет все выгоды покупки более быстрого процессора. Отметим, что в процессор AMD K5 добавлены несколько новых по сравнению с Pentium инструкций. Эти инструкции могут использоваться отладчиками для более эффективной работы.
Процессоры AMD отличаются более высокой производительностью при выполнении целочисленных операций (к ним относятся большинство бизнес-приложений и игр) и более низкой скоростью работы математического сопроцессора (используемого AUTOCAD, многими научными программами и, как это не печально, популярной игрой Quake). AMD всегда славилась своей жесткой ценовой политикой — цены на процессоры у этой фирмы гораздо ниже чем у Intel, что зачастую определяет выбор покупателя в сторону AMD. Процессоры AMD K5 являются недорогим решением, если вам нужен Pentium совместимый компьютер. Но обратной стороной медали является то, что может понадобиться дополнительное время на наладку системы и исправление программ с ошибками.
AMD K6
Процессор, построенный по x86-to-RISC86 технологии, может выполнять до 6 инструкций RISC86 одновременно. Он устанавливается в разъем Socket 7 и может быть использован в платах, предназначенных для процессоров Pentium. В отличие от своих собратьев — процессоров Pentium MMX и Cyrix 6x86MX, он программно совместим с процессором Pentium Pro и работает с MMX инструкциями, что делает его сравнимым с процессором Pentium II фирмы Intel. Процессоры K6 содержат 32 Кб кэш памяти для инструкций и 32 Кб для данных, а также таблицу истории переходов на 8192 записи для предсказания переходов.Процессоры AMD K6 за счет невысокой цены и возможностям аналогичным процессору Pentium II могут стать серьезными конкурентами процессорам Pentium MMX и Pentium II фирмы Intel. Эти процессоры хорошо использовать при апгрейде (обновлении) компьютеров на базе Pentium совместимых процессоров, так как при этом не требуется замена материнской платы. В отличие от Pentium Pro, AMD K6 одинаково хорошо работает с 16 битными и с 32 битными задачами, поэтому его одинаково хорошо использовать для серьезных научных задач, для бизнес-приложений, для просмотра Video и для игр под Windows и под DOS.
AMD K6-2
Этот процессор является логическим продолжением линейки K6 и отличается от предшественника только добавленным в ядро нового модуля, обрабатывающего «3D-инструкции» и носящего название 3DNow!. По сути — это еще один сопроцессор по типу MMX, но умеющий выполнять 21 новую инструкцию. Эти новые инструкции призваны, прежде всего, ускорить обработку данных, связанных с трехмерной графикой. Поэтому в набор инструкций 3DNow! включены команды, работающие с вещественночисленными аргументами одинарной точности. Именно поэтому, технология ММХ не пошла в жизнь — ММХ работает с целыми числами, а при расчете трехмерных сцен оперировать приходится с вещественными. Как и ММХ, 3DNow! использует те же регистры, что и сопроцессор, это связано с тем, что операционные системы должны сохранять и сбрасывать все регистры процессора при переключении задач.mirznanii.com
Архитектура процессоров AMD
Опубликовано ноября 10, 2010 в Компоненты ПК, Процессоры
Архитектура процессоров AMD. Перейдем к рассмотрению микроархитектуры процессора AMD Athlon 64, который лежит в основе процессоров 10 поколения (Phenom II). Как ожидается, в середине 2010 года на смену этой отлично обкатанной, но устаревшей архитектуре придет новая, известная в данный момент под кодовым именем Bulldozer
Существует достаточно много версий ядра процессоров AMD Athlon 64, которые различаются технологией производства, размером кэш-памяти и другими незначительными изменениями архитектуры.
Однако в основе всех этих ядер лежит одна и та же микроархитектура. Микроархитектура AMD существенно отличается от рассмотренной микроархитектуры процессоров Intel. Сравнивая конструктивную схему ядра процессора на основе микроархитектуры AMD 64 со схемой легендарного К7 (ядра, ставшего основой процессоров AMD Athlon), можно заметить, что общих черт у них больше, чем различий. Однако, несмотря на внешнее сходство, новое ядро процессора все же претерпело существенные изменения. Итак, обо всем по порядку.
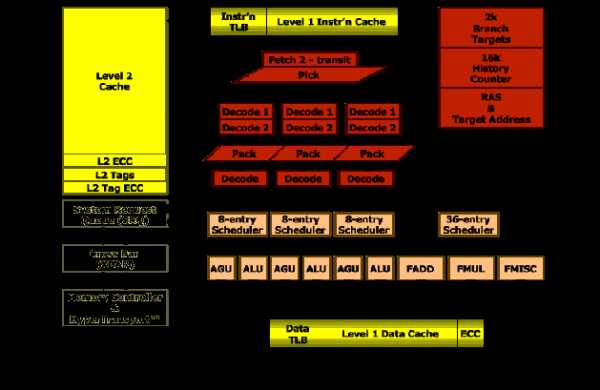
Ядро процессора AMD
Схема работы ядра нового процессора в полной мере соответствует рассмотренной схеме «классического» процессора. Поток инструкций в формате х86-64 ISA (о том, что это такое, мы расскажем чуть позже) поступает в схему предпроцессора (Front End) из кэша L1. Кэш первого уровня (L1) остался точно таким же, как и в процессорах семейства Athlon ХР, то есть имеет общий размер 128 Кбайт и разделен на кэш данных (D-cache) и кэш инструкций (I-cache), каждый размером по 64 Кбайт. Кэш L1 остался ассоциативным двухканальным с размером кэш-блока 64 байт. Кэш инструкций поддерживает два набора дескрипторов (тегов): fetch port (порт выборки) и snoop (слежение).
Кэш данных поддерживает 40-битный физический и 48-битный линейный адреса и уже три типа тегов: port A, port В и snoop. Кроме того, кэш данных поддерживает две 64-битные операции записи/чтения за один такт в различные банки кэша. Кэш второго уровня (L2) может иметь максимальный размер до 1 Мбайт. Сам кэш является эксклюзивным по отношению к кэшу L1,16-канальным, ассоциативным. Как и в большинстве современных х86-совместимых процессоров, имеющих внутреннюю RISC-архитектуру, в процессоре с архитектурой AMD 64 внешние CISC- команды декодируются во внутренние RISC-инструкции, для чего используется декодер команд.
Сначала инструкции х86 разделяются на большие (Large х86 Instruction) и маленькие (Small х86 Instruction). Большие, или сложные, инструкции поступают в программный (Microcode Engine) декодер, а маленькие, или простые, — в аппаратный (Fastpath) декодер. Оба декодера выполняют одну и ту же задачу — транслируют х86-инструкции в простейшие машинные команды (микрооперации), называемые Ops. Сами х86-команды могут быть переменной длины, а вот длина микроопераций уже фиксированная.
Простые инструкции при декодировании представляются с помощью двух-трех Ops-команд, и с этой задачей вполне может справиться аппаратный декодер, построенный на логических схемах. Сложные команды при декодировании могут представляться несколькими десятками и даже сотнями Ops-инструкций. Чтобы их декодировать, используется специализированный программный декодер, представляющий собой своеобразный процессор. Такой декодер содержит программный код, хранящийся в MIS (Microcode Instruction Sequencer), на основе которого воспроизводится последовательность Ops-инструкций.
Структурная схема процессора AMD Athlon 64
Каждый из двух декодеров может обрабатывать инструкцию длиной до 16 байт и выдавать по три Ops-инструкции за такт, поэтому в общей сложности оба декодера производят шесть декодированных инструкций за каждый такт процессора.
Попутно отметим, что декодер в новом ядре претерпел существенные изменения. Именно в него были добавлены две ступени конвейера по сравнению с ядром процессора Athlon ХР. Кроме того, известно, что если в ядре Athlon ХР команды SSE декодировались с использованием Microcode Engine, то есть считались сложными, то в новом ядре эти команды декодируются с использованием Fastpath, то есть являются простыми.
После прохождения декодера Ops-инструкции (по три за каждый такт) поступают во временный буфер хранения, называемый Instruction Control Unit (ICU). Этот буфер рассчитан на хранение 72 декодированных инструкций. Впрочем, хранение — не единственное предназначение ICU, а его главная задача заключается в диспетчеризации трех инструкций за такт по функциональным устройствам. То есть ICU распределяет инструкции в зависимости от их назначения и посылает инструкции по работе с целыми числами в целочисленный планировщик (Int. Scheduler), а инструкции для работы с вещественными числами — в планировщик для работы с вещественными числами (FPU Scheduler).
Планировщик для работы с вещественными числами рассчитан на 36 инструкций (как и в процессоре Athlon ХР), и его основная задача заключается в том, чтобы распределять команды по исполнительным блокам по мере их готовности. Просматривая все 36 поступающих инструкций, FPU-планировщик переупорядочивает следование команд, строя спекулятивные предположения о дальнейшем ходе программы, чтобы создать несколько полностью независимых друг от друга очередей инструкций, которые можно выполнять параллельно. В ядре процессора имеются три исполнительных блока нужных в работе с вещественными числами (FADD, FMUL и FMISC), поэтому FPU-планировщик должен формировать по три инструкции за такт, направляя их на исполнительные блоки.
Все целочисленные инструкции направляются в планировщик инструкций для работы с целыми числами, образованный тремя станциями резервирования (RES), каждая из которых рассчитана на восемь инструкций. Все три станции, таким образом, формируют планировщик на 24 инструкции (емкость аналогичного планировщика в процессоре Athlon ХР составляла 18 инструкций). Этот планировщик выполняет те же функции, что и FPU-планировщик. Различие заключается в том, что в процессоре имеется семь функциональных исполнительных блоков по работе с целыми числами (три устройства ALU, три устройства AGU и одно устройство MULT).
Исполнительные устройства также претерпели некоторые изменения по сравнению с процессором Athlon ХР. Как уже отмечалось, для работы с вещественными числами реализовано три функциональных устройства FPU, каждое из которых представляет собой 17-ступенчатый конвейер (как и в процессоре Athlon ХР), то есть в работе с вещественными числами предусмотрено три разделенных конвейера. Подобная реализация блока FPU позволяет выполнять до трех вещественных операций за такт, причем такая производительность является рекордной для х86-совместимых процессоров.
Блок операций с целыми числами также полностью конвейеризирован, но по сравнению с процессором Athlon ХР длина конвейера увеличена с 10 до 12 ступеней. Блок состоит из трех распараллеленных частей, что в итоге позволяет выполнять три целочисленные операции за один такт (кроме умножения). В умножении требуется три такта в случае 32-битных чисел и пять тактов в случае 64-битных.
Говоря об архитектурных особенностях нового ядра, нельзя не упомянуть об изменениях, коснувшихся кэша TLB (Translation Look-aside Buffers). Кэш TLB — это специальный кэш процессора, хранящий карту декодированных адресов инструкций и данных, что позволяет значительно сократить время доступа к ним. Данный кэш предназначен для уменьшения времени преобразования виртуального адреса данных или инструкций в физический. Дело в том, что процессор, в силу своих особенностей, не может хранить и использовать физические адреса, а пользуется виртуальной адресацией. Преобразование виртуального адреса в физический занимает приблизительно три такта процессора. TLB-кэш хранит результаты предыдущих преобразований, благодаря чему преобразование адреса данных, использовавшихся ранее, возможно осуществлять за один такт.
Ядро процессора имеет двухуровневый TLB (LI TLB и L2 TLB), также разделяющийся на буфер данных и буфер инструкций. LI TLB кэширует 40 адресов инструкций и 40 адресов данных. Этот кэш является полностью ассоциативным и поддерживает страницы емкостью как 4 Кбайт, так и 2 или 4 Мбайт.
Кэш L2 TLB является четырехканальным ассоциативным кэшем с поддержкой страниц емкостью 4 Кбайт. Этот кэш рассчитан на 512 записей, что в два раза больше, чем в процессоре Athlon ХР.
64-разрядная архитектура процессоров AMD
Как уже отмечалось, одним из главных новшеств процессоров AMD Athlon 64 является 64-разрядная архитектура х86-64 ISA. Прежде всего попытаемся ответить на вопрос: зачем вообще нужны 64-разрядные процессоры и имеют ли они преимущество перед 32-разрядными? Давайте вспомним, что 32-разрядная адресация памяти позволяет адресовать только 4 Гбайт памяти. Конечно, для пользовательских приложений на данный момент такого объема вполне хватает, но… это сейчас. А завтра все может измениться. В серверных приложениях 4 Гбайт памяти уже сегодня может оказаться явно недостаточно. Правда, современные серверные процессоры и чипсеты с х86-32-архитектурой позволяют адресовать более чем 4 Гбайт памяти (типичным значением является 12 Гбайт), но достигается это не за счет плоской прямой адресации, а за счет эмуляции 36-битной адресации (которая позволяет адресовать до 64 Гбайт памяти). Впрочем, такая адресация имеет и свои минусы. Во-первых, это отражается на производительности, а во-вторых, при такой эмуляции максимальная память, которую может использовать один поток приложения, все равно не превышает 4 Гбайт.
64-битная адресация, используемая в процессорах AMD Athlon 64, является полностью совместимой с архитектурой х86-32, то есть на таком процессоре вполне можно использовать и 32-разрядные приложения — просто при этом возможности процессора задействуются не в полной мере, но в любом случае дополнительный запас адресации не повредит. Последнее обстоятельство, то есть возможность использования обычных 32-разрядных приложений, в этом плане особенно важно. Для таких процессоров не потребуется специализированных операционных систем и программ, и нет нужды ждать, пока производители ПО перекомпилируют свои приложения.
Для реализации 64-разрядности в процессор добавлено несколько новых регистров, а существующие регистры соответственно расширены с 32 до 64 бит. Так, к восьми регистрам общего назначения добавлено еще восемь 64-битных регистров, использование которых возможно только при соответствующей перекомпиляции программного кода.
Расширение 32-битных регистров до 64-битных осуществляется точно так же, как в свое время (с момента появления процессора i386) 16-битные регистры были расширены до 32-битных.
Для реализации возможности работы как с 32-битными, так и с 64-битными приложениями процессор поддерживает два режима работы: Long Mode и Legacy Mode. В Long Mode используется 64-битный режим работы, причем здесь также предусмотрено два режима: 64-битный и Compability Mode (совместимый). 64-битный режим работы — это, собственно, истинный 64-битный режим, задействующий все дополнительные регистры процессора и 64-битные расширенные регистры. Для работы в этом режиме требуется соответствующая перекомпиляция ПО.
В режиме Compability Mode дополнительные регистры не задействуются, а в регистрах общего назначения используется только 32-битная часть. Единственное, что в данном случае напоминает о 64-битной архитектуре, — это использование 64-разрядной адресации и 64-битной операционной системы. В данном режиме не требуется перекомпиляции приложений для их нормальной работы.
В режиме Legacy Mode используется 32-разрядная операционная система, то есть 32-разрядная адресация. Кроме того, не задействуются дополнительные регистры, а в регистрах общего назначения используются только первые 32 бита. Таким образом, Legacy Mode — это традиционный 32-битный режим работы процессора.
Описав особенности ядра процессора, можно перейти к рассмотрению других элементов его архитектуры.
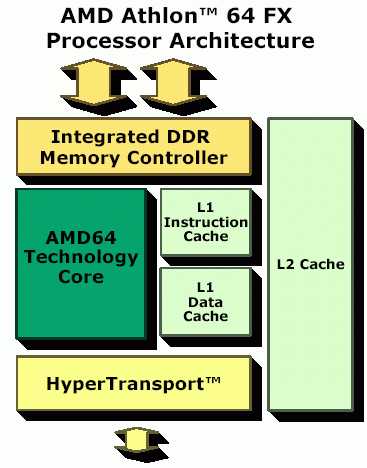
Контроллер памяти
Контроллер памяти в AMD Athlon 64 интегрирован в сам процессор. Традиционно он располагается в северном мосте чипсета на материнской плате. Собственно, контроллер памяти — это основной функциональный блок северного моста. Недаром в чипсетах Intel этот мост называют МСН (Memory Controller Hub). Преимущество такого решения очевидно — контроллер памяти, интегрированный в процессор, обеспечивает низкую латентность при обращении к памяти. Контроллер памяти процессора поддерживает ООИ2-память (DDR2-533/667/800) в двухканальном режиме работы и имеет ширину шины 64 бита.
Сам по себе контроллер памяти включает два функциональных блока: контроллер памяти МСТ и контроллер DRAM DCT. DCT — это физический интерфейс, зависящий от конкретного типа используемой памяти. МСТ — интерфейс согласования ядра процессора с DCT, не зависящий от типа используемой памяти.
Контроллер HyperTransport
Революционным новшеством процессора AMD Athlon 64 является поддержка шины Hyper Transport — универсальной шины межчипового соединения. В ее основу положены две концепции: универсальность и масштабируемость. Универсальность шины Hyper Transport заключается в том, что она позволяет связывать между собой не только процессоры, но и другие компоненты материнской платы, о чем мы еще расскажем. Масштабируемость шины дает возможность наращивать пропускную способность в зависимости от конкретных нужд пользователя.
Устройства, связываемые по шине Hyper Transport, соединяются по принципу «точка — точка» (peer-to-peer), что подразумевает возможность связывания в цепочку множества устройств без использования специализированных коммутаторов. Передача и прием данных могут происходить в асинхронном режиме, причем передача данных организована в виде пакетов длиной до 64 байт.
Масштабируемость шины HyperTransport обеспечивается посредством магистрали шириной 2, 4, 8,16 и 32 бита в каждом направлении. Кроме того, предусматривается возможность работы на различных тактовых частотах. При этом передача данных происходит по обоим фронтам тактового импульса.
dammlab.com
ГЛАВА 7. АРХИТЕКТУРА ПРОЦЕССОРОВ AMD
Американская компания AMD (Advanced Micro Devices, Inc.) в настоящий момент является второй по масштабам среди производителей x86 и x64-совместимых процессоров.
Ядро процессоров с архитектурой AMD использует другие принципы своего функционирования, по сравнению с Intel. По сути Athlon является RISC процессором – в режиме реального времени выполняется преобразование потока CISC команд в унифицированные RISC команды, которые согласно AMD-й терминологии называются MacroOps (mOP).
К8 – классический процессор Гарвардской архитектуры, см. рис. 7.1. Архитектура K8 используется во многих современных серверных, настольных и мобильных процессорах AMD (Opteron, Sempron, Athlon 64 и Athlon 64 X2). Эффективная длина конвейера (время в тактах от начала исполнения инструкции до момента, когда результаты выполнения будут записаны в оперативную память) варьируется от 10-12 стадий (для целочисленных, логических вычислений и обращений к оперативной памяти) до 17 стадий (вычисления с плавающей точкой). Количество одновременно исполняемых инструкций за такт в устоявшемся режиме – до трех; тактовые частоты серийно выпускаемых процессоров – от 1,6 до 2,8 ГГц.
Объем кэшей L1 D-cache (для данных) и L1 I-cache (для кода) – фиксирован и составляет по 64 Кбайт. В К8 имеется общий кэш второго уровня объемом от 128 до 1024 Кбайт. Кэш третьего и более низких уровней не предусмотрен.
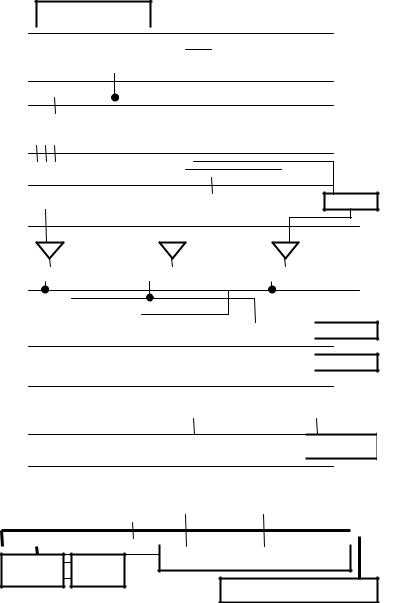
Исполнение инструкций на конвейере K8 начинается с блока выборки инструкций. За один такт блок выбирает из кэша 16 байт данных и выделяет из них от одной до трех инструкций x86 – сколько в выбранных данных поместилось. Поскольку средняя длина инструкции x86 составляет 5-6 байт, то, как правило, блоку удается выбрать три инструкции за такт. Чтобы облегчить процесс декодирования, инструкции, хранящиеся в кэшах L1, тегированы (т.е. в линейках кэша сохраняется информация о том, как внутри этой линейки распределены инструкции x86). Попутно с помощью блока предсказания переходов в этом же такте определяется адрес блока, с которого начнется выборка в следующем такте. Тегирование производится при выборке данных из кэша L2 в кэш L1 I- cache. На втором такте работы конвейера, выбранные одна-три инструкции x86, распределяются по трем блокам декодирования инструкций. Самые сложные инструкции, требующие декодирования с использованием микрокода процессора, отправляются в декодер VectorPath. Более простые – в декодеры DirectPath или в сдвоенный DirectPath Double. Начиная с этого момента, процессор переключается на работу с внутренними микроинструкциями (mOP).
Весь дальнейший конвейер строится на том, что работа с mOP – и происходит тройками инструкций (AMD называет их линиями, line). С логической точки зрения конвейер K8 строится таким образом, что обрабатывает именно линии, а не x86 – инструкции или отдельные микрооперации. При этом в одной линии может быть меньше трех микроопераций. В этом случае «нехватку» в тройке заполняют специальные пустые операции (null-mOP). При этом со «сложными» vector-инструкциями все элементарно – VectorPath-декодер подставляет на их место прошитые в микрокоде процессора линии. А вот декодирование «простых» инструкций превращается в сложный процесс преобразования x86-инструкции в один (DirectPath) или два (DirectPath Double) mOP-а, которые потом упаковываются в одну линию специальным упаковщиком. Сгенерированные линии от VectorPath- и DirectPath-декодеров по одной за такт поступают в специальное устройство – Instructions Control Unit (ICU), где подготовленные к исполнению линии накапливаются в специальной очереди (24 линии).
Из очереди в 24 линии по три mOP-а в каждой ICU выбирает в наиболее удобной для исполнения последовательности один-три mOP-а и пересылает их либо на ALU, либо на FPU – в зависимости от типа микрооперации. В случае ALU микрооперации сразу же попадают в очередь планировщика (шесть элементов по три mOP-а), который подготавливает необходимые для исполнения микрооперации ресурсы, дожидается их готовности и только потом отправляет mOP вместе со всеми необходимыми данными на исполнение.
101
I-Cache (L1 code)
|
|
|
|
|
Выборка и предсказание |
| Блок предсказания | ||
переходов |
| переходов | ||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Direct |
| Direct Path |
|
|
| Vector |
|
|
| Микрокод | |||||||||||||||
Path |
| Double |
|
|
| Path |
|
| процессора | ||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ||
| Inter — Instructions decoding |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ||||
Decode |
| Decode |
|
| Decode |
|
|
| Decode |
|
| Decode |
| ||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Такт 6 Такт 4 и 5 Такт 3 Такт 1 и 2
Decode
|
|
|
| Reorder Buffer |
|
| Reorder Buffer |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ||||||||||||
|
|
|
|
|
|
|
|
|
|
| Reorder Buffer |
|
|
|
|
|
|
| |||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Sche- |
|
| Sche- |
| Sche- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |||||||||
duler |
|
| duler |
| duler |
|
|
|
| STKREN |
|
|
| STKREN |
| STKREN | |||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| REGREN |
|
|
| REGREN |
| REGREN | ||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 и 12 | ||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| FP Scheduler |
|
|
|
| ||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Такт | |
AGU | ) ALU |
|
| AGU | ) ALU |
| AGU | ) ALU |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |||||||||
|
|
|
|
| Load DATA |
|
| Load DATA |
|
| Load DATA | ||||||||||||||||||||||||||||
dataL1 fetch ) | multiplication |
|
| dataL1 fetch ) | multiplication |
| dataL1 fetch ) | multiplication |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ||||||||||||||||||||
|
|
|
|
| Unit |
|
|
|
| Unit |
|
|
| Unit | |||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| FMISC |
|
|
| FMUL |
|
| FADD | |||||||||||||||
(if | (if |
|
| (if | (if |
| (if | (if |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
D-Cache | Load | mOPs |
| ||
(L1 data) |
| Регистры процессора |
|
|
Такт 8
Такт 9
Такт 10
Такт с 14 по 17 Такт 13
Рис. 7.1. Схема исполнения инструкций в AMD К8
Причем при исполнении одного mOP-а на самом деле может происходить исполнение сразу двух действий – несложных арифметических вычислений, которые часто возникают при обращении к оперативной памяти (ими занимается блок Address Generation Unit, AGU), и «сложных», требующих вмешательства ALU, – соответствующая «двойка» микроинструкций (ROP) закладывается в mOP еще на стадии декодирования. Подготовка данных в планировщике занимает (в идеальном случае) один такт, исполнение – от одного (подавляющее большинство инструкций) до трех (при обращении к оперативной памяти) и даже пяти (64-битное умножение) тактов.
В блоке FPU все чуточку сложнее. Для начала вышедшие из ICU mOP проходят две стадии по подготовке их операндов. Затем – накапливаются в планировщике FPU (двенадцать элементов по три mOP), который, дожидается, пока данные для этих mOP-ов будут готовы, а исполнительные устройства освободятся, и разбрасывает накопленные mOP-ы по трем исполнительным устройствам. Но в отличие от целочисленной части конвейера (где содержатся по три одинаковых блока ALU и AGU), исполнительные устройства FPU «специализированы» – каждое производит только свой специфический набор действий над числами с плавающей запятой. Время выполнения: два такта на переименование и отображение регистров, один такт (в идеале) на планирование и ожидание операндов, четыре такта на собственно исполнение.
Механизм прогнозирования в процессорах AMD более продвинутый, чем у аналогов из Intel, в частности используется не только таблица BTB, но и таблица глобальной истории переходов GHBC (Global History Bimodal Counters). И если BTB позволяет предсказывать переходы исходя из информации о предыдущих исходах именно этой команды, то GHBC позволяет учесть при
102
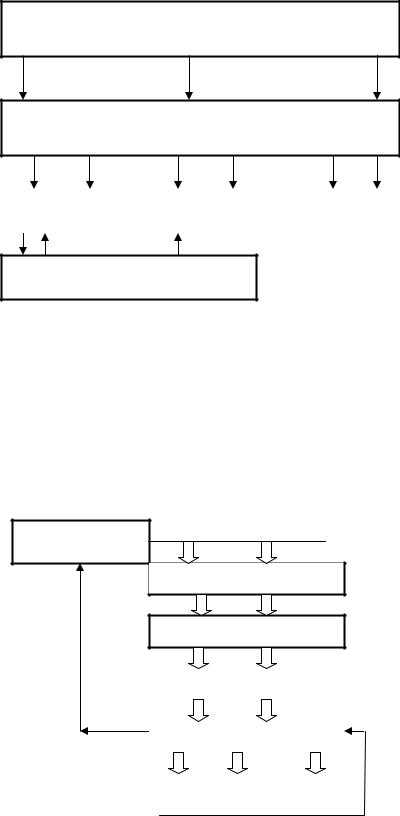
прогнозировании и исходы определенного количества условных переходов выполненных до текущего.
Еще применяется прогнозирование адреса возврата, используется специальный буфер, в который заносится следующий EIP после выборки CALL. При выборке ret процессор достает адрес возврата из своего буфера, а не из стека (попытки его перезаписать отслеживаются).
Целочисленное устройство в процессорах AMD выглядит следующим образом, см. рис. 7.2.
Instruction Control Unit and Register Files
(Устройство управления потоком команд и регистрами)
Микрооперации (МacroOPs) Микрооперации (МacroOPs)
Integer Scheduler (18-entry)
(Целочисленный планировцик)
IEU0 | AGU0 |
| IEU1 | AGU1 |
| IEU2 | AGU2 |
|
|
|
|
|
|
|
|
Integer Multiply (IMUL)
Рис. 7.2. Целочисленный блок в процессорах AMD
Одна из причин, по которым процессоры AMD очень часто превосходят интеловские аналоги в тестах FPU, заключается в том, что они имеют «продвинутый» блок операций с плавающей точкой.
Это больше чем просто блок для FPU операций, по сути, это отдельный процессор. Используется отдельный блок переименования регистров, собственный планировщик и собственные исполнительные устройства.
У Intel, хотя и используются разные функциональные блоки, регистры FPU имеют такой же статус, как и регистры IEU и обслуживаются одной и той же RAT (RAT – Register Alias Table) и ROB (ROB – ReOrder Buffer).
Здесь же имеем полную изоляцию от целочисленного устройства, см. рис. 7.3.
Instruction Control |
| Такты |
Unit |
| 7 |
| Stack Map | |
|
| |
|
| 8 |
Register Rename
| 9, | |
Scheduler (36 – entry) | ||
10 | ||
| ||
|
|
|
| FPU Register File (88 – entry) | 11 | ||||||
|
|
|
|
|
|
|
| 12 | |
|
|
|
|
|
|
|
| ||
|
|
|
|
|
|
|
|
| — |
FADD |
| FMUL |
| FSTORE |
| ||||
|
|
| 15 | ||||||
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 7.3. Блок операций с плавающей точкой в процессорах AMD
103
После выполнения микроопераций в работу включается LSU (Load/Store Unit). Шины результата заведены именно на него. Кроме того, строки буфера могут использоваться как операнды.
В конце 2010 года компания AMD поделилась некоторой информацией о готовящихся к выходу процессорах, основанных на архитектурах Bulldozer и Bobcat, которые должны поступить на рынок в 2011 году.
Процессорная архитектура Bulldozer предназначена для создания чипов, ориентированных на применение в составе серверов, настольных компьютеров и ноутбуков. В то же время процессоры Bobcat будут использоваться в нетбуках, неттопах и мобильных устройствах. Первым чипом Bobcat станет 32-нанометровый APU (accelerated processing unit) Ontario, он в рамках одного кристалла получит одно вычислительное x86 ядро, контроллер памяти, графическое ядро и 512 КБ кэш-памяти второго уровня. Сообщается, что энергопотребление ядра такого устройства составит до 1 Вт. При этом уровень производительности процессора будет на уровне 90% относительно современных массовых решений, но при значительно меньших размерах чипа.
Архитектура Bulldozer дебютирует в серверном сегменте в рамках платформ Interlagos и Valencia Opteron. Первые процессоры также будут изготавливаться по нормам 32-нанометрового технологического процесса. Они получат модульную структуру, при этом каждый модуль включает в себя: один блок Float Point Scheduler, два блока Integer Scheduler с собственной кэш-памятью первого уровня для каждого блока, общую кэш-память второго уровня. При этом заявлено увеличение количества используемых ядер на 33% и увеличение производительности на 50% по сравнению с процессорами предшествующего поколения.
Вопросы для самоконтроля
1.Назовите основные блоки и их функциональное назначение в структуре процессоров
AMD.
2.В чем заключается отлицие архитектуры процессоров AMD от Intel?
Литература для самостоятельной подготовки по теме:
12, 13, 20.
104
studfiles.net
Архитектуры AMD 64 (K8) и Stars
AMD64 (также x86-64 или x64) — 64-битная архитектура микропроцессора и соответствующий набор инструкций, разработанные компанией AMD. Это расширение архитектуры x86 с полной обратной совместимостью. Набор инструкций x86-64 в настоящее время поддерживается процессорами AMD Athlon 64, Athlon 64 FX, Athlon 64 X2, Turion 64, Opteron, последними моделями Sempron. Интересно, что этот набор инструкций был поддержан основным конкурентом AMD — компанией Intel под названием EM64T или IA-32e в поздних моделях процессоров Pentium 4, а также в Pentium D, Pentium Extreme Edition, Celeron D, Core 2 Duo и Xeon. Корпорация Microsoft использует для обозначения этого набора инструкций термин x64.
Режимы работы
Процессоры архитектуры поддерживают два режима работы: Long mode («длинный» режим) и Legacy mode (режим совместимости с x86).
Long Mode
«Длинный» режим — «родной» для процессоров AMD64. Этот режим позволяет воспользоваться всеми дополнительными возможностями, предоставляемыми архитектурой AMD64. Для использования этого режима необходима 64-битная операционная система, например, Windows XP Professional x64 Edition или 64-битный вариант GNU/Linux. Этот режим позволяет выполнять 64-битные программы; также (для обратной совместимости) предоставляется поддержка выполнения 32-битного кода, например, 32-битных приложений, хотя 32-битные программы не смогут использовать 64-битные системные библиотеки, и наоборот. Чтобы справиться с этой проблемой, большинство 64-разрядных операционных систем предоставляют два набора необходимых системных файлов: один — для родных 64-битных приложений, и другой — для 32-битных программ. (Этой же методикой пользовались ранние 32-битные системы — например, Windows 95 — для выполнения 16-битных программ)
Legacy Mode
Данный режим позволяет процессору AMD64 выполнять инструкции, рассчитанные для процессоров x86, и предоставляет полную —совместимость с 32/16-битным кодом и операционными системами. В этом режиме процессор ведёт себя точно так же, как x86-процессор, например Pentium 4, и дополнительные функции, предоставляемые архитектурой AMD64 (например, дополнительные регистры) недоступны. В этом режиме 64-битные программы и операционные системы работать не будут.
Особенности архитектуры
 Разработанный компанией AMD набор инструкций x86-64 (позднее переименованный в AMD64) — расширение архитектуры Intel IA-32 (x86-32). Основной отличительной особенностью AMD64 является поддержка 16-ти 64-битных регистров общего назначения (против 8-и 32-битных в x86-32), 64-битных арифметических и логических операций над целыми числами и 64-битных виртуальных адресов.
Разработанный компанией AMD набор инструкций x86-64 (позднее переименованный в AMD64) — расширение архитектуры Intel IA-32 (x86-32). Основной отличительной особенностью AMD64 является поддержка 16-ти 64-битных регистров общего назначения (против 8-и 32-битных в x86-32), 64-битных арифметических и логических операций над целыми числами и 64-битных виртуальных адресов.
Архитектура x86_64 имеет
16 целочисленных 64-битных регистра общего назначения (RAX, RBX, RCX, RDX, RBP, RSI, RDI, RSP, R8 — R15),
 Opteron (кодовое название Sledgehammer или K8) — первый микропроцессор фирмы AMD, основанный на 64-битной технологии AMD64 (также называемой x86-64). AMD создала этот процессор в основном для применения на рынке серверов, поэтому существуют варианты Opteron для использования в системах с 1-16 процессорами.
Opteron (кодовое название Sledgehammer или K8) — первый микропроцессор фирмы AMD, основанный на 64-битной технологии AMD64 (также называемой x86-64). AMD создала этот процессор в основном для применения на рынке серверов, поэтому существуют варианты Opteron для использования в системах с 1-16 процессорами.
В июне 2004 года в Top500 суперкомпьютеров десятое место занял Dawning 4000A — китайский суперкомпьютер построенный на процессорах Opteron. В ноябре 2005 он опустился на 42 место, в связи с появлением более производительных конкурентов. Тогда в ноябрьском Top500 10 % суперкомпьютеров были построены на базе процессоров AMD64 Opteron. Для сравнения, на базе процессоров Intel EM64T Xeon были построены 16.2 % суперкомпьютеров. Две ключевые особенности
Двумя важными технологиями воплощёнными в процессоре Opteron являются: Прямая (без эмуляции) поддержка 32-битных x86 приложений без потери скорости Прямая (без эмуляции) поддержка 64-битных x86-64 приложений (линейная адресация более 4 ГБ ОЗУ)
Первая технология примечательна тем, что во время анонса процессора Opteron единственным 64-битным процессором с заявленной поддержкой 32-битных x86 приложений был Intel Itanium. Но Itanium выполнял 32-битные приложения со значительной потерей скорости.
Вторая технология, сама по себе не так примечательна, так как основные производители RISC процессоров (SPARC, DEC, HP, IBM, MIPS и другие) имели 64-битные решения уже много лет. Но совмещение в одном продукте этих 2-х свойств, напротив, принесло Opteron признание, так как он предлагал доступное и экономичное решение для запуска существующих x86 приложений с последующим переходом на более перспективные 64-битные вычисления.
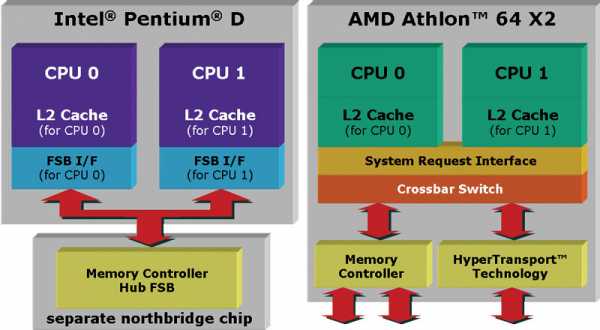
Процессоры Opteron имеют интегрированный контроллер памяти DDR SDRAM. Это позволило существенно уменьшить задержки при обращении к памяти и исключить необходимость в отдельном чипе северного моста на материнской плате.
В мае 2005 года AMD представила первый «многоядерный» процессор Opteron. В настоящее время термин «многоядерный» компания AMD использует для обозначения «двухъядерных» процессоров; в каждом процессоре Opteron размещено 2 отдельных процессорных ядра. Это фактически удваивает вычислительную мощность доступную каждому процессорному разъёму на материнских платах, поддерживающих эти процессоры.
 Одним из “топовых” процессоров AMD сегодня считается — Athlon X2 6000+ на ядре Windsor под сокет AM2. Этот процессор содержит два ядра Athlon 64, объединённых на одном кристалле с помощью набора дополнительной логики. Ядра имеют в своём распоряжении двухканальный контроллер памяти, базирующийся на Athlon 64 степпинга E, и в зависимости от модели, от 512 до 1024 КБ КЭШа 2-го уровня на каждое ядро. Athlon 64 X2 поддерживают набор инструкций SSE3 (которые ранее поддерживались только процессорами компании Intel), что позволило запускать с максимальной производительностью код, оптимизированный для процессоров Intel. Эти улучшения не уникальны для Athlon 64 X2 и так же имеются в релизах процессоров Athlon 64, построенных на ядрах Venice и San Diego. AMD официально начала поставки Athlon 64 X2 на выставке Computex 1 июня 2005 года.
Одним из “топовых” процессоров AMD сегодня считается — Athlon X2 6000+ на ядре Windsor под сокет AM2. Этот процессор содержит два ядра Athlon 64, объединённых на одном кристалле с помощью набора дополнительной логики. Ядра имеют в своём распоряжении двухканальный контроллер памяти, базирующийся на Athlon 64 степпинга E, и в зависимости от модели, от 512 до 1024 КБ КЭШа 2-го уровня на каждое ядро. Athlon 64 X2 поддерживают набор инструкций SSE3 (которые ранее поддерживались только процессорами компании Intel), что позволило запускать с максимальной производительностью код, оптимизированный для процессоров Intel. Эти улучшения не уникальны для Athlon 64 X2 и так же имеются в релизах процессоров Athlon 64, построенных на ядрах Venice и San Diego. AMD официально начала поставки Athlon 64 X2 на выставке Computex 1 июня 2005 года.
 Основным преимуществом, которое даёт двуядерные процессоры Athlon 64 X2 является возможность разделения запущенных программ на несколько одновременно выполняемых потоков. Способность процессора выполнять одновременно несколько программных потоков называется параллелизм на уровне потоков (thread-level parallelism или (TLP)). При размещении двух ядер на одном кристале, Athlon 64 X2 обладает двойным TLP по сравнению с одноядерным Athlon 64 при той же скорости. Необходимость в TLP зависит от конкретной ситуации в большей степени и в некоторых ситуациях она просто бесполезна. Большинство программ написаны с расчётом на работу в однопоточном режиме, и поэтому просто не могут задействовать вычислительные мощности второго ядра. Программы, написанные с учётом работы в многопоточном режим и способные использовать вычислительные мощности второго ядра, включают в себя множество приложений для обработки музыки и видео. Имея два ядра, Athlon 64 X2 обладает увеличенным количеством транзисторов на кристалле. Процессор Athlon 64 X2 с 1МБ КЭШа 2-го уровня имеет 233.2 миллиона транзисторов [1], в отличие от Athlon 64, имевшего всего 114 миллиона транзисторов [2]. Такие размеры требуют использования для производства более тонкого технологического процесса, который позволяет добиться выхода необходимого количества исправных процессоров с одной кремневой пластины. Athlon 64 X2 построен на ядрах: Toledo; Manchester; Windsor по 90 нм техпроцессу. Совсем недавно компания AMD официально представила свою новую платформу для настольных ПК под кодовым названием AMD Spider.
Основным преимуществом, которое даёт двуядерные процессоры Athlon 64 X2 является возможность разделения запущенных программ на несколько одновременно выполняемых потоков. Способность процессора выполнять одновременно несколько программных потоков называется параллелизм на уровне потоков (thread-level parallelism или (TLP)). При размещении двух ядер на одном кристале, Athlon 64 X2 обладает двойным TLP по сравнению с одноядерным Athlon 64 при той же скорости. Необходимость в TLP зависит от конкретной ситуации в большей степени и в некоторых ситуациях она просто бесполезна. Большинство программ написаны с расчётом на работу в однопоточном режиме, и поэтому просто не могут задействовать вычислительные мощности второго ядра. Программы, написанные с учётом работы в многопоточном режим и способные использовать вычислительные мощности второго ядра, включают в себя множество приложений для обработки музыки и видео. Имея два ядра, Athlon 64 X2 обладает увеличенным количеством транзисторов на кристалле. Процессор Athlon 64 X2 с 1МБ КЭШа 2-го уровня имеет 233.2 миллиона транзисторов [1], в отличие от Athlon 64, имевшего всего 114 миллиона транзисторов [2]. Такие размеры требуют использования для производства более тонкого технологического процесса, который позволяет добиться выхода необходимого количества исправных процессоров с одной кремневой пластины. Athlon 64 X2 построен на ядрах: Toledo; Manchester; Windsor по 90 нм техпроцессу. Совсем недавно компания AMD официально представила свою новую платформу для настольных ПК под кодовым названием AMD Spider.
Платформа Spider

Состав платформы Spider

Основным компонентом данной платформы является процессор линейки AMD Phenom, совместно с чипсетом семейства AMD 7-Series. 
Платформа AMD Spider: общие характеристики
Представляя вниманию широкой публике новые технологии, AMD делает акцент именно на платформенном характере инноваций. Ключевым компонентом платформы Spider являются многоядерные процессоры AMD Phenom (вплоть до 4-ядерных), выполненные с соблюдением норм 65 нм техпроцесса и предназначенные для работы с системными платами, оснащёнными разъёмом Socket AM2+. Помимо этого, в состав платформы Spider входит новое поколение чипсетов AMD 7 Series для создания системных плат с поддержкой технологий CrossFireX и AMD OverDrive, а также графика семейства ATI Radeon HD 3800 с поддержкой Microsoft DirectX 10.1.
Схема платформы AMD Spider
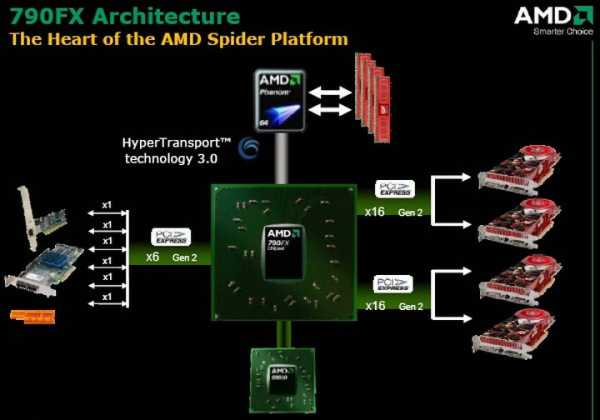
Если отбросить в сторону многословие пресс-релизов, основной инновацией, реализованной в платформе AMD Spider, можно назвать значительное повышение параметра “производительность на ватт”, главным образом, за счёт энерго-эффективного дизайна 65 нм процессоров AMD Phenom, 65 нм чипсетов AMD 7-Series и 55 нм графических чипов семейства ATI Radeon HD 3800. Наряду с этим, платформа AMD Spider обладает поддержкой ряда специфических технологий экономии энергии: ATI PowerPlay, Cool’n’Quiet 2.0, Microsoft DirectX 10.1, HyperTransport 3.0 и PCI Express 2.0. В частности, технология Cool’n’Quiet 2.0 позволяет снижать энергопотребление процессоров AMD Phenom, обладающих TDP 95 Вт, до средних 32 Вт в бытовых и средних 29 Вт в коммерческих приложениях. В то же время технология AMD CoolCore, реализованная в чипсетах AMD 7-Series, обеспечивает работу ядер процессора на разных частотах и, соответственно, снижение энергопотребления, при этом TDP чипсетов в среднем составляет порядка 10-12 Вт.
Другая инновация платформы AMD Spider – значительная её масштабируемость, беспрецедентная для решений на базе процессоров AMD. Так, системные платы на базе чипсетов AMD 7-Series, благодаря технологии ATI CrossFireX и поддержке до 42 линий PCI Express, обладают возможностью работы с тремя или четырьмя графическими картами ATI Radeon HD 3800. С точки зрения микроархитектуры процессоров AMD, новые чипы 4-ядрные чипы Phenom для настольных ПК, выполненные на базе архитектуры Stars (ядро Agena), являются “ближайшими родственниками” новых 4-ядерных серверных процессоров AMD Opteron на базе ядра Barcelona.
В полной аналогии с ядром Barcelona, архитектура Stars обладает 128-битным контроллером памяти с поддержкой до DDR2-1066, который также обладает возможностью работы в 2-канальном 64-битном режиме для независимого выполнения операций записи и чтения памяти. Физическое адресное пространство при этом увеличилось до 48 бит, а поддержка памяти до 256 Тб. 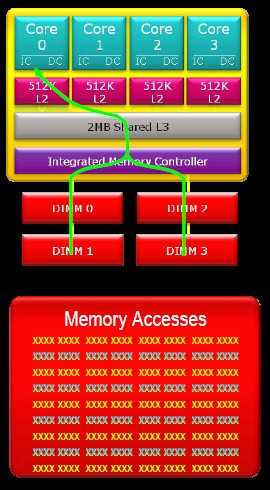
Каждое из четырёх ядер процессора Phenom обладает собственным 64 Кб собственной кэш-памяти L1 для инструкций и 64 Кб кэш-памяти L1 для данных, что в сумме составляет 512 Кб кэш-памяти L1 на процессор. Суммарный объём кэш-памяти L2 составляет 2 Мб, по 512 Кб на каждое ядро. Помимо этого, архитектуры Barcelona и Stars подразумевают наличие 2 Мб кэш-памяти L3. В отличие от кэш-памяти уровней L1 и L2, эксклюзивных для каждого ядра, кэш-память L3 динамически распределяется между всеми ядрами.
Среди ключевых характеристик, присущих новым 4-ядерным процессорам Phenom, следует отметить следующие ключевые функциональные возможности: Наличие нового планировщика задач с плавающей запятой, теперь поддерживающего 36 новых 128-битных операций Поддержка 128-битных операций SSE, появившихся в дополнение к возможностям прежней 64-битной архитектуры Возможность обработки двух операций SSE и одного SSE переноса за такт Буфер модуля выборки инструкций стал 32 байтным (ранее 16 байт) Модуль предсказания ветвлений с 512-ходовым предсказанием непрямых ветвлений Производительность кэша данных увеличена с одной 64-битной загрузки за такт до одной 128-битной загрузки за такт Производительность кэша данных L2 — контроллера памяти увеличена с 64-битной загрузки на такт до 128-битной загрузки за такт Реализация шины HyperTransport 3.0 позволила увеличить пропускную способность до 20,8 Гб/с Реализация технологии AMD Virtualization Technology с функцией быстрой индексации Rapid Page Indexing
В дополнение также необходимо отметить появление в процессорах Phenom поддержки системы динамического управления тактовой частотой по каждому ядру. Поскольку архитектура не позволяет регулировать напряжение питания каждого ядра в независимом режиме, дополнительное энергосбережение обеспечивается снижением тактовой частоты каждого ядра в режиме простоя.
Новые чипсеты AMD 7 Series для настольных ПК

Ключевые характеристики чипсетов AMD 7 Series
| Чипсет | AMD 790FX | AMD 790X | AMD 770 |
|---|---|---|---|
| HyperTransport 3.0 | + | + | + |
| PCI Express Gen. 2.0 | + | + | + |
| Слотов под видеокарты | До 4 | До 2 | 1 |
| GPU-Plex Technology | + | + | — |
| Quad PCIE Blocks | + | + | — |
| ATI CrossFireX Technology | + | + | — |
| Обратная совместимость | + | + | + |
Согласно информации, полученной от источника из среды тайваньских производителей системных плат, компания AMD на днях известила своих партнеров о намерении начать отгрузку трехъядерных процессоров Phenom X3 (Toliman) уже в феврале 2008 года, а не в марте, как планировалось ранее. Двухъядерные процессоры Kuma появятся только в конце второго квартала будущего года.
Напомним, что первые трехъядерные процессоры, модели 7700 и 7600, будут работать на частотах 2,5 ГГц и 2,3 ГГц, соответственно, тепловыделение моделей установлена в 89 Вт. Тактовые частоты процессоров Kuma, моделей 6250 и 6050, пока не называются, известно лишь, что их TDP будет на уровне 65 Вт.
wiki.vspu.ru
Подробнее об особенностях микроархитектуры AMD Zen
Новая процессорная архитектура Zen компании AMD имеет множество отличий от предыдущей архитектуры. О некоторых особенностях процессоров Zen мы уже писали, но изменения коснулись большинства составляющих процессоров, и в этом материале мы достаточно подробно разберём некоторые «тонкости» новой архитектуры, основываясь на материале, подготовленном нашими коллегами из AnandTech.
Значительным отличием от предыдущих архитектур стало появление кэш микроопераций (micro-op cache). Архитектура Bulldozer не предусматривала данный кэш, вместо чего детали для реализации часто используемых микроопераций извлекались из других кэшей. Intel использует подобную кэш-память уже на протяжении нескольких поколений процессоров, и появление этого кэша в процессорах AMD сулит им лишь увеличение скорости работы. К сожалению, объём кэша микроопераций пока что не уточняется, но говорится что он «большой».
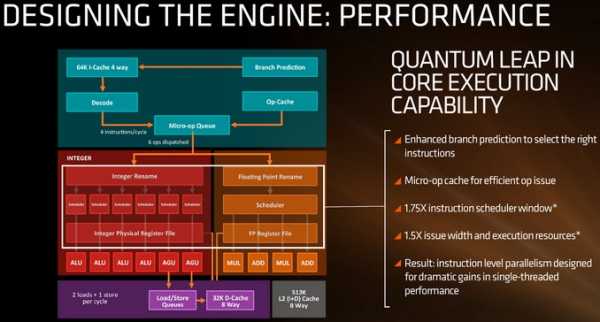
Нажмите для увеличения
AMD не стала распространяться о механизмах работы декодера, уточнив лишь, что процессоры Zen получат «усовершенствование прогнозирования ветвлений» (branch prediction), а также что сами процессоры смогут декодировать четыре инструкции за такт, загружая их из очереди операций. Эта очередь с помощью кэша микроопераций, сможет загружать в планировщик 6 операций за цикл. Возможна будет загрузка и большего числа операций за цикл, если декодер сможет подать команду, которая потом разделится на две микрокоманды. Очередь микроопераций сможет подавать отдельно операции с целыми числами (INT) и с числами с плавающей запятой (FP). То есть AMD будет использовать отдельные планировщики, тогда как Intel использует общий INT/FP планировщик.
Целочисленная часть (INT) отвечает за работу с операциями в арифметико-логических устройствах (ALU), а также с инструкциями загрузки и сохранения в блоках генерации адреса (AGU). AGU сможет выполнять две загрузки по 16 Байт и одно сохранение на 16 Байт за цикл, используя 32 Кбайт 8-канального множественно-ассоциативного кэша перового уровня (L1) с обратной записью. Процессоры предыдущего поколения использовали кэш со сквозной записью, который являлся причиной значительных задержек при обработке частей кода. Также AMD утверждает, что операции загрузки/сохранения будут иметь значительно меньшее время ожидания в пределах кэшей, по сравнению с предшественниками.
FP-часть включает по два умножителя (MUL) и сумматора (ADD), которые обеспечат одновременную обработку двух команд умножения-сложения с однократным округлением (FMAC), и одной 256-битной AVX-команды за цикл. Сочетание частей INT и FP указывает, что AMD создала в Zen «большие» ядра и будет использовать много параллельных вычислений на уровне команд. Насколько хорошо это всё покажет себя на практике, зависит от кэша и буферов восстановления последовательности, ибо по буферам пока что нет точных данных.

Устройство кэш-памяти также претерпело изменения в архитектуре Zen. Объём и ассоциативность кэша данных первого уровня (L1-D) по сравнению с архитектурой Bulldozer были удвоены. Кэш инструкций первого уровня (L1-I) в новой архитектуре не разделён между двумя ядрами, и у него удвоена ассоциативность, что снижает количество промахов. Также AMD заявляет, что были уменьшены задержки и у кэша L1-D, и у L1-I.
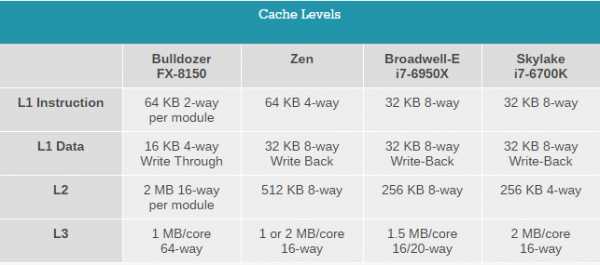
На каждое ядро приходится по 512 Кбайт кэша второго уровня (L2) и он имеет 8-канальную (8-way) ассоциативность, что вдвое больше по сравнению с процессорами Intel Skylake (256 Кбайт/ядро и 4 канала). Что касается кэш-памяти третьего уровня (L3), то здесь возникла некоторая неопределённость. На слайде чётко указано, что объём кэша L3 равен 8 Мбайт, но не уточняется, на сколько ядер рассчитан этот кэш. По неофициальным данным 8-ядерные процессоры Zen получат по два набора кэша L3 по 8 Мбайт, предназначенные для каждой четвёрки ядер. То есть на одно ядро будет приходиться 2 Мбайт 16-канального L3-кэша, но в процессоре фактически не будет общего LLC-кэша, как это реализовано у Intel. Потенциально это может повысить производительность отдельного потока, но не приведёт ли это к снижению многопоточной производительности. Отметим, что AMD обещает пятикратный рост пропускной способности кэшей по сравнению с предыдущими архитектурами.
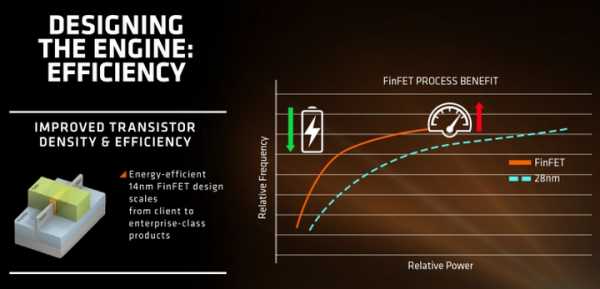
Также в новой архитектуре AMD плотно занялась вопросом энергопотребления. Сообщается, что в первую очередь достаточно низкое энергопотребление у процессоров Zen обеспечит использования 14-нм техпроцесса FinFET. Кроме того, для уменьшения энергопотребления и улучшения эффективности работы использованы некоторые методы и технологии (доработанные и улучшенные), зарекомендовавшие в процессорах Carrizo и Bristol Ridge для ноутбуков.
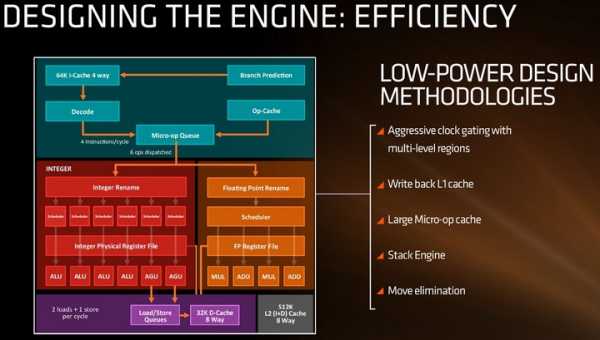 Нажмите для увеличения
Нажмите для увеличенияРазработчики AMD отмечают, что снижению энергопотребления способствует агрессивный Clock gating (запрет подачи тактовых сигналов на неиспользуемые части процессора), кэш перового уровня с обратной записью, использование «большого» объёма кэша микроопераций и другие новшества архитектуры.
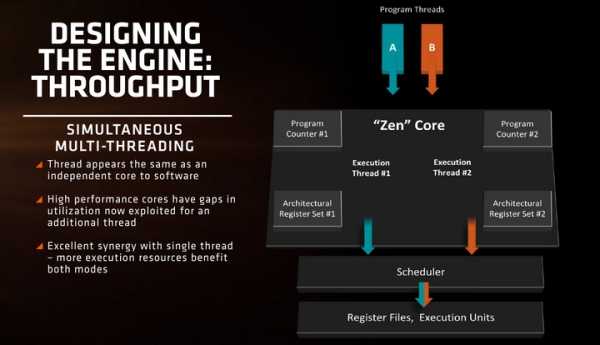
Каждое ядро процессора Zen, как давно известно, будет поддерживать два потока или одновременную многопоточность (Simultaneous multithreading или SMT). Главная сложность в реализации данной технологии заключается в том, что потоки не должны блокировать друг друга, загружая весь кэш и буферы. Именно здесь и пригодится собственный для каждого ядра кэш L2, разделение блоков INT и FP, и другие особенности позволят разделить нагрузку равномерно, не создавая конфликта между потоками.
overclockers.ru
Особенности архитектуры AMD К10
Опубликовано ноября 10, 2010 в Компоненты ПК, Процессоры
В этой статье мы подробно рассмотрим особенности архитектуры AMD К10. На базе данной архитектуры вышло целое семейство новых серверных и настольных микропроцессоров. Процессоры этой архитектуры, производимые по степпингам В2 и ВА, имели ошибку в контроллере памяти (так называемый TLB bug), которая приводила к нестабильной работе системы. Таким образом, первый выход, в свет AMD К10 нельзя назвать гладким.

Обнаруженная ошибка была оперативно устранена программным путем, что не преминуло сказаться на производительности. Особенно это было заметно в системах, использующих ОС семейства Windows. Позже вышли новые ревизии процессоров, изготовленных по новым техпроцессам, где эта критическая ошибка была устранена.
Первые упоминания о микроархитектуре следующего поколения, которая должна была прийти на смену микроархитектуре AMD К8, появились в далеком 2003 году. В частности, на форуме Microprocessor Forum 2003 отмечалось, что новая микроархитектура будет положена в основу многоядерных процессоров, которые будут работать с тактовыми частотами до 10 ГГц. Позднее, конечно, иллюзии относительно заоблачных тактовых частот прошли, а новая микроархитектура стала постепенно приобретать все более конкретные очертания. Так, летом 2006 года появились планы по выходу процессоров на ее базе. Правда, тогда новая микроархитектура значилась под кодовым наименованием K8L, и только в феврале 2007 года ей было дано название AMD К10.
Итак, что же нового в микроархитектуре AMD К10? Четырехъядерные процессоры на базе новой микроархитектуры имеют площадь кристалла 291 мм2 и содержат порядка 463 млн транзисторов. Они выполняются по 65-нанометровому техпроцессу (SOI) и содержат 11 слоев.
Технология AMD Memory Optimizer
Одно из существенных нововведений в микроархитектуре AMD К10 — это новый контроллер памяти. В процессорах AMD К8 использовался один 128-битный контроллер памяти, который можно рассматривать как два спаренных 64-битных контроллера. В микроархитектуре AMD К10 применяются два независимых 64-битных контроллера памяти, что позволяет существенно ускорить доступ к памяти.
Чтобы понять, почему использование двух независимых 64-битных контроллеров памяти более эффективно, чем применение одного 128-битного, вспомним, что современные модули памяти являются именно 64-битными. Для увеличения пропускной способности подсистемы памяти используется одновременный доступ к двум различным модулям памяти по двум 64-битным каналам (двухканальный режим работы). Это позволяет теоретически в два раза увеличить пропускную способность подсистемы памяти, поскольку за каждый такт работы контроллера памяти можно считывать две порции данных объемом по 64 бита, то есть всего 128 бит.
Однако применение двухканальной схемы работы контроллера памяти имеет и свои нюансы. Проблема заключается в том, что если процессору потребовались 64 бита данных (данные А), хранящиеся по адресу #1, то вместе с ними одновременно будут считаны и 64 бита данных (данные В), хранящихся по соседнему адресу #2 в другом модуле памяти. В операциях линейного чтения больших объемов данных такая ситуация лишь удваивает пропускную способность памяти. Однако может оказаться, что процессору не нужны считанные данные В, а нужны только данные А. В этом случае двухканальный режим работы памяти не позволяет получить выигрыш в производительности и, соответственно, 128-битный контроллер памяти будет функционировать с эффективностью одного 64-битного.
Применение двух независимых 64-битных контроллеров памяти, как в микроархитектуре AMD К10, позволяет одновременно загружать блоки данных с произвольными адресами из различных модулей памяти.
Предположим, что процессору необходимо произвести операцию умножения двух чисел. Первое число — это Data А, которое имеет адрес #1, а второе число — Data D, имеющее адрес #4. Пусть Data А хранится в первом модуле памяти, a Data В — во втором. В случае использования 128-битного контроллера памяти придется сначала загрузить 64 бита данных по адресу #1 (Data А) из первого модуля памяти и одновременно с этим — 64 бита данных по адресу #2 (Data В), которые процессору не нужны. Далее будут загружены 64 бита данных по адресу #3 (Data С), которые также не нужны процессору, и 64 бита данных по адресу #4 (Data D). Как видите, применение 128-битного контроллера памяти в данном случае малоэффективно. Если же используются два независимых 64-битных контроллера памяти, то за один такт загружается 64 бита данных по адресу #1 (Data А) и 64 бита данных по адресу #4 (Data D).
Новая технология доступа к памяти называется AMD Memory Optimizer Technology. Кроме применения двух независимых 64-битных контроллеров памяти вместо одного 128-битного, имеются и другие улучшения контроллера памяти. Так, оптимизирован алгоритм переупорядочения операций чтения/записи, что позволяет
наиболее эффективно использовать шину памяти. Операции чтения имеют преимущество перед операциями записи, а данные, предназначенные для записи, откладываются в специальном буфере. Кроме того, контроллер памяти умеет анализировать последовательности запросов и делать соответствующую предвыборку.
Ядро процессора
Структурная блок-схема одного ядра процессора на базе микроархитектуры AMD К10 показана на рисунке ниже.
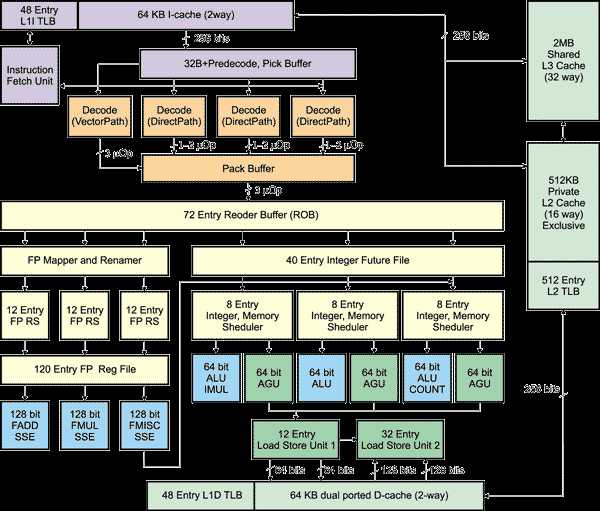
Структурная блок-схема одного ядра процессора на базе микроархитектуры AMD К10
Изучая структурную схему нового ядра и сравнивая ее со схемой легендарного К8, можно заметить, что общих черт у них больше, чем различий.
Собственно, микроархитектура К10 наследует черты К8, являясь ее логическим развитием. Используется все тот же 12-ступенчатый конвейер, как и в микроархитектуре К8.
Однако, несмотря на внешнее сходство, новое ядро процессора все же претерпело существенные изменения. Расскажем обо всем по порядку.
Предвыборка данных и инструкций
Напомним, что исполнение кода процессором начинается с процесса выборки инструкций и данных из кэша L1. Однако для того, чтобы инструкции и данные попали в этот кэш, их нужно предварительно туда загрузить из оперативной памяти. Такой процесс, как говорилось ранее, называется предвыборкой данных и инструкций из оперативной памяти.
В процессорах с микроархитектурой К8 имеются два блока предвыборки (Fetch Unit): один для предвыборки данных, а другой — для предвыборки инструкций. Блок предвыборки данных производит предвыборку в кэш L2.
В микроархитектуре AMD К10 предвыборка данных осуществляется непосредственно в кэш L1, что, по утверждению представителей компании AMD, способствует повышению производительности, несмотря на вероятность засорения кэша L1 ненужными данными.
Кроме того, в блоках предвыборки процессоров с микроархитектурой К10 реализован механизм адаптивной предвыборки данных, позволяющий динамически изменять глубину предвыборки, что позволяет избежать засорения кэша L1 ненужными данными.
Ну и последнее новшество, связанное с предвыборкой данных и инструкций, — это, как уже отмечалось, наличие нового блока предвыборки, расположенного в контроллере памяти. Такой блок анализирует запросы к памяти, предсказывает, какие данные понадобятся процессору, и извлекает их в собственный буфер, не занимая кэш процессора.
Выборка из кэша
В процессорах на базе микроархитектуры К8 инструкции из кэша L1 загружаются блоками длиной 16 байт (128 бит), а в микроархитектуре К10 длина блока увеличена вдвое и составляет 32 байта (256 бит). При выборке 16-байтного блока инструкций за такт процессоры на базе микроархитектуры К8 могут выбирать и соответственно отправлять на декодирование до четырех инструкций средней длиной 4 байта.
В принципе, нельзя утверждать, что использование увеличенного вдвое размера блока выборки инструкций в микроархитектуре AMD К10 позволяет выбирать за такт вдвое больше инструкций. Просто в архитектуре AMD К8 длина блока выборки инструкций была согласована с возможностями декодера. В архитектуре AMD К10 возможности декодера изменились, в результате чего потребовалось изменить и размер блока выборки, чтобы темп выборки инструкций был сбалансирован со скоростью работы декодера.
Предсказание переходов и ветвлений
Предсказание переходов в процессорах на базе микроархитектуры К8 осуществляется по адаптивному алгоритму на основе анализа истории восьми предыдущих переходов.
Основным недостатком механизма предсказания переходов в микроархитектуре К8 было отсутствие предсказания косвенных переходов с динамически чередующимися адресами, то есть переходов, которые производятся по указателю, динамически вычисляемому при выполнении кода программы.
В микроархитектуре AMD К10 предсказание переходов существенно улучшено. Во-первых, появился механизм предсказания косвенных переходов. Во-вторых, оно выполняется на основе анализа 12 предыдущих переходов, что повышает точность предсказания. В-третьих, вдвое (с 12 до 24 элементов) увеличена глубина стека возврата.
Процесс декодирования
После этапа выборки инструкций х86 из кэша L1 в полном соответствии со схемой «классического» процессора наступает этап декодирования (трансляции) в машинные команды. Этап декодирования присущ любому современному х86-совмести- мому процессору, имеющему внутреннюю RISC-архитектуру.
Процесс декодирования состоит из двух этапов. На первом этапе выбранные из кэша L1 блоки инструкций длиной 32 байта помещаются в специальный буфер предкодирования Predecode/Pick Buffer. В нем из 32-байтных блоков выделяются отдельные инструкции, которые затем сортируются и распределяются по различным каналам декодера. Декодер транслирует х86-инструкции в простейшие машинные команды (микрооперации), называемые Micro-Ops. Сами х86-команды могут быть переменной длины, а вот длина микроопераций уже фиксированная.
Инструкции х86 делятся на простые и сложные. Простые инструкции при декодировании представляются с помощью одной-двух микроопераций, а сложные — тремя и более микрооперациями. Простые инструкции отсылаются в аппаратный декодер, построенный на логических схемах и называемый DirectPath, а сложные — в микропрограммный декодер, называемый Vector Path. Этот декодер представляет собой своеобразный программный процессор. Он содержит программный код, хранящийся в MIS, на основе которого воспроизводится последовательность микроопераций.
Аппаратный декодер DirectPath является трехканальным и может декодировать за один такт три простые инструкции, если каждая из них транслируется в одну микрооперацию, либо одну простую инструкцию, транслируемую в две микрооперации, и одну простую инструкцию, транслируемую в одну микрооперацию, либо две простые инструкции за два такта, если каждая инструкция транслируется в две микрооперации (полторы инструкции за такт). Таким образом, за каждый такт аппаратный декодер DirectPath выдает три микрооперации.
Микропрограммный декодер VectorPath также способен выдавать по три микрооперации за такт при декодировании сложных инструкций. При этом сложные инструкции не могут декодироваться одновременно с простыми, то есть при работе трехканального аппаратного декодера микропрограммный декодер не используется, а при декодировании сложных инструкций, наоборот, бездействует аппаратный декодер.
Микрооперации, полученные в результате декодирования инструкций в декодерах DirectPath и VectorPath, поступают в Pack Buffer, где они объединяются в группы по три микрооперации. В том случае, когда за один такт в буфер поступает не три, а одна или две микрооперации (в результате задержек с выбором инструкций), группы заполняются пустыми микрооперациями, но так, чтобы в каждой группе было ровно три микрооперации. Далее группы микроинструкций отправляются на исполнение.
Если посмотреть на схему декодера в микроархитектурах К8 и К10, то видимых различий, казалось бы, нет Действительно, принципиальная схема работы декодера осталась без изменений. Разница в данном случае заключается в том, какие инструкции считаются сложными, а какие — простыми, а также в том, как декодируются различные инструкции. Так, в микроархитектуре К8 128-битные SSE-инструкции разбиваются на две микрооперации, а в микроархитектуре К10 большинство SSE-инструкций декодируется в аппаратном декодере как одна микрооперация. Кроме того, часть SSE-инструкций, которые в микроархитектуре К8 декодируются через микропрограммный VectorPath-декодер, в микроархитектуре К10 декодируются через аппаратный Direct Path-декодер.

Декодирование команд в микроархитектурах К8 и К10
Кроме того, в микроархитектуре К10 в декодер добавлен специальный блок, называемый Sideband Stack Optimizer. Не вникая в подробности, отметим, что он повышает эффективность декодирования инструкций работы со стеком и позволяет переупорядочить микрооперации, получаемые в результате декодирования, чтобы они могли выполняться параллельно.
Диспетчеризация и переупорядочение микроопераций
После прохождения декодера микрооперации (по три за каждый такт) поступают в блок управления командами, называемый Instruction Control Unit (ICU). Главная задача ICU заключается в диспетчеризации трех микроопераций за такт по функциональным устройствам, то есть ICU распределяет инструкции в зависимости от их назначения. Для этого используется буфер переупорядочения (ROB), который рассчитан на хранение 72 микроопераций (24 линии по три микрооперации).
Каждая группа из трех микроопераций записывается в свою линию. Из буфера переупорядочения микрооперации поступают в очереди планировщиков целочисленных (Int. Scheduler) и вещественных (FPU Scheduler) исполнительных устройств в том порядке, в котором они вышли из декодера.
Выполнение микроопераций
После того как все микрооперации прошли диспетчеризацию и переупорядочение в определенных планировщиках, они могут быть выполнены в соответствующих исполнительных устройствах.
Блок операций с целыми числами состоит из трех распараллеленных частей. По мере готовности данных планировщик может запускать на исполнение из каждой очереди одну целочисленную операцию в устройство ALU и одну адресную операцию в устройство AGU. Количество одновременных обращений к памяти ограничено двумя. Таким образом, за каждый такт может запускаться на исполнение три целочисленные операции, обрабатываемые в устройствах ALU, и две операции с памятью, обрабатываемые в устройствах AGU.
Отметим, что в микроархитектуре К8 при выполнении операций с памятью имеется одно существенное ограничение. Дело в том, что операции обращения к памяти должны идти в том виде, в котором они записаны в коде программы, то есть более поздние в программе операции обращения к памяти не могут выполняться перед более ранними. Понятно, что такое ограничение может существенно отразится на эффективности выполнения программного кода, поскольку нередко блокирует выполнение программы на несколько тактов.
В микроархитектуре К10 такого ограничения не существует, то есть имеется возможность выполнения команды обращения к памяти вне очереди.
Как уже отмечалось, для работы с вещественными числами реализованы три функциональных устройства FPU: FADD — для вещественного сложения, FMUL — для вещественного умножения и FMISC (он же FSTORE) — для команд сохранения в памяти и вспомогательных операций преобразования.
В микроархитектурах К8 и К10 планировщик для работы с вещественными числами каждый такт может запускать на исполнение по одной операции в каждое функциональное устройство FPU. Подобная реализация блока FPU теоретически позволяет выполнять до трех вещественных операций за такт.
В микроархитектуре К8 устройства FPU являются 64-битными. Векторные 128-битные SSE-команды разбиваются на этапе декодирования на две микрооперации, которые производят операции над 64-битными половинами 128-битного операнда и Запускаются на исполнение последовательно в разных тактах.
В микроархитектуре К10 устройства FPU являются 128-битными. Соответственно 128-битные SSE-команды обрабатываются с помощью одной микрооперации, что теоретически увеличивает темп выполнения векторных SSE-команд в два раза по сравнению с микроархитектурой К8.
Технологии энергосбережения
Кроме существенных улучшений в процессе выполнения программного кода, в микроархитектуре AMD К10 предусмотрены и новые технологии энергосбережения, позволяющие существенно повысить оптимизированную производительность процессора, то есть производительность в расчет на ватт потребляемой энергии. В частности, в микроархитектуре К10 реализованы такие технологии, как CoolCore, Independent Dynamic Core и Dual Dynamic Power Management (DDPM).
Технология CoolCore дает возможность автоматически выключать те части (цепи) процессора, которые в данный момент не используются. В результате достигается снижение энергопотребления и соответственно тепловыделения процессора.
Технология Independent Dynamic Core позволяет каждому ядру процессора работать на собственной тактовой частоте, то есть предусмотрено динамическое (в зависимости от текущей загрузки) и независимое изменение тактовой частоты каждого ядра процессора. В Independent Dynamic Core предусмотрено пять энергетических уровней, что дает существенную экономию энергопотребления. Правда, данная технология позволяет динамически изменять только частоту ядра каждого процессора, но не напряжение питания. Напряжение питания всех ядер процессора одинаковое и определяется напряжением питания того ядра, которое функционирует на максимальной тактовой частоте.
Технология Dual Dynamic Power Management (DDPM) подразумевает применение двух различных линий для питания ядер процессора и контроллера памяти. Это позволяет не привязывать частоту работы контроллера памяти к частоте работы ядер процессора. Отметим, что технология DDPM реализуется только при использовании разъема Socket АМ2+, поскольку в разъемах Socket АМ2 предусмотрена единая линия для питания процессора и контроллера памяти.
Шина HyperTransport 3.0
В новых процессорах AMD для ПК (Phenom FX, Х4, ХЗ и Х2) предусмотрено применение новой шины HyperTransport 3.0 вместо 1.x. Правда, в серверных процессорах Opteron на базе микроархитектуры AMD К10 еще некоторое время будет использоваться шина HyperTransport 1.x, но в будущем в них также будет реализована поддержка HyperTransport 3.0.
Шина HyperTransport является двунаправленной и служит для обмена данными между процессором и компонентами системы. Первые ее версии работали на частоте 800 и 1000 МГц, что обеспечивало пропускную способность 6,4 и 8 Гбайт/с соответственно.
Шина HyperTransport 3.0 имеет динамическую рабочую частоту, которая зависит от тактовой частоты процессора. Связь между тактовой частотой процессора и частотой шины HyperTransport определяется коэффициентом пропорциональности ¾. К примеру, если тактовая частота процессора составляет 2 ГГц, то частота шины HyperTransport 3.0 — 1,5 ГГц.
Максимальная частота шины HyperTransport 3.0 равна 2,6 ГГц, что соответствует тактовой частоте процессора 3,5 ГГц.
Кроме более высоких тактовых частот, шина HyperTransport 3.0 поддерживает режим динамической переконфигурации. Например, в процессе работы шина 1×16 HyperTransport может быть виртуально переконфигурирована в 2×8 HyperTransport. Это может пригодиться при использовании с многоядерными процессорами, когда каждому ядру будет отводиться своя шина HyperTransport.
dammlab.com
Архитектура AMD Bulldozer. Структура процессора
AMD решила использовать совершенно другой подход для новой архитектуры Bulldozer. Было решено создать двухядерные модули, которые вместе используют некоторые ресурсы (L2 кэш-память, модуль вычислений с плавающей запятой), но не являются полностью независимыми друг от друга. (смотрите рисунок ниже)
По словам AMD это было сделано в целях оптимизации процессора и в то же время для уменьшения цены процессора. Оптимизация заключается в том, что на обычных многоядерных процессорах, некоторые модули могут бездействовать, и такие модули могут быть объединены в архитектуре Bulldozer. А если будет меньше модулей — значит, будет меньше потрачено материала, а это, в свою очередь, позитивно повлияет на стоимость, на экономию энергии и на уменьшение количества тепла.
Поэтому, хоть AMD и будет называть свои новые процессоры на архитектуре Bulldozer двухъядерными, на самом деле они не будут истинно двухъядерными, поскольку у них не будет полностью независимых ядер. А название «двухядерный процессор» будет использоваться в маркетинговых целях.
Для создания «четырехъядерных процессоров«, AMD использует два таких блока, так что процессор фактически имеет два «процессора» внутри (два стандартных блоков указаны на рисунке ниже), а не четыре. AMD по-прежнему будет называть новые процессоры четырехядерными.
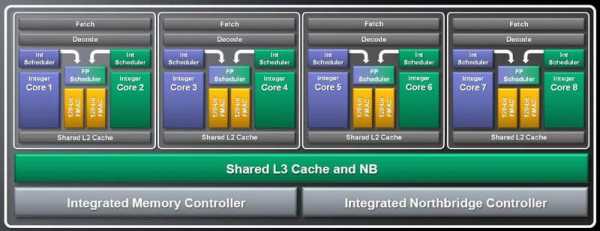
Восемиядерный процессор на архитектуре Bulldozer.
Теперь давайте подробно рассмотрим модули Fetch и Decode, используемые в архитектуре Bulldozer.
Модули Fetch и Decode
Модуль выборки Fetch отвечает за получение инструкций для декодирования из кэш памяти или из оперативной памяти.
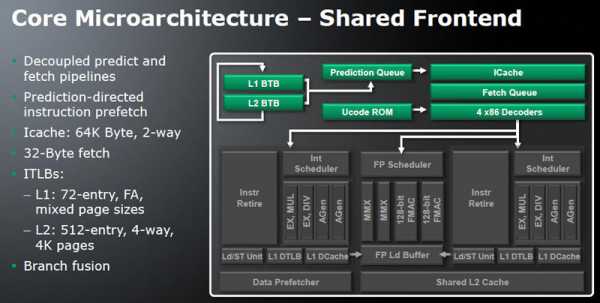
Модули Fetch и Decode.
Как уже было замечено, модули выборки используют сразу два «ядра». Кэш инструкции L1 также используются двумя ядрами одновременно, но каждое процессорное ядро имеет свою собственную кэш данных L1.
AMD уже анонсировала, что кэш инструкции L1, используемые в архитектуре Bulldozer, состоят из двухканального множественно-ассоциативного кэша объемом 64 Кб. Та же конфигурация используются в процессорах с архитектурой AMD64, но с разницей, что процессоры AMD64 имеют кэш-памяти L1 на каждое ядро, а процессоры Bulldozer будут иметь одну кэш-памяти L1 на каждую пару ядер. Однако, кэш данных будет иметь только 16 КБ, что значительно меньше, чем 64 КБ для каждого ядра, которые используются в процессорах на основе архитектуры AMD64.
TLBs (Translation Look-aside Buffer — буфер сверхбыстрой памяти). Размеры TLBs были раскрыты. Это буферы, с небольшим объемом памяти, предназначенные для преобразования виртуальных адресов памяти, в физические адреса.
Виртуальная память, больше известная как файл подкачки, это технология, где объем оперативной памяти «увеличивается» за счет специального файла на жестком диске.
Программы для компьютера пишутся с использованием инструкций x86, но в настоящее время процессоры понимают только собственные RISC инструкции. Модуль декодирования отвечает за преобразование x86 инструкций программ, в RISC микрокоманды. Архитектура Bulldozer имеет четыре декодера, но в данный момент AMD не раскрывает информацию о том, какие инструкции выполняет каждый декодер. Обычно один из этих декодеров выполняет сложные комплексные инструкции, используя предоставленный микрокод ROM (“µcode” или «microcode»). Декодирование сложных инструкций завершается через несколько тактов, после чего они преобразовываются в несколько микрокоманд. Обычно производители оптимизируют свои процессоры таким образом, что при декодировании наиболее распространенных инструкций — они выполнялись всего за один такт.
Архитектура AMD Bulldozer. Инструкции
Архитектура AMD Bulldozer. Модули вычисления
Архитектура AMD Bulldozer. Структура процессора
hardwareguide.ru